
我在海得拉巴国际信息技术研究所(IIITH)的Ravikiran Sarvadevabhatla博士手下从事行动认可工作。我的工作是使用Pytorch几何库实现基于骨架的动作识别的时空图卷积网络(STGCN)这一研究论文。我使用的数据集是NTU-60数据集(使用的操作类是A1-A60)。Dr.Ravikiran Sarvadevabhatla Spatial-Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition Pytorch Geometric NTU-60
NTU-60数据集将人体骨骼建模为一组25个关节,每个关节具有3个值(x,y,z)来表示空间信息。执行动作时,25个关节的值随时间变化。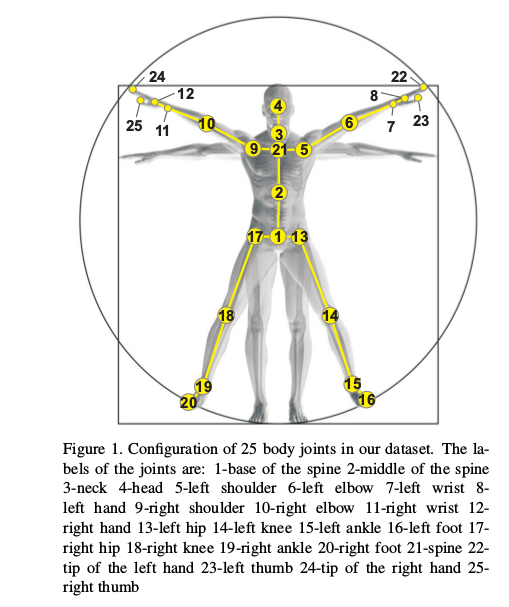
STGCN代码旨在针对每个时间帧(空间卷积)捕捉这些特征值如何在空间上变化(即,对于给定关节,其连接的关节的值如何变化),以及每个关节的值如何在时间帧(时间卷积)上变化,以将视频分类为特定动作。网络的输入是连接值,并且在最终分类层之前通过多个STGCN块(即,执行空间和时间卷积的块)。在通过每个挡路之后,生成更高级别的特征地图(即,对于每个关节,值的数量增加)。STGCN code
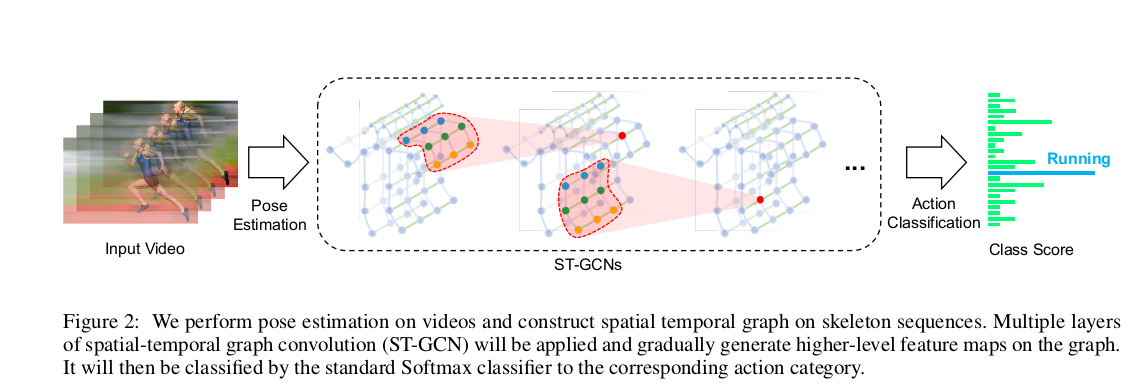
由于数据是以批处理方式处理的,因此数据在传递到网络之前具有以下形状:N x C x T x V x M,其中:
N:批次大小,C:通道/要素数量(从3开始),T:时间范围数量,V:顶点数量(始终为25),M:时间范围内出现的人数。
为了批量播放不同的视频,视频的大小必须一致。但数据集包含的视频具有不同的时间框架和不同的人数(1人或2人)。为了确保统一的尺寸,视频用0填充,这样数据集中的时间帧数是300,每帧中的人数是2(如果帧有一个人,则复制它,使得关节的特征值对于第二个人来说是0)。现在传递到网络的数据具有以下维度:N x C x 300 x V x 2。
数据在通过第一个STGCN挡路之前被重塑为N*2xCxTxV。
STGCN代码使用nn.Conv2d包进行空间和时间卷积。对于空间卷积,使用邻接矩阵的概念来确定骨架中存在的邻域,并在给定的时间帧内对空间特征进行卷积以生成新的空间特征地图。对于时间卷积,使用的核大小为(9,1),即它捕获9个时间帧上每个关节的特征值,并被卷积为单个特征。nn.Conv2d spatial convolution adjacency matrix temporal convolution
在此方法中,必须填充输入数据以执行批处理和卷积,这意味着消耗更多空间,并对填充的数据(填充为0)执行不必要的卷积。
为了避免使用填充,我尝试使用Pytorch几何库重写相同的代码。
Pytorch几何库提供了在不规则数据结构上实现深度学习网络的各种方法。我用于图形卷积的包是GCNConv。Pytorch Geometry允许对节点数量可变但要素数量相同的图形进行批处理。为了更好地利用这一点,我将NTU 60数据集视为一组图形。这些图具有不同数量的时间节点,但特征保持不变。GCNConv batching
