
YOLO:你只看一次(2015)
相对于其他检测器的改进
- 它将目标检测重新定义为一个单一的回归问题,直接从图像像素到边界框坐标和类别概率(没有区域建议)。没有复杂的管道,它非常快。
- 与滑动窗口和基于区域建议的技术不同,它在进行预测时对图像进行全局推理。
- 它学习对象的可概括表示,并且在应用于新域或意外输入时不太可能出现故障。
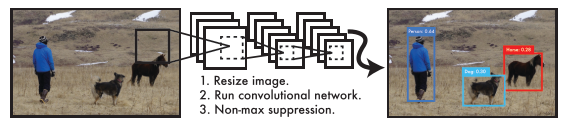
- (1)调整输入图像大小至448×448。
- (2)在图像上运行单个卷积网络。
- (3)根据模型的置信度对检测结果进行阈值。
YOLO:系统概述
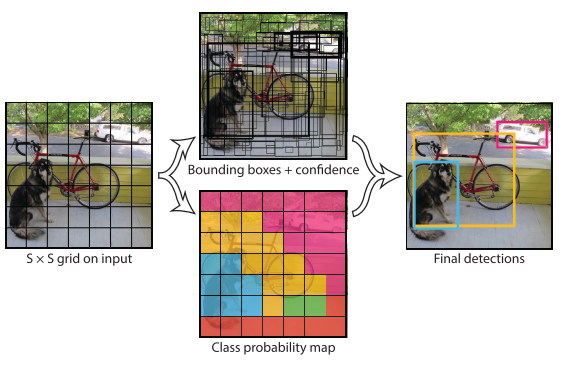
系统将图像划分为S×S网格。如果对象的中心落入网格单元,则该网格单元负责检测该对象。对于每个栅格单元格,它预测:
- B边界框,每个边界框由5个预测组成:(1)4个框坐标:(x,y)坐标表示框相对于网格单元边界的中心。宽度和高度是相对于整个图像进行预测的。(2)1置信度=Pr(对象)∗IOU(TRUE_PRED)。如果该单元格中不存在任何对象,则应为零。否则,它应该等于预测框和地面事实之间的借条。它反映了模型对长方体包含对象的确信程度,以及它认为长方体预测的精确度有多高。
- C条件类概率:PR(Class_i|Object)。这些概率以包含对象的网格单元为条件。无论框B的数量如何,每个网格单元只预测一组类别概率。
这些预测被编码为S×S×(B∗5+C)张量。例如,对于Pascal VOC,S=7,B=2,C=20,因此最终的预测是7×7×30张量。该网络使用整个图像中的要素来进行预测。因此,它对整个图像和图像中的所有对象进行全局推理。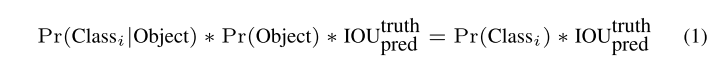
在测试时,每个盒子的特定于班级的置信度分数按照LHS所示进行计算。这些分数既编码了该类出现在框中的概率,也编码了预测框与对象的匹配程度。
美国有线电视新闻网与有监督的前期培训
该检测网络具有24个卷积层,紧随其后的是2个完全连接的层。在ImageNet分类任务中,以一半分辨率(224×224输入图像)对前20个卷积层(随后是平均汇集层和完全连接层)进行预训练。
侦察训练
为了执行检测,添加了具有随机初始化权重的四个卷积层和两个全连通层。此外,由于检测通常需要细粒度的视觉信息,因此输入分辨率提高了一倍(从224×224增加到448×448)。
最后一层预测类概率和边界框坐标。边界框宽度和高度由图像宽度和高度标准化,因此它们介于0和1之间。边界框x和y坐标被参数化为特定网格单元格位置的偏移量,因此它们也在0和1之间。
最后一层使用线性激活函数,而所有其他层使用泄漏REU:F(X)=1(x<0)(αx)+1(x≥0)(X),其中α=0.1.
