

PDF是非常有用的存储医疗和财务文档的格式。这些文档中的大多数都包含表格,我们需要从其中提取数据以满足业务需求。
我们以前写过关于电光光学字符识别中表检测和提取的内容,而在这篇文章中,我们将更详细地介绍如何从pdf中提取表格数据。Table Detection & Extraction in Spark OCR
电光光学字符识别可以处理可搜索和扫描(图像)的pdf文件。
1.使用电光光学字符识别启动电光会话
import os
from sparkocr import start在启动电光会话期间,启动功能会显示以下信息:
电光版本:3.0.2星火自然语言处理版本:3.0.1星火光学字符识别版本:3.5.0
2.阅读PDF文档
作为示例,我们将处理带有预算拨备表的PDF文件。让我们将其作为binaryFile读取到dataframe,并使用display_pdf util函数显示内容:PDF file
from sparkocr.transformers import *
from sparkocr.utils display_pdf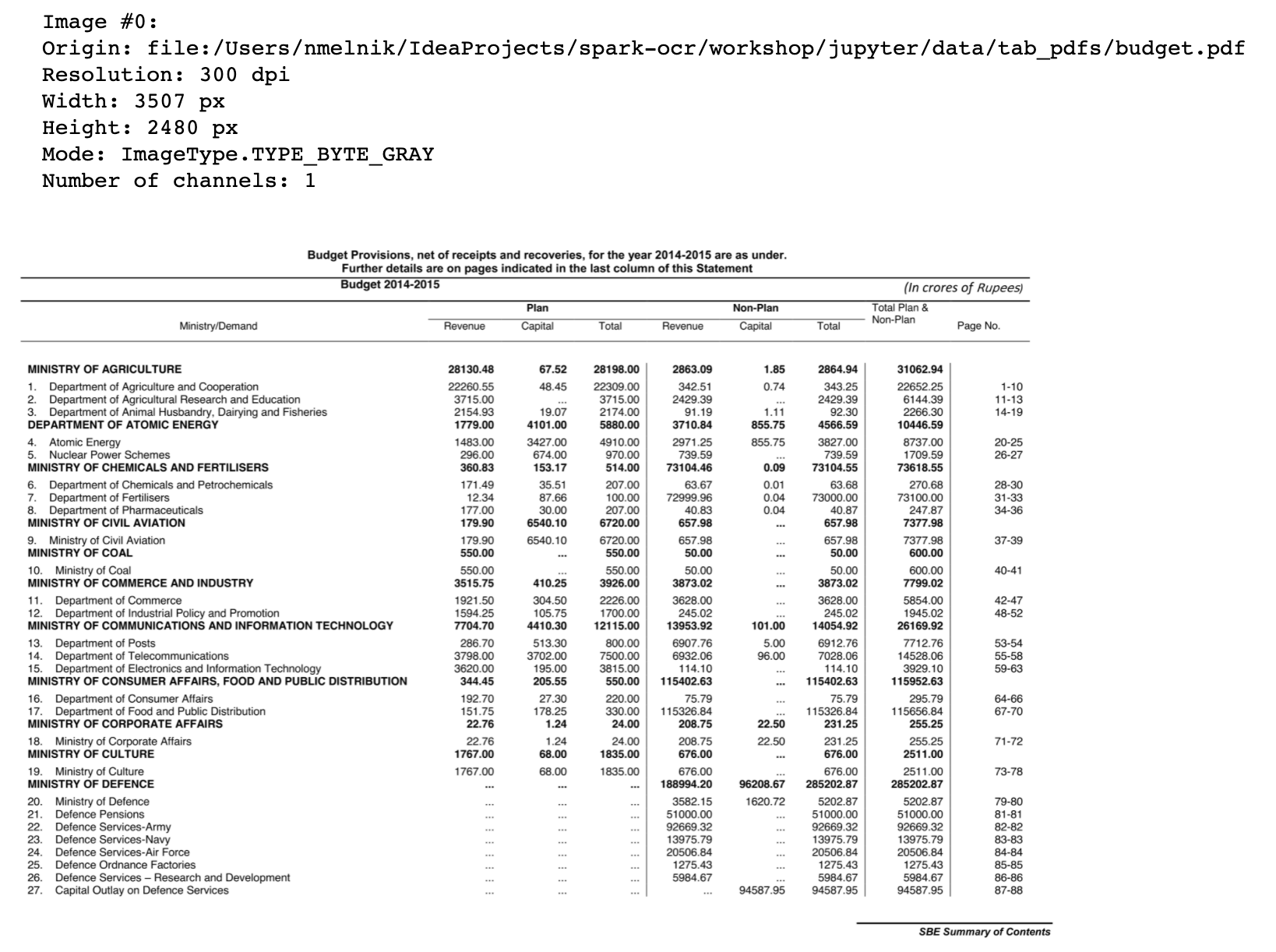
3.定义电光光学字符识别管道
为了将PDF的每一页转换成图像,我们可以使用PdfToImage转换器。它是为处理大大小小的pdf而设计的(最多可以处理几个海量页面)。它支持以下功能:PdfToImage
- 在处理大文档时,将大文档拆分成小PDF,有效利用集群资源。因此,如果需要,我们可以将处理一个大文档分配给所有集群节点。它支持少数拆分策略:拆分策略.FIXED_NUMBER_OF_PARTITIONS和拆分策略.FIXED_SIZE_OF_PARTITION。
- 拆分后对数据帧进行重新分区,以避免数据帧中出现偏差。当作业的一个任务的处理时间很长时,这可以防止出现这种情况。这样才能更有效地利用资源。
- 尽快将图像二值化,以减少内存使用和加速处理。
- 提取每页图像后重新分区数据帧。这还可以防止数据帧中的偏差。
整个表格检测和提取流水线:
