

大家好!欢迎回来。今天是我分心驾驶项目的第二天。如果你还没有读过我第一天的博客,它就在这里。it is here
在上一篇博客中,我通过重新创建TensorFlow的image_Dataset_from_directory()的部分内容对齐了我的图像和标签。
什么是数据预处理?为什么要这样做?
我们的计算机不能识别图像。他们所理解的只有数字。因此,我们必须将图像转换为数字,然后才能将其提供给我们的模型。根据项目目标的不同,数据预处理的步骤也会有所不同。
以下是我为我的项目采取的步骤:
- 数字编码(将图像转换为数字)
- 规格化(将数值转换为0到1之间的数字)
- 数据批处理(创建数据批)
- 拆分数据
对图像进行数字编码和归一化
这个过程非常简单。我首先使用tf.io.read_file()读取文件,然后使用tf.image.decode_jpeg()将其转换为形状张量(480,640,3)。这意味着每个图像长480个像素,宽640个像素,并且有3个颜色通道(RGB)。之后,我使用tf.image.Convert_image_dtype()函数将像素颜色值转换为0到1之间的值。然后,我将所有这些都放到一个名为process_image()的函数中。
返回数字编码的归一化图像及其标签
在这个函数中,我接受图像及其标签作为参数,并给出了预处理后的图像及其标签的元组。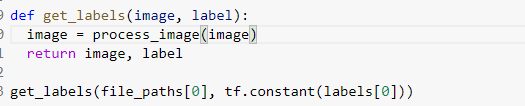
此代码输出:
批量处理数据
这部分是这个过程中最具挑战性的部分。我不仅要对列车数据进行批量处理,还要对验证和测试数据进行批量处理。为此,我给出了单独的参数来检查数据类型-数据是列车、验证还是测试拆分。
我的数据使用标准批大小32。
测试拆分
因为测试拆分没有标签(我们需要预测它),所以我使用tensor_from_slices()将图像路径转换为TensorFlow DataSet对象,并对其使用process_image()函数(因为它不需要标签)。然后,我用32号的标准尺寸对它们进行了分批。我使用蟒蛇映射函数同时进行图像处理和批处理。现在,我返回了批处理的数据。
验证拆分
验证拆分将有标签,但不需要对其进行混洗。因此,我使用tensor_from_slices()将图像路径转换为TensorFlow DataSet对象,并对其使用get_labels()函数(因为它同时处理图像和标签),并使用map函数将其批处理为大小为32。然后我返回批处理的数据。
列车拆分
分裂的火车会有标签,需要重新洗牌。因此,我采取了与处理验证数据相同的过程,并在处理和批处理数据之前对数据进行了混洗。
最终的代码如下所示: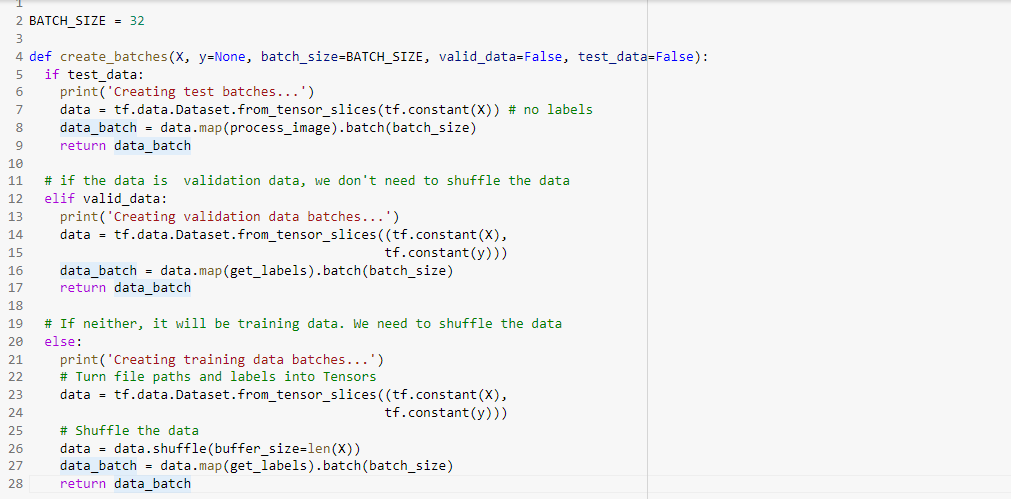
拆分数据并对其进行预处理
对于这一部分,我使用了SCISKIT-LEARN的Train_Test_Split模块。
因为我已经获得了一个测试集,所以我将我的训练数据分为训练数据集和验证数据集,其中验证数据集将是整个训练数据的20%。
之后,我使用CREATE_BATCH函数对它们进行预处理,并将它们存储到TRAIN_DATA和VAL_DATA中
结论
精彩的!现在,我们已经对数据进行了预处理,并准备好建模。明天,我们将尝试一些流行的模型架构,看看它的效果如何。
希望你和我一样喜欢这个。明天见!
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/24/%e5%88%86%e5%bf%83%e9%a9%be%e9%a9%b6%e7%ac%ac%e4%ba%8c%e5%a4%a9%e2%80%8a-%e2%80%8a%e6%95%b0%e6%8d%ae%e9%a2%84%e5%a4%84%e7%90%86/