虽然YOLO预测每个网格单元有多个边界框,但在训练时,每个对象只有一个边界框预测器。如果一个对象具有与地面事实最高的当前借据,则指定一个预测器来“负责”预测该对象。这导致了边界框预测值之间的专门化。每个预测器都能更好地预测对象的特定大小、纵横比或类别,从而提高整体召回率。在训练期间,优化多部分损耗:
这里使用和平方误差,因为它很容易优化。使用两个参数λ_COORD和λ_NOOBJ来控制不同部分的权重。作者通过设置λ_COORD=5和λ_NOOBJ=0.5来增加定位造成的损失,减少不包含对象的盒子分类造成的损失。因为在每幅图像中,许多网格单元不包含任何对象,它们的“置信度”分数会被推向零,通常会压倒这些单元的梯度。此外,由于大盒子中的小偏差应该比小盒子中的小偏差要小,因此预测了包围盒的宽度和高度的平方根。
请注意,损失函数仅在该网格单元中存在对象时惩罚分类错误。如果预测器对地面真值框“负责”(即,在该网格单元中具有任何预测器中最高的IOU),则它也仅惩罚边界框坐标错误。
缺点
- 它对边界框预测施加了很强的空间约束,因为每个网格单元只能预测B个框,并且只能有一个类。此空间约束限制了模型可以预测的附近对象的数量。
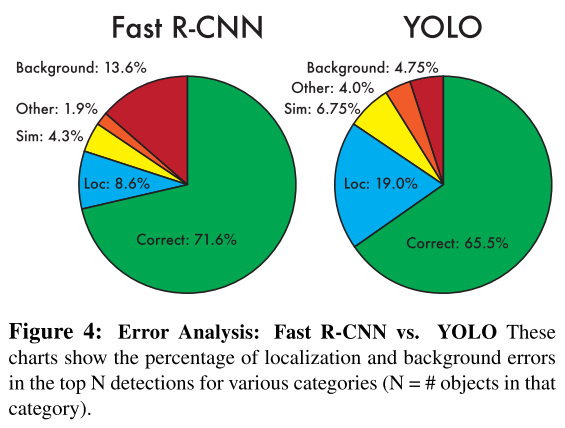
- 它与成群出现的小物体搏斗,比如成群的鸟。
- 它很难推广到新的或不寻常的长宽比或配置中的对象,因为它学会了从数据中预测边界框。
- 它使用相对粗糙的特征来预测边界框,因为该体系结构具有来自输入图像的多个下采样层。
- Lost函数将小边界框中的错误与大边界框中的错误进行相同的处理。
SSD:单次拍摄多盒探测器(2015)
- SSD是一款适用于多个类别的单次拍摄检测器,比YOLO更快、更准确。
- 事实上,它与执行显式区域建议和合并的较慢技术一样准确(包括较快的R-CNN)。
固态硬盘:系统概述
与YOLO类似,SSD方法基于前馈卷积网络。早期的网络层(基础网络)基于用于高质量图像分类的标准体系结构(在任何分类层之前被截断)。为了执行检测,引入了具有以下关键特征的辅助结构: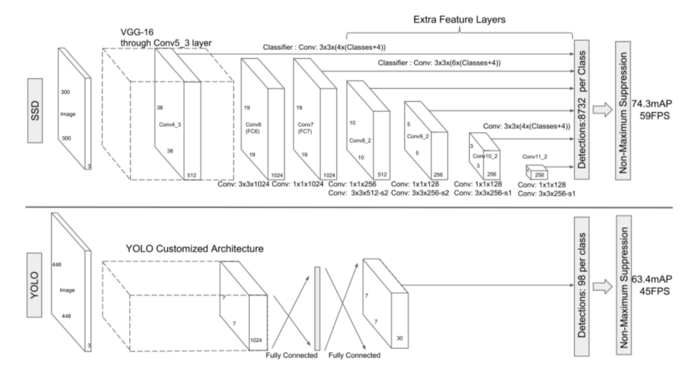
用于检测的多比例尺特征地图。将一串卷积特征层添加到截断的基础网络的末端。这些层的大小逐渐减小,并允许在多个尺度上进行检测预测。用于预测检测的卷积模型对于每个特征层是不同的。YOLO在单比例要素地图上操作。
用于检测的卷积预测器。每个添加的特征层(或者可选地是来自基础网络的现有特征层)可以使用一组卷积滤波器来产生一组固定的检测预测。对于具有p个通道的大小为m×n的特征层,用于预测电位检测的参数的基本元素是3×3×p小核,该小核产生类别的分数或相对于缺省框坐标的形状偏移量。
在应用内核的m×n个位置中的每个位置,它都会产生输出值。边界框偏移输出值是相对于相对于每个要素地图位置的默认框位置进行测量的。YOLO在此步骤中使用中间全连接层,而不是卷积过滤。
默认框和纵横比。一组默认边界框与多个要素地图的每个要素地图单元相关联。默认框类似于在较快的R-CNN中使用的锚框,但是,它们适用于几个不同分辨率的要素地图。