# Convert pdf to image
pdf_to_image = PdfToImage()ImageTableCellsDetector可检测单元格,并支持以下几种算法:
- CellDetectionAlgos.MORPHOPS可以处理有边框、无边框的表格和组合表。
- CellDetectionAlgos.CONTOURS只能处理有边框的表,但可以提供更准确的结果。
4.运行管道并显示结果
让我们运行我们的管道并在页面上显示检测到的表:
results = pipeline.transform(pdf_df).cache()
我们可以从REGION字段获得概率分数的表格坐标:
results.select("region").show(10, False)最后,我们可以显示从表字段检测到的结构化数据:
exploded_results = results.select("table", "region") \
.withColumn("cells", f.explode(f.col("table.chunks"))) \
.select([f.col("region.index").alias("table")] + [f.col("cells")[i].getField("chunkText").alias(f"col{i}") for i in
range(0, 8)]) \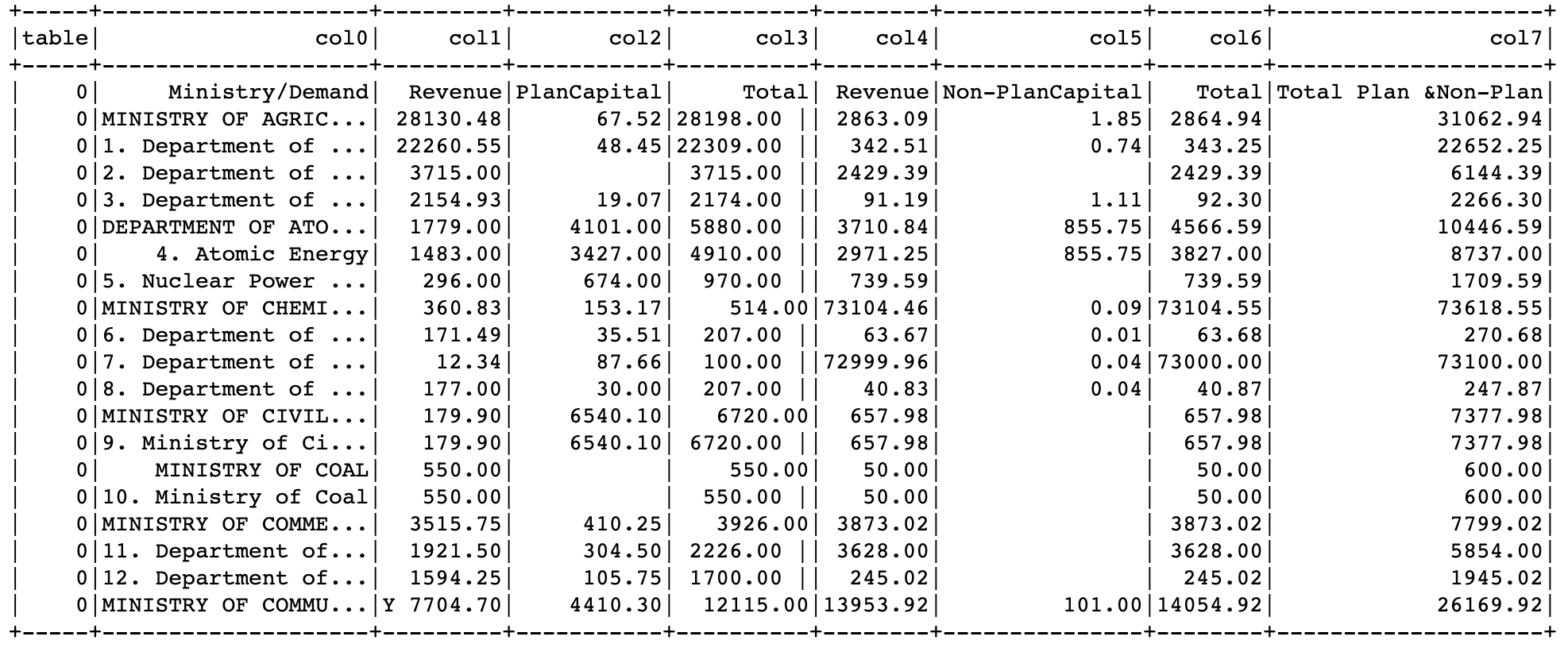
链接
- 带完整示例的笔记本
- 电光光学字符识别中的表格检测与提取
- 在电光光学字符识别研讨会上可以找到更多示例
- 电光光学字符识别文档
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/22/%e5%9c%a8%e7%94%b5%e5%85%89%e5%85%89%e5%ad%a6%e5%ad%97%e7%ac%a6%e8%af%86%e5%88%ab%e4%b8%ad%e4%bb%8epdf%e4%b8%ad%e6%8f%90%e5%8f%96%e8%a1%a8%e6%a0%bc%e6%95%b0%e6%8d%ae/
