
来自马克斯·普朗克智能系统研究所和苏黎世ETH的研究人员提出了一种非常优雅的方法,可以在给定的3D场景中生成看似合理的人。让我们讨论一下为什么它是相关的,并深入到细节中。Max Planck Institute for Intelligent Systems ETH Zurich
当前连词
工业界和学术界正在推动现实世界环境的数字化。虽然苹果(和其他智能手机/平板电脑生产商)推出了带有深度传感器和LiDAR的新设备(点击这里的演示),但来自世界各地的研究人员正在努力寻找使用新型数据的新方法。这些数据主要由常见的起居室和浴室、办公室和食堂的3D扫描组成,并具有安静的良好细节水平。有大量的任务跟踪可以处理这样的数据,例如,在OccuSeg论文中对家具进行语义和实例分割,或者像我的科学小组关于RGB-D扫描的基于部分的理解(Part-Based Underach of RGB-D Scan)论文中所做的那样,对家具进行部分完成。这些任务(以及许多其他任务)对于创造智能助手至关重要,这些助手可能会帮助痴呆症患者、老年人或残疾人充分地生活在自己的房子里。我们知道真实的室内环境可能包含人,但大多数现有的数据集都没有。Place论文(Place:Approach Learning of Arkulation and Contact in 3D)的作者,他们正在解决现有3D虚拟现实环境(如人居)的这一重大限制。它们提供了一种在3D环境中生成人体网格的方法demo paper paper scientific group PLACE: Proximity Learning of Articulation and Contact in 3D Habitat