每个特征地图单元预测k个边界框,其中每个边界框包含c+4个预测:(1)c级分数;(2)相对于原始默认框形状的4个偏移量。因此,对于m×n特征映射,预测被编码为m×n×k×(c+4)张量。YOLO预测每个网格单元有B个边界框和一组分类分数。对于S×S特征映射,预测被编码为S×S×(B∗5+C)张量。
固态硬盘:培训
为默认框选择比例和纵横比。
来自不同图层的要素地图用于处理不同的对象比例,而所有对象比例上的参数是共享的。假设有m个用于预测的要素地图,则每个要素地图的默认框的比例计算如下:
将地面实况检测与默认框匹配。
- 将每个地面真值框与具有最佳Jaccard重叠的默认框相匹配。
- 将默认框与Jaccard重叠大于阈值(0.5)的任何基本事实相匹配。
这简化了学习问题,允许网络预测多个重叠的默认框的高分,而不是要求它只选择重叠程度最大的一个。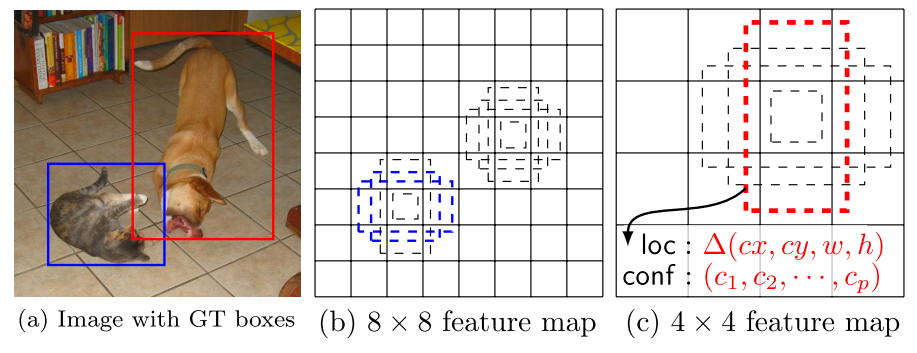
例如,狗与4×4要素地图中的默认框匹配,但与8×8要素地图中的任何默认框不匹配。这是因为这些盒子有不同的刻度,与狗盒不匹配,因此在训练期间被认为是负片。
在匹配步骤之后,大多数默认框都是负数。为了在正负训练样本之间取得平衡,采用置信度最高的方法对负样本进行排序,并选择最高的样本,使负样本与正样本的比例最多为3:1。
RetinaNet(2017年)
相对于其他检测器的改进
- 作者调查了单级检测器比两级检测器性能差的原因,发现这是由于训练过程中前景-背景类严重失衡所致。
- 为了解决这一类不平衡问题,引入了一种名为焦损的新损耗。它本质上是动态缩放的交叉熵损失,从而降低了分配给分类良好的示例的损失的权重。
- 设计了一种名为RetinanNet的简单致密探测器来评估焦散的效果。结果表明,当训练焦损时,RetinanNet能够与以前的单级检测器的速度相匹配,同时超过所有现有的最先进的两级检测器的精度。
焦损
研究发现,在密集检测器训练过程中遇到的极端类不平衡超过了交叉熵损失,其中容易分类的负片构成了损失的主要部分,并控制了梯度。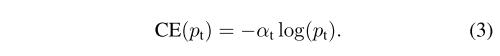
可以针对不同的类别引入权重因子α∈[0,1],但它只平衡正例/反例的重要性,而不平衡易例/硬例的重要性。因此,建议重塑损失函数,使简单的例子变得轻盈,从而训练可以集中在难的负数上。
焦损定义为如图所示的lhs,其中γ≥0是可调的聚焦参数。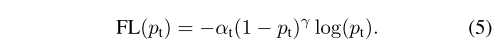
在实践中,使用α平衡形式的焦损,因为它产生比非α平衡形式略有改进的精度。
(1)当实例分类错误且p_t较小时,调制因子接近1,损耗不受影响。当p_t接近1时,因子变为0,分类良好的例子的损失被降低。
(2)聚焦参数γ平滑地调整简单示例的降权速率。当γ=0时,FL等同于CE,并且随着γ的增加,调制因子的影响也同样增加。
直观地说,调制因子降低了简单示例的损耗贡献,并扩展了示例接收低损耗的范围。例如,当γ=2时,与CE相比,分类为p_t=0.9时的示例的损耗将降低100倍。这反过来又增加了纠正错误分类示例的重要性。
