
方法
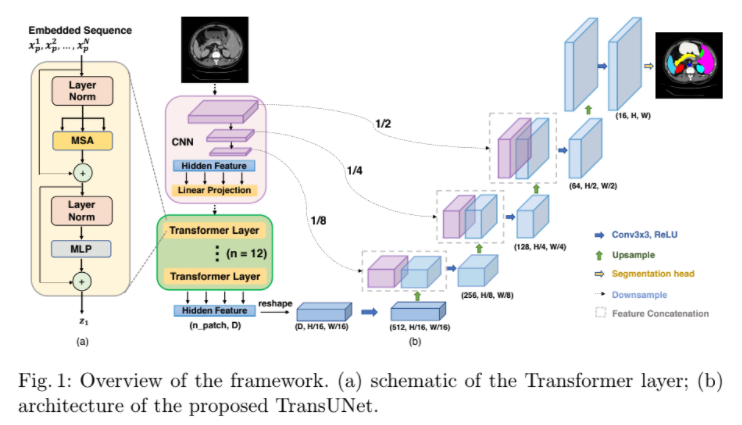
- 此篇基於Vit及UNET做醫學影像的語意分割、Vit的部分和原始Vit論文作法一模一樣,且有嘗試將Vit的Output使用單純的BbilinEarly Up Sample輸出N個Channel(CLASS)的分段、但因為Vit的H/P*W/P通常比原始影像的H*W小很多,所以效果不會太好,因此作者提出混合的有线电视新闻网-变压器來補足低级详细信息、利用CNN取出功能地图然後當作Vit的Input,架構上也和UNET一樣使用了跳过连接,並透過網路的方式做UPSAMPLE。
实验
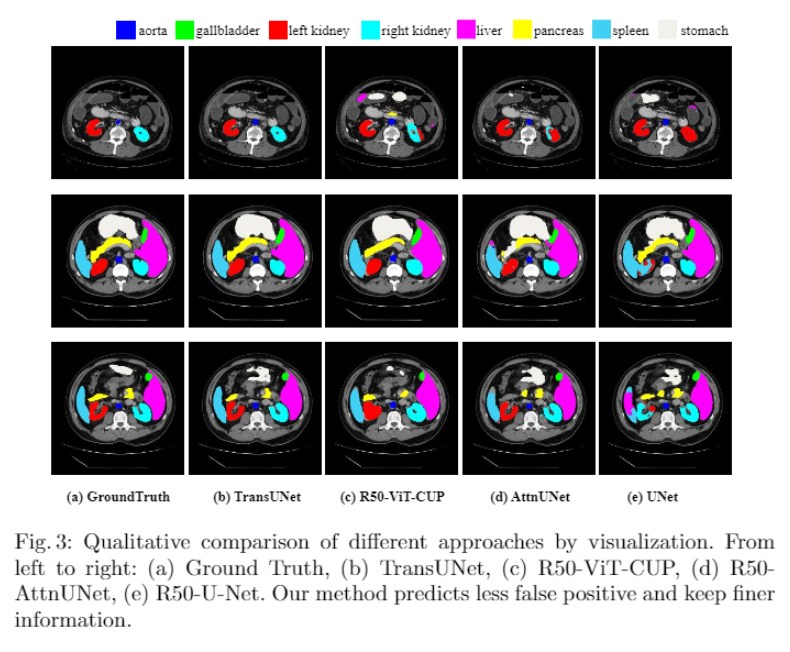
突触多器官分割数据集
- 上半部比較SOTA的模型,下半部做烧蚀研究,None的解码器表示使用一般的双线性上采样,Hausdorff距离是指兩個集合若是要彼此包含的話所需要的最短距離。

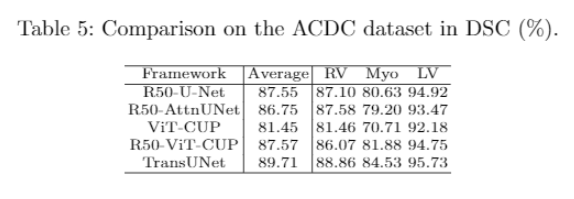
ACDC数据集
跳过连接数

输入分辨率

序列长度和补丁大小

模型缩放

- 基本上這篇就是把原始Vit加上UNET架構而已,並沒有太多的改變和實驗,但根據其他論文和此篇論文可以看出在Vit之前加上卷积的效果都還不錯。
参考文献
[arxiv][arxiv]
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/19/transunet%ef%bc%9a%e5%8f%98%e5%8e%8b%e5%99%a8%e4%b8%ba%e5%8c%bb%e5%ad%a6%e5%9b%be%e5%83%8f%e5%88%86%e5%89%b2%e6%8f%90%e4%be%9b%e5%bc%ba%e5%a4%a7%e7%9a%84%e7%bc%96%e7%a0%81%e5%99%a8/
