
在过去,变压器在自然语言处理领域表现出色。它们显著提高了语言处理模型的性能,其效果可与2012年以来通过卷积神经网络在图像理解方面所做的工作相媲美。现在,到2020年底,我们有变压器进入知名计算机视觉基准测试的前四分之一,例如ImageNet上的图像分类和CoCo上的目标检测。image classification object detection
继续上一篇关于基于变压器的DETR和稀疏R-CNN的文章的主题,在这篇文章中,我们将概述Facebook AI和索邦大学最近的联合研究“培训数据高效的图像转换器&通过注意力进行蒸馏”,他们的Deit模型以及哪些科学成就预见了这项工作。“Training data-efficient image transformers & distillation through attention”
变压器架构
概述
卷积网络在图像分类中的许多改进都是受变压器的启发。例如,挤压和激发、选择性核和分离注意网络利用机制类似于变压器自我注意机制。
2017年推出的《注意力就是你所需要的一切》论文中,机器翻译目前是所有自然语言处理任务的参考模型。这样的任务是越来越常见的家庭人工智能助手和呼叫中心的聊天机器人的核心。转换器能够在任意长度的序列数据中找到依赖项,而不会使模型变得非常复杂。由此,它在排序任务(如将文本从一种语言翻译成另一种语言或创建关于问题的答案)方面的出色表现应运而生。“Attention Is All You Need”
在变压器之前,这些任务采用递归网络。让我们讨论一下RNN与转换器相比的缺点。下面的幻灯片摘自帕斯卡讲师的演讲。lecture
这里我们可以看到以下具体内容:
结构
变压器具有编解码器结构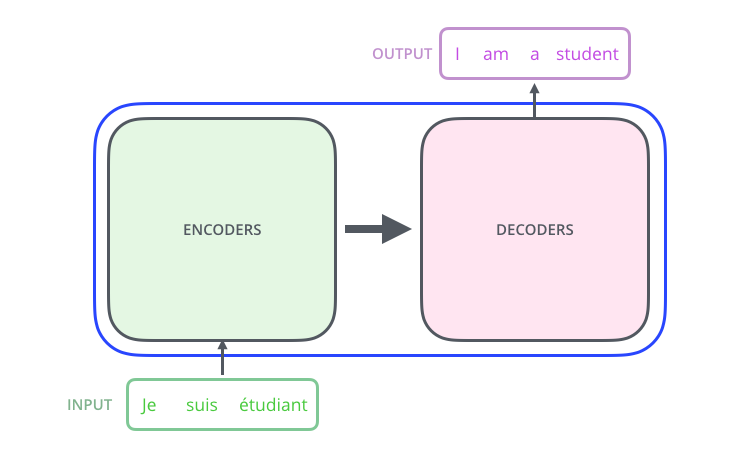
它将令牌带到编码器,并从解码器输出令牌。两个部分都由复合块组成,编码器和解码器之间略有不同。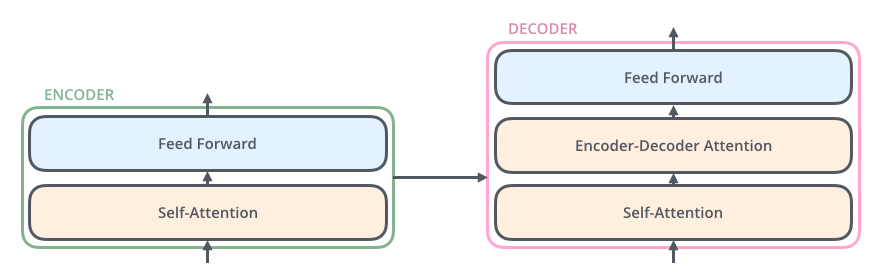
挡路的第一部分是自我关注层,它帮助挡路根据其他输入及其位置对输入进行编码。例如,输入句子中的单词。之后,输出进入创建新表示的前馈层。解码器挡路具有额外的掩码层,因为它与令牌的两个令牌序列一起操作,并且它应该不会看到以下尚未生成的令牌,即,它采用到目前为止生成的输入法语句子表示和英语输出单词的嵌入。
为了更好地理解变压器的体系结构,请看一看变压器作者之一的视频和插图很好的帖子video post
自我关注
网络的这一部分对变压器非常关键,Deit架构也高度依赖这一点。
简而言之,可以将注意力视为使用查询从(键,值)存储中检索值。其中结果值是基于
这篇论文的作者对此进行了更精确的定义。
其中在输入矩阵的每一行上应用SoftMax函数,并且D项提供适当的归一化。
Deit架构
作者提出的神经网络是本文提出的可视化变压器(VIT)的继承和逻辑延续。研究人员提出的新颖性主要体现在以下三个方面。paper
在图表上,您可以看到在ImageNet上的准确性和建议的网络变体、EfficientNet(ConvNet)变体和VIT之间的推理速度方面的比较
可视化变形金刚
Visual Transform具有简单而优雅的体系结构,将输入图像处理为N个固定空间大小为16×16像素的图像块序列。每个面片都投影有一个线性层,该线性层保持其总尺寸为3×16×16=768。