架构
让我们更仔细地看一下该方法的组件
基点设置
Place-利用ICCV 2019年这篇文章中提出的基点的想法。article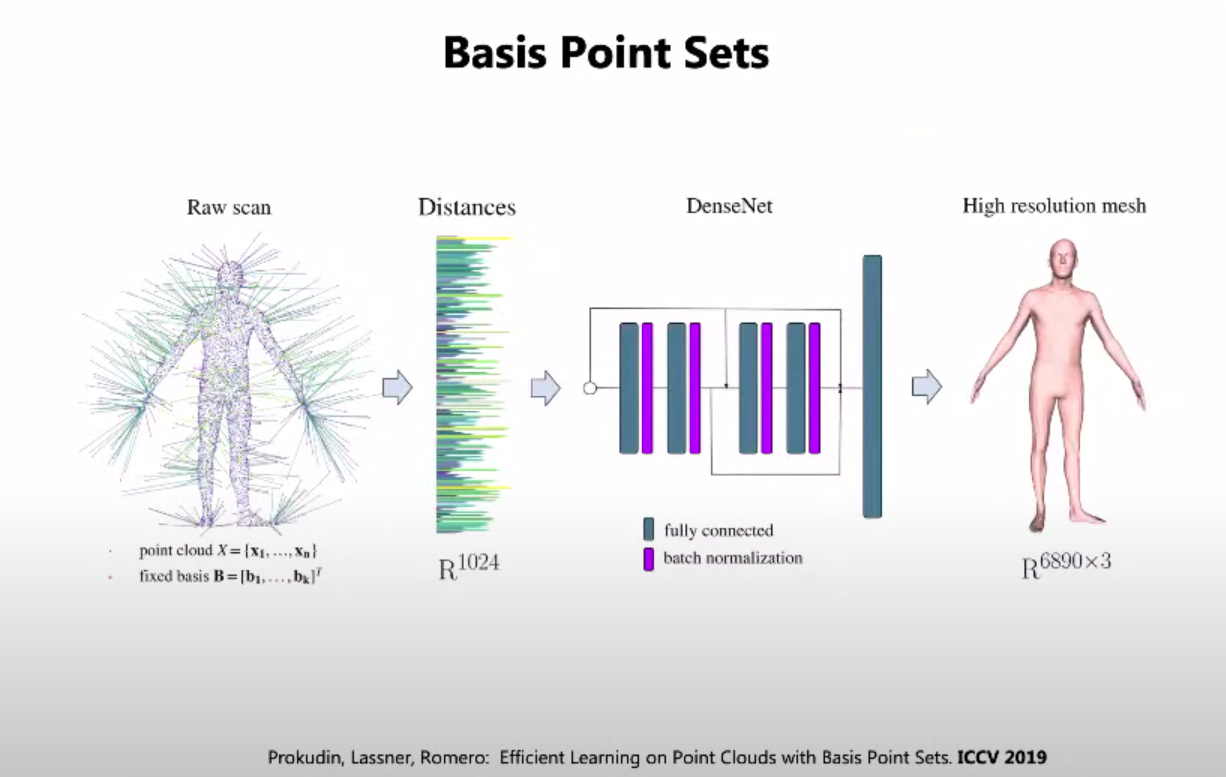
它们用到空间中设置的固定基点的距离对原始人体点云进行编码,然后使用该编码使用简单的MLP从SMPL-X推断出全身高分辨率网格。固定基点意味着对于每个不同的输入体点云,我们将计算到空间中相同点的距离。原始纸张的定点数量是1024个,而在地方纸张中,这个数字上升到10k。正如您从幻灯片中看到的,可以在不了解人所在场景的情况下创建这样的编码。但作者更进一步,给我们提供了创建人与场景交互表示的方法。SMPL-X
给定场景网格(3D环境)和人体网格,场景顶点上可能有基点。由此推导出两个定义:场景BPS-场景上设置的固定基点和BPS特征-从人体网格的基点到顶点的距离。在这个视频中,你可以看到环境中固定的一组点,由于不同的姿势有不同的BPS特征,不同的身体实际上有不同的距离集。to have basis points on the scene vertices video
基于距离的人体网格生成器

