
内容包括:
a)自定义数据集:
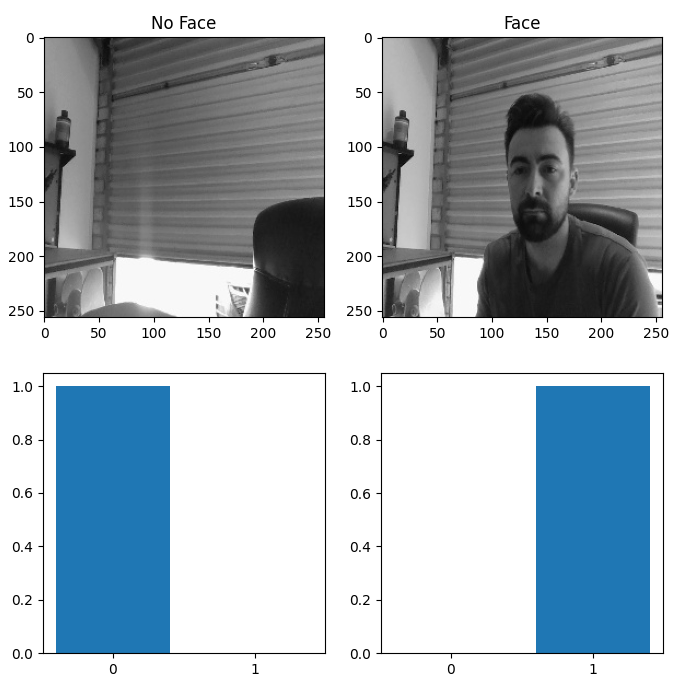
我有一个相机来识别我的脸,我遇到的第一个问题是收集数据。我想使用PyTorch的内置DataSet()类并利用所有这些基础设施,但不知道如何使用…
所以,首先我用开放式计算机视觉收集了一些数据。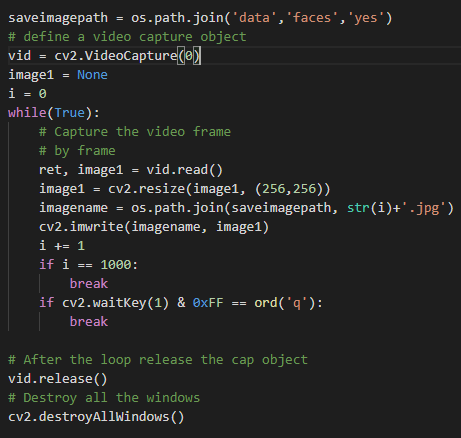
上面是一个小的一次性脚本,用来捕捉网络摄像头上的数据,这是我在拍摄过程中的样子,作为一个gif…
因此,要使用PyTorch数据集类,您只需编写一个继承自DataSet并实现__len__和__getitem__…的类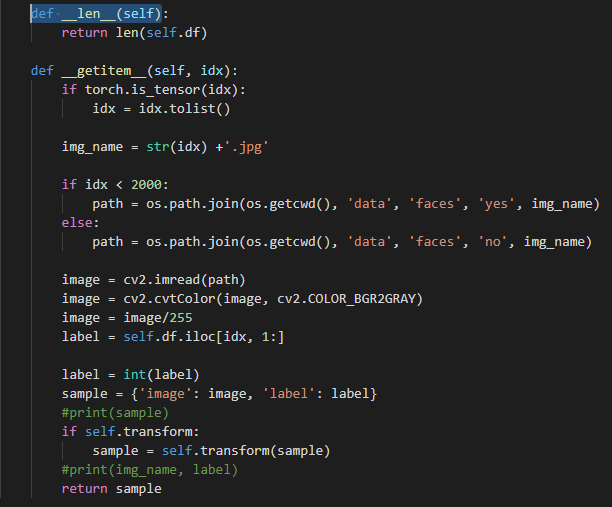
数据集和__init__如下所示:
总之,您的自定义数据集应该从PyTorch DataSet类继承,并且您应该实现__len__和__getitem__,这样您的类就可以为您的数据集执行该操作,这将由命名约定、文件夹结构和您试图用作数据集的底层数据决定。
b)变换和变换。Compose():
“转换”是对数据的操作。例如:
对数据执行转换以帮助我们的神经网络泛化其预测能力称为数据增强,如果您一开始没有大量数据,它会特别有帮助。或者,根据您试图预测的…,您可能会混淆您的神经网络
Transforms.Compose()是一种可以用来一个接一个地执行转换的方法。例如,在我的示例中,通过将图像从3x480x640重新缩放到1x256x256,我已经转换了数据(我的脸的图像和没有我的脸的图像)。这将获取我们的彩色图像,并给我们一个比以前更小的灰度图像(不会丢失太多的分辨率,这是神经网络学习所需要的)。我还使用了一个名为To张量的转换,我们需要它来将图像信息传递给PyTorch。
现在我们可以定义我们的数据了:
c)数据加载器
如果你在这里,你的坚持不懈令人印象深刻。所有使用PyTorch的基础设施实现自定义数据集的努力在DataLoader开始得到回报,在这里我们可以告诉PyTorch我们希望使用的数据集,…_SIZE,我们甚至可以做一些更多的调整,以确保我们的数据真的不是按批处理排序的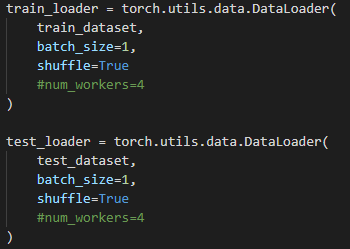
DataLoader为我们提供了一个迭代器,因此我们可以在训练和测试循环期间迭代它。
2.AlexNet和迁移学习:
有关阿列克谢网络的一些信息,请点击此处:https://en.wikipedia.org/wiki/AlexNet。https://en.wikipedia.org/wiki/AlexNet
