
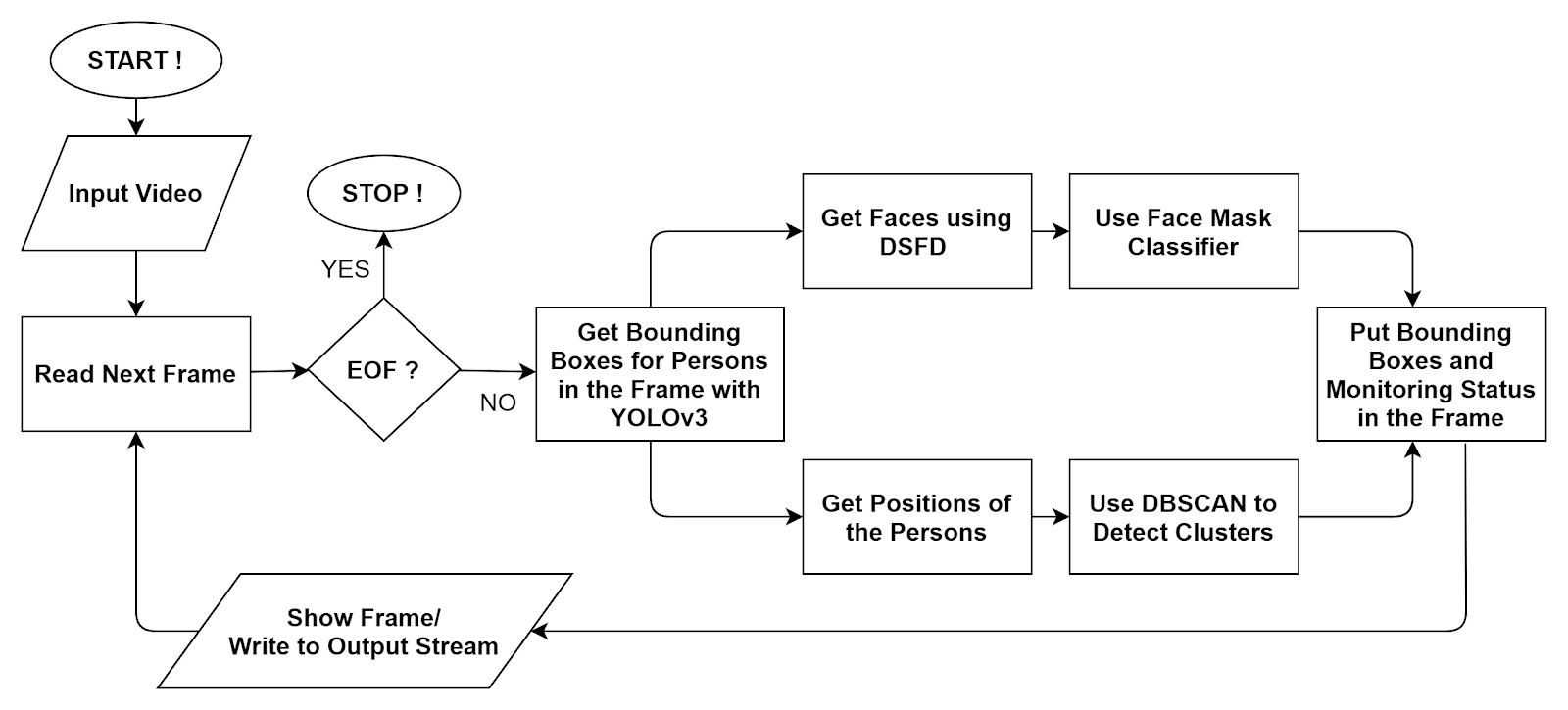
这个项目提出了一个基于计算机视觉的人工智能系统来检查在拥挤的地方或任何地方(如:市场或工作场所)是否保持着社会距离,并结合面具检测系统来跟踪戴口罩的人。该方案可用于闭路电视摄像机等视频监控系统。而数据,如附近的人数,违反社会距离的人数,以及没有戴口罩的人数,都被用于分析。
详细说明
我们的AI合规性由最先进的社交距离监控和面罩检测系统组成,以检查是否遵守规范。这个项目的目的是通过闭路电视摄像机拍摄的视频监控违反社会距离的人。使用YOLOv3-SPP进行人员检测,并使用基于摄像机位置和方向的3D深度因子模拟的社交距离分析工具来识别潜在入侵者。用于检测人脸的双镜头人脸检测器和面罩分类器模型(ResNet50)被训练和部署用于识别没有戴面罩的人。
1.人员检测
第一步是从现有的闭路电视摄像头捕获实时视频,使用yolo v3模型检测每帧中的个人。
YOLO(你只看一次)是一种最先进的实时物体检测系统。它是基于版本3的SPP模型(在COCO数据集上预先训练的),分辨率为608×608,在本项目中用于获取视频帧中个人的包围盒。为了获得更快的处理速度,可以使用416×416或320×320的分辨率。YOLOv3-TINY也可用于速度优化。然而,这将导致检测精度的降低。从Yolo v3模型中提取了适用于人物检测的输出层。如果置信度分数>0.5,则检测每个人。YOLO
2.人脸检测
在整个项目中使用双镜头人脸检测器(DSFD)来检测人脸。常见的人脸检测器,如Haar-Cascades或MTCNN,在这个特定的用例中效率不高,因为它们不能检测被覆盖或分辨率低的人脸。DSFD在检测大范围方向的人脸方面也有很好的效果。这对管道来说有点繁重,但能产生准确的结果。检测到的面部的坐标被进一步传递给掩模分类模型。Dual Shot Face Detector
3.面罩分类器
使用略微修改的ResNet50模型(在ImageNet上预先训练基本层)来分类人脸是否被正确遮蔽。一些AveragePooling2D层和以Sigmoid或Softmax分类器结尾的密集(带有丢失)层的组合被附加到基本层的顶部。可以使用不同的体系结构,但应避免复杂的体系结构,以减少过度安装。该模型需要在大量相关数据上进行训练,然后我们才能实时应用它,并期望它发挥作用。它需要很大的计算能力,我的意思是需要很大的计算能力!我们可以在本地机器上尝试在小数据集上训练的模型,但它不会产生理想的结果。因此,我目前使用的是预先训练好的开源模型。因此,我们使用Tang Pham团队训练的模型来实现这一目的。它基本上是一个经过修改的顶部的ResNet50型号。Thang Pham
使用略微修改的ResNet50模型(具有在ImageNet上预先训练的基层)来分类检测到的人脸是否被正确地遮蔽。将以Sigmoid或Softmax分类器结尾的一些平均池化2D和密集(带有丢失)层的组合附加到基本层的顶部。如果置信度分数小于0.5,则表示存在面罩,而如果置信度分数高于0.5,则表示不存在面罩。我们观察到,部署ResNet50预训练网络给我们带来了高精度的模型和更快的训练时间。