为了创造一种能够产生可信的人体的发电机,作者们提出了以下方案。在给定场景和人体网格的情况下,他们计算BPS特征(距离),并训练变分自动编码器(VAE)来重建这些距离。从该点开始,重建的身体特征进入MLP,然后回归为全身顶点。MLP输出两个内容:所有躯干顶点和中间重建顶点的全局3D平移,它们的总和给出重建躯干顶点。本文所有训练所使用的初始数据源为PROX数据集。PROX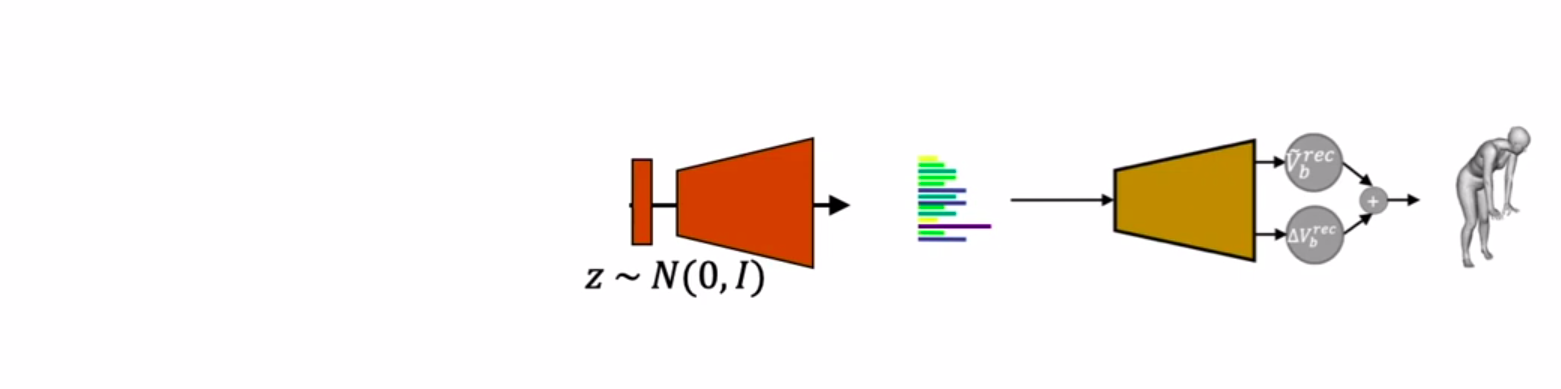
在测试过程中,人们可以从高斯分布中采样随机向量,并将其传递给VAE的解码器。这给了我们一条人类网格生成管道。
您可能会注意到,此模型仅适用于场景网格上的单个场景和单个固定点集。在上面简要介绍了VAE之后,我们将讨论作者建议如何克服这个问题
变分自动编码器简介
这项工作使用VAE来重建人类网格,正如我们稍后将在环境表示中看到的那样。为了达成一致,让我们快速讨论一下VAE是如何工作的。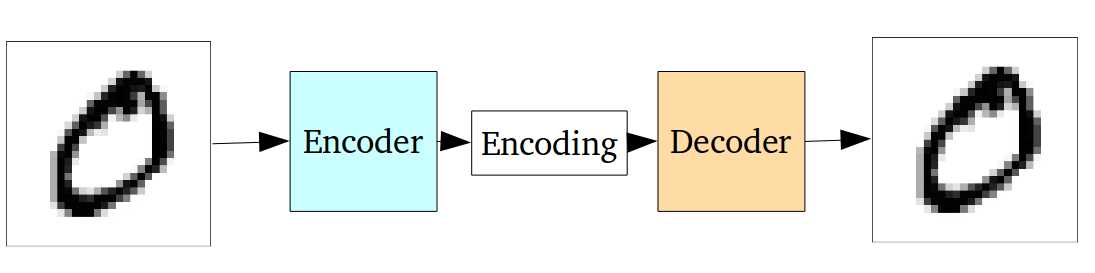
标准的自动编码器由编码器和解码器两部分组成。编码器将高维数据(如3D网格)压缩为低维表示形式,通常为大小为N的向量。相反,解码器将此向量扩展为原始数据。这两个是利用重构损失联合训练的神经网络。这种损失改善了编码器丢弃不必要信息的能力和解码器创建接近源数据的输出的能力。
可以使用自动编码器作为类似于训练数据的新数据样本的生成器。但是,香草自动编码器的解码器只能从训练期间出现的潜在矢量中产生有效数据。为了克服这些限制,我们可以使用可变自动编码器或VAE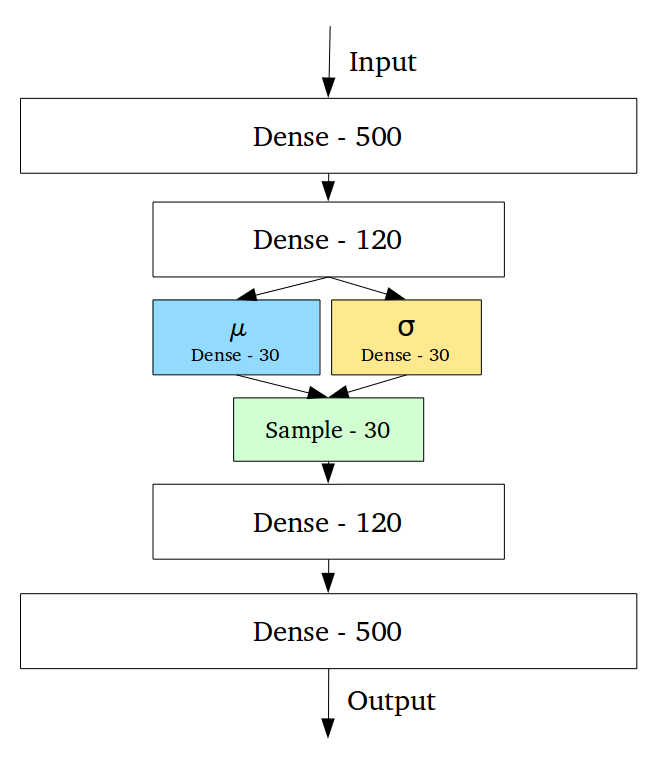