图形的形状为T x V x C(T:时间节点,V:顶点,C:通道数)。批大小为5意味着将5个图作为单个断开的图一起批处理,其中值T将是每个图的时间节点的数目之和。
这也解决了两个人所需的填充问题,方法是将每个人视为一个图,并将其批处理为一个断开的图。
下面的图4表示一个玩具数据集,以显示如何将图形批处理在一起。在该数据集中,顶点数(V)固定为4,特征数(C)固定为3。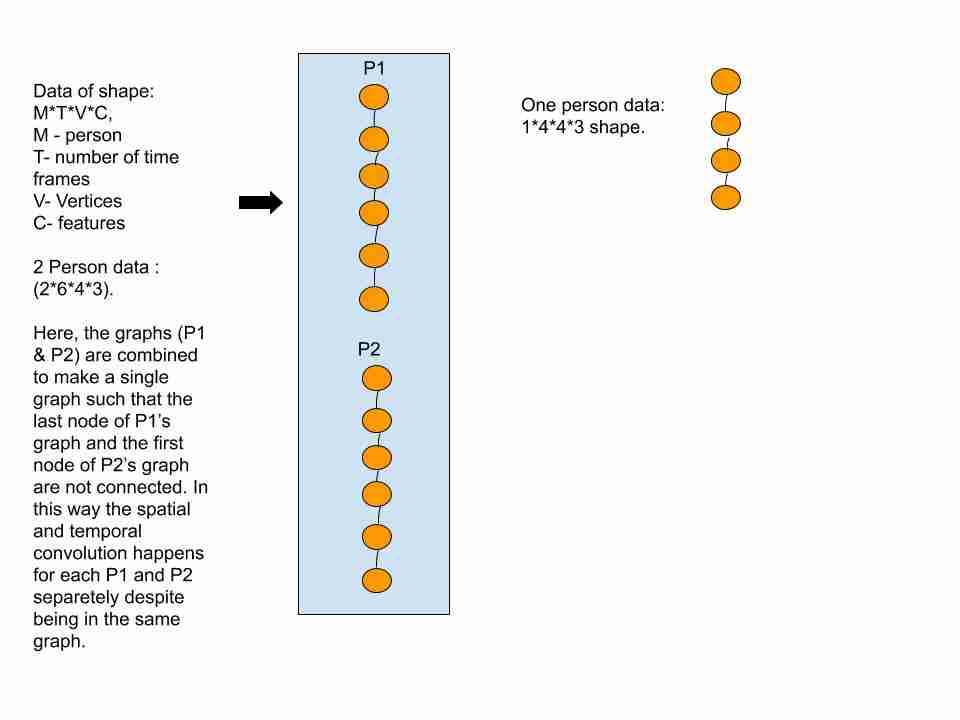
在处理数据之后,图形通过STGCN块并通过最终分类层。由于Pytorch STGCN代码的数据格式不同,因此还必须对批处理标准化进行编码,以使其等同于原始的1-D、2-D批处理标准化。下面给出了这两种架构。processing the data STGCN blocks batch normalization
显示了原始STGCN代码和Pytorch几何代码的曲线图。
可以看出,原始STGCN代码的验证准确率约为78%,基于Pytorch几何的STGCN代码的验证准确率约为58%。尽管这两个码在概念上都执行空间和时间卷积,但卷积模块中涉及的参数数量是不同的。
在Conv2d包中,如果核大小给定为(9,1),则卷积运算的可学习参数的数量将是[9 x输入特征数x输出特征数]。除此之外,它还意味着在给定的数据点上,该数据点两边的4个邻居的特征是卷积的,即给定的数据点有8个邻居。
要使用GCNConv包执行等效操作,需要预先定义邻接矩阵,以使任意节点具有8个节点的邻居。图的基本卷积运算是归一化邻接矩阵、图、可学习权重矩阵的乘积。权重矩阵的形状为[输入特征数x输出特征数]。这意味着,虽然邻接矩阵照顾邻居,但是每个STGCN操作的可学习运算符的数量减少了9倍(即核大小)。邻域特征均匀呈现。这种类型的核称为各向同性核。
如果内核不是像SplineConv包使用的那样的各向同性内核,那么精确度可以提高。但是,SplineConv包只能容纳具有二维形状的图形,而我们的图形形状是三维的。如果一个图形包可以容纳三维图形,并且具有各向同性的核,那么我相信不使用填充数据就可以达到更高的精度。SplineConv
链接到Pytorch几何repository:https://github.com/hariharannatesh/Action-Recognition-using-Pytorch-Geometrichttps://github.com/hariharannatesh/Action-Recognition-using-Pytorch-Geometric
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/20/%e5%9f%ba%e4%ba%8epytorch%e5%87%a0%e4%bd%95%e7%9a%84%e5%8a%a8%e4%bd%9c%e8%af%86%e5%88%ab/