a)Alexnet vs Alexnet1(Alexnet I最终使用此处…的版本)
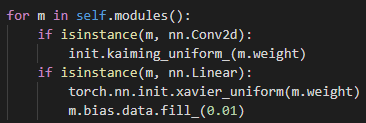
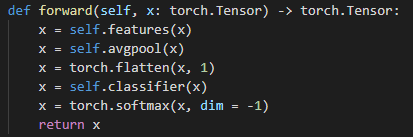
b)迁移学习:
想象一下,我们有一个神经网络,我们想让它学习如何对爬行动物进行分类。其他一些神经网络的人已经训练他们的网络来对动物进行分类。转移学习是这样一种想法,即我们可以使用他们已经训练好的网络作为我们自己的初始权重和偏差,然后添加一个(或多个)分类层,并且只训练最后一层来执行我们的分类任务。这个特别的例子可能吗?可能吧,是我做的吗?不是的。
如果这些权重和偏差来自Pytorch…,下面是它看起来的样子![]()
如果它们来自文件…,则如下所示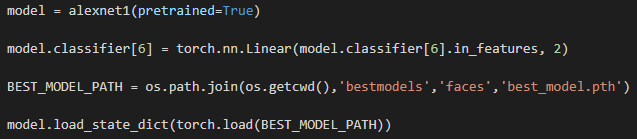
如果你想知道这是怎么回事,我们可能会知道我们应该在model实现客户层。分类器[6],有几个人已经做过关于AlexNet的教程。或者,我发现查看源代码更有用。如果您安装了Torchvision,您应该可以在以下位置找到它:
.\Lib\site-packages\torchvision\models\alexnet,至少在Windows…上
3.培训和评估
a)优化器,损失函数
正如我已经提到的,我使用了二进制交叉熵损失(这是一个二进制分类任务),为了做到这一点,我必须在正向传递中包括Softmax,它基本上是根据先前线性层的输出计算概率。我还发现我需要编写一个小函数来将我的标签转换为单热点向量https://en.wikipedia.org/wiki/One-hot,,这样二进制交叉熵函数就可以计算损失。https://en.wikipedia.org/wiki/One-hot
下面是一个肮脏的小函数: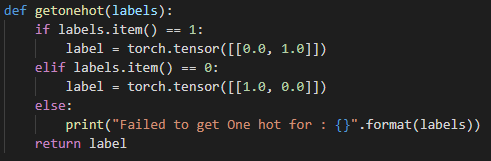


对于优化器,我坚持使用老式的、但很好的、经典的随机梯度下降。在其他人可能会被加快融合时间的承诺所诱惑的地方,我没有动摇,也许这对我自己来说是有害的。在任何情况下,至少在这种情况下,这并不重要,因为SGD已经设法收敛了。
b)一些结果
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/20/%e8%bf%81%e7%a7%bb%e5%ad%a6%e4%b9%a0%e4%b8%8e%e4%ba%8c%e5%85%83%e5%88%86%e7%b1%bb/
