

我们现在有充足的数据资源来满足我们对学习的渴望。这些数据有不同的形式、包装和交付方式。我们在之前的博客中使用了多种类型:
- 这里是来自Fast.ai库的一个中等大小的玩具数据集,
- 这里是来自Fast.ai库的大型玩具数据集,
- 在此导出外部数据集,
- 在这里通过网络搜索创建我们自己的数据集。
从Kaggle获取数据并不像我最初想象的那样是一种轻而易举的下载-上传方式。我找到了正确的公式,并决定将数据集应用于深度学习。
对于这个小型项目,我们将展示:
A.如何在Colab中使用Kaggle数据集,以及
B.如何使用Fast.ai快速手册的第07课中介绍的归一化、调整大小和测试时间放大计算机视觉技术。Lesson 07 in the Fast.ai FastBook
那么,打开卡格尔,和我一起探索吧!
A.在Colab中使用Kaggle数据集
a.如果您还没有帐户,请创建一个。它是免费的,而且处理得很快。
b.探索您感兴趣的数据集/比赛。这个博客涉及鸟类的计算机视觉/图像分类。computer vision/ images classification for birds
c.为每个类选择至少包含20幅图像的数据集。否则,您可能会遇到错误。
d.我已经能够对图像使用.jpg和.png格式。如果遇到.tfrec格式,请查找指向原始数据集的链接。
e.在安装前完成此操作。如果您进行了设置并分心,笔记本运行可能会断开连接,您需要重新运行。
注意:您可以在Colab中看到Kaggle数据集的列表,但是,初始内容检查最好在Kaggle网站中完成。
2.设置。
a.笔记本
您可以在Kaggle中运行笔记本。然而,对于这次跑步,我们将在Colab进行。如果您是Colab新手,请参阅此处的步骤1a-b。see Step1 a-b here
如果您选择大数据集,我建议使用GPU和高RAM运行时。
b.安装和进口
i.Fast.ai库的一般设置。
在Colab笔记本中,运行以下命令:
!pip install -Uqq fastbook
import fastbook
fastbook.setup_book()
from fastbook import *
#!pip install fastai -U # unhash if this is your first use
import fastai
from fastai.vision.all import *二、二、使用Kaggle数据集的特定设置。
- 在Kaggle页面中,打开您的“帐户”。
- 创建新的API令牌。
- 在Colab笔记本中,安装Kaggle并上传API Token/Kaggle json文件。
!pip install -q kaggle
from google.colab import files
files.upload()- 创建Kaggle目录并启用访问。
!mkdir ~/.kaggle
!cp kaggle.json ~/.kaggle/3.收集您的数据。
a.下载代码格式。
- !卡格尔
- 数据集还是竞赛集(例如,在Kaggle中,您的集合是来自数据集还是竞赛部分?)
- 下载
- 路径
对于路径,请使用kaggle.com之后的url部分。例如:
此处使用的kaggle数据集可以在DataSets集合中找到,URL为:https://www.kaggle.com/gpiosenka/100-bird-species.https://www.kaggle.com/gpiosenka/100-bird-species
!kaggle datasets download 'gpiosenka/100-bird-species/train'我指定了列车,但它还是下载了列车和验证集。
b.从下载的压缩文件中获取单个文件,并在完成后删除该压缩文件。
!unzip \*zip && rm *.zip
c.指定路径。
train_path = 'birds_rev2/train'就这样!不需要创建数据帧或进行任何其他预处理。
B.高级成像技术示例。
如果您想要了解有关映像转换的介绍或复习内容,请参阅此资源。您可以使用与此处下载的相同的数据集,但稍作修改:从步骤3开始,使用(Train_PATH)而不是(path/‘images’)。refer to this resource
我们将看看归一化、调整大小和测试大小增加如何影响从非预训练模型开发的学习者的准确性。有关更详细的说明,请参阅此处。here
dblock = DataBlock(
(ImageBlock(), CategoryBlock()),
get_items = get_image_files,
get_y = parent_label,
splitter = RandomSplitter(seed=42),
item_tfms = Resize(460),
batch_tfms = aug_transforms(size=224))
dls = dblock.dataloaders(train_path)
dls.train.show_batch()
