

很长一段时间以来,我们一直依赖空间图像,虽然这已经带来了数百万的好处,但它有一个小小的限制,那就是它不能在我们的现实世界中自我解释,而现实世界在最近的复杂应用中是必不可少的,比如伊隆马斯克汽车、杰夫的机器人,甚至波士顿的斑点狗。因此,现在是时候向前看一些其他的东西了,一些更先进和更合适的东西。当我坐在那里沉思时,我内心的声音回荡了两三次,说“增加维度”。我不抱怨这一点,因为这就是我们做机器学习的正确方式。
事实上,有人真的想过了,以一种非典型的方式增加了空间形象的维度。我认为“尺寸”这个词不合适,他们把每个物体离相机有多远的信息编码为像素值,单位是米或英寸,我们也可以给它起个名字。该图像是具有‘x,y’轴的二维图像,并且像素值表示第三维,即‘z’轴。
有专门为此设计的立体相机,有两个镜头并排在一起,就像人眼一样。但是,我们世界上的大多数相机都是由一个镜头组成的,所以我们会在软件方面解决这个问题,更准确地说,我们会模仿立体相机的功能。而且,人工智能在这方面做得非常好。
我们的主要任务是从RGB图像创建一个类似于立体相机生成的深度图。这是一个活跃的研究领域,每年都有100多篇论文发表,本文的重点是“基于迁移学习的高质量单目深度估计”这篇论文。本文采用简单而强大的深层体系结构“U-Net”来完成这项任务,部分体系结构是由在ImageNet数据库上训练的“DenseNet-169”构成的。我们将重现本文提出的方法论,并建立一个实验,并通过实验观察其产生的结果。High Quality Monocular Depth Estimation via Transfer Learning
本文的范围是详细讨论该系统的数据管道、模型体系结构和培训管道三个主要部分。另外,为了获得最好的体验和乐趣,我建议在这些Kaggle或Colab笔记本上运行电池。Kaggle Colab
数据管道:
我们将使用在他们的官方论文中使用的NYU-Depth-V2数据集,该数据集由在深度估计问题的上下文中最好地描述对象的室内场景组成。我们不是看图像中的某个对象,而是更关注对象在图像中的位置,就像在整个场景中一样。因此,这个数据集由卧室、厨房、自习室、办公室等不同房间的视频帧组成。样本图像对将如下所示,
这个数据集只包含室内图像,您注意到我之前提到过“看透结果”吗?架构将被训练,其推广能力将通过室外视频进行评估,因为为什么NI会想到在这个室内数据集中训练架构,并通过传递室外图像或视频来评估其推广能力,这是为什么不呢?!
一些数据集统计数据包括,包含50688对用于训练的数据,其中我们将其拆分为80:20用于验证,并保留了一组640对用于测试。本文提出保留形状为640×480的RGB图像和形状为320×240的深度图。我们将配对归一化为在{0,1}范围内,并通过0.5概率的水平翻转来增加配对。
本文建议使用批大小为8的自定义数据生成器类为图像生成形状为(8,480,640,3)的数据元组,为深度图生成(8,240,320,1)形状的数据元组。
模型架构:
本文首次提出了U-网用于医学图像中的异常定位。它具有像素级定位能力,并能区分独特的模式。它看起来像一个“U”字形结构,我们称一部分是编码器,另一部分是解码器,解码器的每个挡路通过跳过连接连接到编码器对应的挡路。这有助于它比传统的同行拥有更多的潜在空间,也就是说,它使用来自输入空间的信息及其所有中间表示将样本映射到某个定义明确的潜在空间,然后计算来自该空间的输出。这些跳跃连接在许多研究中得到了实验验证,以解决退化问题。paper degradation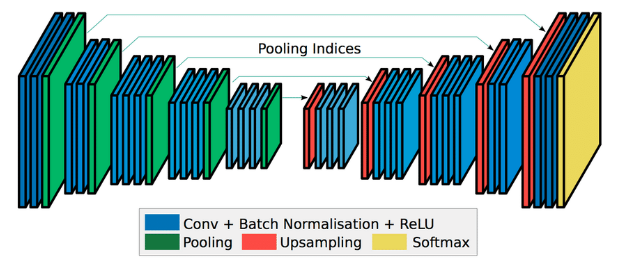
在本文中,我们使用“DenseNet-169”架构作为具有预先训练权重的编码器,对于解码器,我们将从输出通道数与截断编码器的输出相同的1×1卷积层和4个上采样块开始,每个上采样块包括一个双线性上采样层,然后是两个3×3卷积层,输出滤波器设置为输入滤波器数量的一半。并且,编码器的池层输出与每个挡路的上采样层输出级联。最后,每个卷积层都具有批归一化层,并且除了最后一个外,每个上采样挡路后面都跟随有泄漏的REU激活函数。
我们有一个更深层次的架构,它的最后一个编码层包含1664个功能地图。在配备V100 GPU和25 GB RAM的CoLab PRO实例中,每个纪元大约需要60分钟。对于不超过512层的较小架构,我建议您参考此repo中的实现。在对这两种体系结构进行实验时,它显示出训练和验证度量在某种程度上是相似的,但实际上在模型的泛化能力上有所不同。在With-Hold测试集中,越深的模型执行得更好,准确率提高了10%,而且深度图也更清晰。repo
培训渠道:
我从这个问题的结果的重要决定因素–损失函数开始。我们采用文中提出的自定义损失函数,将灰度绘制的地面实况图与预测图的结构相似度三个度量结合起来,以0.5为阈值计算Sobel梯度操作图的F1得分,并计算地面实况图与预测图之间的余弦距离。通过这样做,我们使网络能够学习地图的内部关系和内部关系,同时保持强而锐利的边缘。
我们将使用ADAM优化器,权重衰减率为1e-6,起始学习率为0.0001,多项式衰减率,以及一些检查点来跟踪它。最后,我们将使整个编码层都是可训练的,并使用著名的model.fit()开始10个时期的训练。现在,向后倾,享受那些随着进度条向右推的漂亮数字的变化,也可能是用爆米花!
经过大约12个小时的培训,我获得了大约95%的验证和85%的测试集准确率。通过查看测试集预测,我可以看到这些
边缘锋利而紧凑,相当不错。另外,就像刚才说的,我把在外面环境下拍摄的视频传了进去,得到了一些类似的东西,
我们立刻就能注意到框架之间的闪烁。这是因为这个模型是为单张图像的预测而设计的,所以我对图像中的每一帧运行了该模型,并将结果组合在一起。帧之间会有一些预测差异。为了实现更平滑的过渡,我们必须查看将时域考虑在内的模型。
该代码可在Colab或Kaggle平台获得。一些参考资料包括正式文件及其执行情况。Colab Kaggle paper implementation
感谢您抽出时间来参观这条线路。:)
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/13/%e5%9f%ba%e4%ba%8eu%e7%bd%91%e7%9a%84%e5%8d%95%e7%9b%ae%e6%b7%b1%e5%ba%a6%e4%bc%b0%e8%ae%a1/