与两级检测器在处理类不平衡方面的比较
两级检测器通常采用标准交叉熵损失和地址类不平衡两种机制进行训练:(1)两级级联和(2)有偏小批量抽样。
- 第一级联阶段是对象建议机制,其将几乎无限的可能对象位置集降低到一千个或两千个。重要的是,选定的方案不是随机的,但很可能与真实的物体位置相对应,这消除了绝大多数容易的负片。
- 当训练第二阶段时,通常使用有偏抽样来构建包含例如1:3正反样本比率的小批次。此比率类似于通过采样实现的隐式α平衡因子。
焦点损失被设计成通过损失函数直接在一级检测系统中解决这些机制。
RetinaNet
采用金字塔网络主干。
RetinaNet采用特征金字塔网络(FPN)(B)作为骨干网络。简而言之,FPN增加了一个具有自上而下路径和横向连接的标准卷积网络,因此该网络可以有效地从单分辨率输入图像构建丰富的多尺度特征金字塔。金字塔的每一级都可用于检测不同尺度的对象。
FPN构建在ResNet体系结构之上,并构建具有级别P3到P7的金字塔(级别l的分辨率比输入低2l),其中所有金字塔级别具有C=256个通道。
锚。
锚杆在棱锥体标高P3到P7上的面积分别为32²到512²。在每个棱锥体级别,锚点有三个纵横比:{1:2,1:1,2:1}。此外,添加了原始3个纵横比锚点集合中的{2⁰,2^(1/3),2^(2/3)}大小的锚点,以实现比原始fpn更密集的比例覆盖。
每个级别和跨级别总共有A=9个锚点,它们相对于网络的输入图像覆盖了32-813像素的比例范围。每个锚被分配分类目标的K维单热点向量和盒回归目标的4维向量。
使用0.5的IOU阈值将锚定指定给地面真实对象框;如果锚定的IOU在[0,0.4]中,则将其指定给背景。每个锚点最多分配给一个对象框。如果锚点未分配(IOU在[0.4,0.5)中),则在训练期间忽略该锚点。长方体回归目标计算为每个锚点与其指定对象长方体之间的偏移,如果没有指定,则省略。
分类子网(C)。
分类子网是连接到每个FPN级别的小型FCN,其中参数在所有金字塔级别之间共享。从给定的金字塔级别获取具有C个通道的输入特征地图,子集应用四个3×3卷积层,每个3×3卷积层具有C滤波器,并且每个之后紧接着RELU激活,接着是具有KA滤波器的3×3卷积层。最后,附加S型激活以输出每个空间位置的KA(A锚和K对象类)二元预测。
盒回归子网(D)。
该设计与分类子网相同,不同之处在于它终止于每个空间位置的4A(A锚点和4维盒回归目标)线性输出。边界框回归器是类不可知的。对象分类子网和盒回归子网虽然共享共同的结构,但使用不同的参数。
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/08/01/%e5%9f%ba%e4%ba%8ecnn%e7%9a%84%e5%8d%95%e7%ba%a7%e6%8e%a2%e6%b5%8b%e5%99%a8%e7%bb%bc%e8%bf%b0%e4%b8%8e%e6%af%94%e8%be%83-2/