dls.train.show_batch(unique=True)
我们可以欣赏这里的一些基线转换,如裁剪、L-R方向和光线强度。
model = xresnet50(n_out = dls.c)
learn_base = Learner(dls, model, loss_func = CrossEntropyLossFlat(),
metrics = accuracy)
learn_base.fit_one_cycle(5, 3e-3)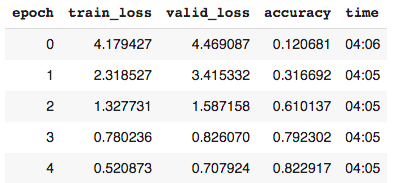
- Learner是Fast.ai中的代码类,用于组装数据、模型和培训。
- Xresnet是一种顺序的、非预先训练的神经网络。
- n_out=dls.c表示类别或标签的数量。
- 交叉熵损失是模型能够学习的计算。它是从类的预测概率导出的。概率值的范围从0到1。当这些值被转换为交叉熵时,接近0(非常差的预测)的概率变得更加明显,因此受到的惩罚更多。
- 交叉熵损失平坦是交叉熵损失的重组,便于处理。
- 虽然计算机需要损失提供的梯度信息,但是精度度量更好地服务于人的解释。
learn_base.lr_find()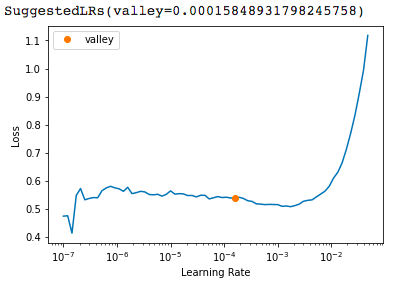
我们的基准学习率是0.003,根据LR_FIND保持这个比率是合理的。
learn_base.show_results()可视化一些基线结果:
上面的标签是实际的,下面的标签是预测的。如果您想了解如何区分标签(实际与预测),请参阅此处的步骤6.a。Step 6.a here
快速的网络搜索可以给我们一些比较的图像来理解学习者的错误预测。
解释:从零开始训练的基线模型在使用交叉熵损失进行5个阶段的学习后,准确率为82%,学习率为0.003。
2.应用归一化变换。
dblock = DataBlock(
(ImageBlock, CategoryBlock),
get_items = get_image_files,
get_y = parent_label,
item_tfms = Resize(460),
batch_tfms = [*aug_transforms(size=224),
Normalize.from_stats(*imagenet_stats)]) #
dls_norm = dblock.dataloaders(train_path, bs=64)让我们来看一看样本数据,看看数字层面的转化:
x, y = dls.one_batch() # baseline
xn, yn = dls_norm.one_batch() # normalized基线和标准化的x和y都有相同的形状:批次64个项目,RGB 3个通道,以及我们指定的224 x 224像素大小。
print('Non-normalized tensors:', x[0][0][0][:10])
print('Mean:',x.mean(dim = [0,2,3]))
print('Std:', x.std(dim = [0,2,3]))
规格化允许将不同的值集放在相同的刻度中,以便可以对它们进行比较。组平均值为0,标准差为1。
随着数字的变换,让我们可视化一下效果:
model = xresnet50(n_out = dls_norm.c)
learn_norm = Learner(dls_norm, model, loss_func = CrossEntropyLossFlat(), metrics = accuracy)
learn_norm.fit_one_cycle(5, 3e-3)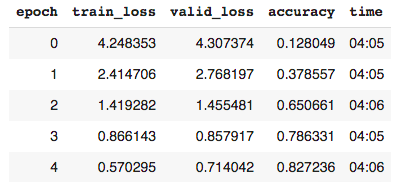
归一化只带来了很小的改进,可能是因为图像已经相对相似了。
可视化一些结果:
将错误分类的鸟类与网络上的一些资源进行比较,发现了念力的一些可能原因,特别是主色和整体形状。
解释:从零开始训练的归一化模型在使用交叉熵损失进行5个阶段的学习后,准确率为83%,学习率为0.003。
3.应用渐进式大小调整
从一个小尺寸的图像开始训练。
dblock = DataBlock(
(ImageBlock, CategoryBlock),
get_items = get_image_files,
get_y = parent_label,
item_tfms = Resize(460),
batch_tfms = aug_transforms(size=128)) # start small
dls_128 = dblock.dataloaders(train_path, bs=64)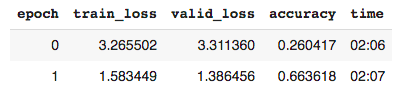
向更大尺寸的图像发展。
dblock = DataBlock(
(ImageBlock, CategoryBlock),
get_items = get_image_files,
get_y = parent_label,
item_tfms = Resize(460),
batch_tfms = aug_transforms(size=224)) # bigger