实施细节可以在本笔记本中找到。notebook
DBSCAN聚类算法通过计算每个包围盒之间的距离来识别潜在的入侵者,并在两个人或两个以上的人在一定的阈值距离(也称为人与人之间期望保持的最小安全距离)以下时发出警报。此参数会影响结果,因此会根据闭路电视摄像机拍摄的镜头进行调整。社交距离跟踪器遵循6英尺的规则,也会跟踪违反这一规则的人。这就完成了该解决方案的社交疏远方面。
一旦检测到人,使用从SCRKIT-LEARN模块导入的DBSCAN(Density Based Space Clusters Of Applications With Noise)数据聚类算法跟踪质心,以便唯一识别该人,并检查与相邻人员的距离。通过将以像素为单位的最小安全距离作为参数传递给上述算法,我们设置了判断是否保持社交距离的标准。如果计算的边界框质心之间的距离小于标准,则会将这两个ID附加到红色区域列表中,并为其创建具有标签=“不安全”的边界框。
建筑管道
结果
正如我们所看到的,系统识别框中的人,如果他们是安全的(无风险)、处于高风险或处于低风险级别,则分别放置浅绿色、深红色或橙色边界框。人与人之间的连接线表示人与人之间的亲近程度(红色表示非常接近,黄色表示接近)。在检测到人之后,系统还会检测到人脸,并通过放置绿色或红色边界框来识别此人是否戴着面具。状态显示在底部的栏中,显示所有细节。考虑到我们手头问题的复杂性,这些结果相当不错。



该项目的实施可在下面的GitHub链接中获得。
赞成与反对
优势
正如我们所看到的,AI系统识别帧中的人和他们的脸(如果它是可见的),并分别在他们安全或不安全的情况下放置绿色或红色边界框,以及正确检测蒙面人脸。状态显示在顶部的栏中,显示所有详细信息。考虑到我们手中问题的复杂性,这些结果相当不错,可以部署在CCTV监控AI解决方案中。
劣势
该模型需要在大量相关数据上进行训练,然后我们才能实时应用它,并期望它发挥作用。它需要很大的计算能力,我的意思是需要很大的计算能力!我们可以在云虚拟机中尝试在大数据集上训练的模型,这可能会产生理想的结果。目前,我使用的是预先训练好的开源模型。
未来范围
一些优化可以以矢量化的形式进行。要获得一个人的职位,有多种方法。其中之一是简单地使用本项目中使用的边界框的中心。另一种是使用OpenCV的透视变换来获得位置的鸟瞰视图,但这种方式需要相当精确的参考点框架。使用它还会略微增加系统的复杂性。但是,如果执行得当,无疑会产生更好的效果。目前,我们坚持第一种方法。记住,总有改进的余地!
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/08/03/%e5%86%a0%e7%8a%b6%e7%97%85%e6%af%92%e7%a4%be%e4%ba%a4%e8%b7%9d%e7%a6%bb%e7%9b%91%e6%8e%a7%e4%b8%8e%e5%8f%a3%e7%bd%a9%e6%a3%80%e6%b5%8b%e4%ba%ba%e5%b7%a5%e6%99%ba%e8%83%bd%e7%b3%bb%e7%bb%9f-2/