转换器挡路不知道补丁的顺序,这就是为什么在第一个编码层之前将固定或可训练的位置编码添加到补丁嵌入中的原因。
为了从受监督的数据中学习,VIT使用了BERT论文中提出的类令牌。类标记是转换网训练中类标记的类比。paper
Deit有三种变体。他们的表现如下表所示。
Deit-B与VIT的模型相同,即它具有相同的体系结构,但培训方式不同。Deit-Ti和Deit-S是较小的模型,只有多头自我注意的嵌入维度和头数随模型的不同而不同。较小的型号具有较低的参数计数和较快的吞吐量。对分辨率为224×224的图像测量了吞吐量。
不同分辨率的微调
作者采用了本文提出的微调程序。结果表明,使用较低的训练分辨率和以较大的分辨率微调网络是可取的。这种方法加快了全面训练的速度,并提高了在主流数据增强方案下的准确性,当您在相对较小的数据集(如ImageNet1k)上训练变压器时就是如此。this paper
当提高输入图像的分辨率时,作者保持块大小不变,从而改变了块的序列长度。变换不需要固定长度的序列,但需要调整补丁的位置嵌入。为此,作者在微调网络之前,采用了近似保持矢量范数的双三次插值。
蒸馏
除了在更大分辨率下的数据增强和微调之外,作者建议使用与VIT相比能显著提高DeIT性能的技术。他们将知识蒸馏应用于Deit,以传递凸轮的归纳偏差。inductive bias of convnets
我想让你在参加绩效评测之前先领会几点。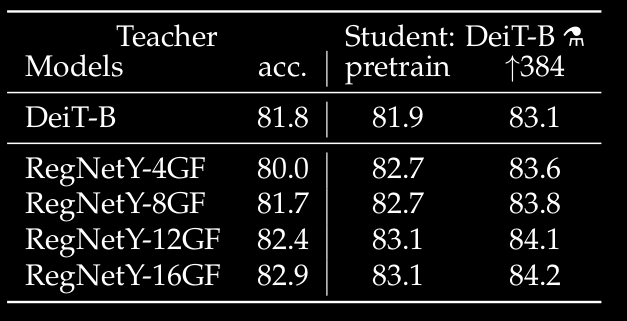
从论文中可以看出,使用ConvNet作为教师,Deit-B取得了比教师更好的效果。例如,RegNetY-8.0GF(请注意,由于增加的内容不同,这篇论文和原始论文的精确度有所不同)的成绩相当于其学生的两分RegNetY-8.0GF
上表显示了Deit-B的精确度在微调期间(第3列和第4列)是如何变化的,具体取决于使用哪个教师进行蒸馏(按行)。教师的初步准确性出现在第二栏中。
给我看密码!
在这最后一节中,您可以一如既往地找到指向报纸代码的链接。但如果你想在那里找到论文的主要建议,即蒸馏,不幸的是,它还没有提供,但其中一个问题说,它很快就会发布。code one of the issues
参考文献
[1]通过注意力https://arxiv.org/abs/2012.12877训练数据高效的图像转换器和蒸馏https://arxiv.org/abs/2012.12877
[2]第19讲:注意与变压器网络https://www.youtube.com/watch?v=OyFJWRnt_AYhttps://www.youtube.com/watch?v=OyFJWRnt_AY
[3]图解变压器http://jalammar.github.io/illustrated-transformer/http://jalammar.github.io/illustrated-transformer/
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/08/01/2020%e5%b9%b4%ef%bc%9a%e7%ae%80%e5%8e%86%e4%b8%ad%e7%9a%84%e5%8f%98%e5%bd%a2%e9%87%91%e5%88%9a%e6%89%a9%e5%bc%a0/