dls_224 = dblock.dataloaders(train_path, bs=64)并将新的DLS应用于先前训练的学习者。
learn_128.dls = dls_224
learn_128.fit_one_cycle(3, 3e-3)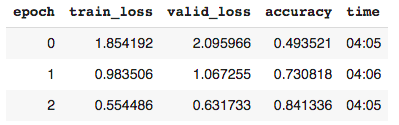
我们可以看到,最初的训练规模较小,然后进行到更大的规模,导致的准确率略高于基线(84.1vs82.3%)。运行小尺寸图像的速度是原来的两倍(2分钟比4分钟)。
解释:从零开始训练的大小调整模型在使用交叉熵损失进行5个时期的学习后,准确率为84%,学习率为0.003。它还实现了稍微快一点的培训。
4.使用测试时间增加(TTA)。
验证集图像通常进行中心裁剪。不用说,使用这种默认技术会丢失一些信息。TTA通过从原始图像的多个区域裁剪来解决这一问题。
# using the baseline dblock and dls
model = xresnet50(n_out = dls.c)
learn = Learner(dls, model,
loss_func = CrossEntropyLossFlat(),
metrics = accuracy)由此得到的准确率为0.8277,而基线为0.8251。
解释:TTA步骤在基线模型的基础上提高了0.2-0.3%的准确度。
5.结合这些先进的转换技术。
对于我们的最终建模,我们将使用渐进式大小,从128到224。我们将使用FINE_TUNE,它默认执行规范化。我们会将TTA应用到学习者身上。
dblock = DataBlock(
(ImageBlock, CategoryBlock),
get_items = get_image_files,
get_y = parent_label,
item_tfms = Resize(460),
batch_tfms = aug_transforms(size=128)) #
dls_128 = dblock.dataloaders(train_path, bs=64)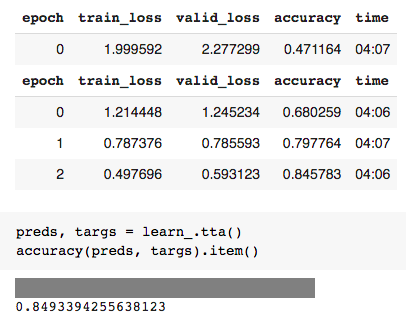
interp = ClassificationInterpretation.from_learner(learn_)
interp.most_confused(min_val = 5)
看看网络进行比较,我们可以说,大多数人也会发现这些图像很难区分。
解释:最终的模型是从零开始训练的,使用递进大小调整、归一化和时间序列分析,使用交叉熵损失进行5个阶段的学习后,准确率为85%,学习率为0.003。对于一般的鸟类分类方案,错误分类被认为是合理的。需要区分物种的学术论文可能会受益于更多的时代运行和使用歧视性的学习率。discriminative learning rates
6.让我们一起玩吧!
btn_upload = widgets.FileUpload()
btn_upload
img = PILImage.create(btn_upload.data[-1])
out_pl = widgets.Output()
out_pl.clear_output()
with out_pl: display(img.to_thumb(250))
pred, pred_idx, probs = learn_.predict(img) # rev
lbl_pred = widgets.Label()
lbl_pred.value = f'Prediction: {pred}; Probability: {probs[pred_idx]:.04f}'
btn_run = widgets.Button(description = 'Classify')
btn_run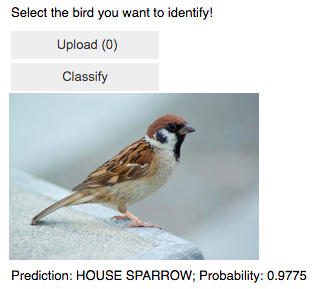
如果甘道夫是一只鸟,让我们看看他会是什么样子-
足够接近:0)
摘要:
我们能够在Colab笔记本中使用Kaggle数据集。我们使用非预训练模型应用了先进的计算机视觉变换,并在验证集上获得了85%的准确率。
我希望你和我一样玩得开心!
玛丽亚
在LinkedIn上与我联系:https://www.linkedin.com/in/rodriguez-maria/https://www.linkedin.com/in/rodriguez-maria/
或者在推特上关注我:https://twitter.com/Maria_Rod_Datahttps://twitter.com/Maria_Rod_Data
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/08/06/%e8%ae%a1%e7%ae%97%e6%9c%ba%e8%a7%86%e8%a7%89%e6%8a%80%e6%9c%af%e5%9c%a8kaggle%e6%95%b0%e6%8d%ae%e9%9b%86%e4%b8%8a%e7%9a%84%e5%ba%94%e7%94%a8/