看看这篇帖子里的照片吧。在网络的中间,我们看到了μ,σ和示例。两个模型之间的主要区别在于这样一个事实,即对于每个输入,香草AE产生一个长度为30的潜在表示,而VAE则创建两个正态分布参数的向量(µ和σ)。输入片段的确切潜在表示将是在采样层获得的30个随机变量的实现。this
这使得我们的编码偏差稳健,因为在这种情况下,解码器被教导不仅对于一个向量,而且对于潜在空间中的一组闭合点(分布在μ周围,偏差为σ)预测相同的输出。这整件事的训练有两个损失:重建和KL发散。在这种情况下,后者用于强制所有参数μ,σ偏离标准正态偏差较小(参数为0,i的平均值)。您可以在此处了解有关这些损失如何加权的更多信息。here
基于两级距离的真人场景编码
回到人类生成的任务,不可能不同意这样的观点,即不是在唯一的场景中而是在任何给定的场景中都能够生成人类是非常可取的。为了克服这一问题,Afters建议使用相同的技术对场景中的人体和场景本身进行编码,即使用基点和VAE。
基点固定在三维空间中立方体框架的墙壁和天花板上。相同的基点集合用于Prox数据集中的任何输入场景裁剪。这种方法有助于了解人体网格周围的上下文和身体特征本身。由于人的自动编码器是以场景的潜矢量为条件的,所以它变成了一个条件VAE。在实践中,这种条件作用可以通过将来自两个网络的潜在向量连接起来,然后将其传递给人类生成器的解码器来实现。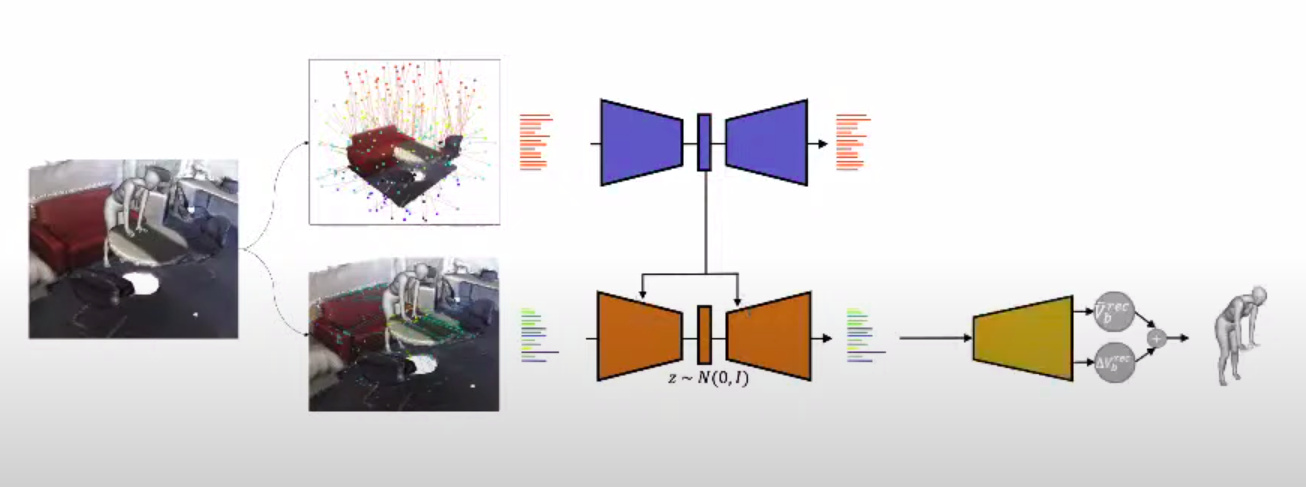
在提议的两个VAE之上,仍然有MLP可以倒退高分辨率的人体网格。根据作者的说法,这种方法会带来很好的结果,但当他们再增加一个条件时,结果会变得更好。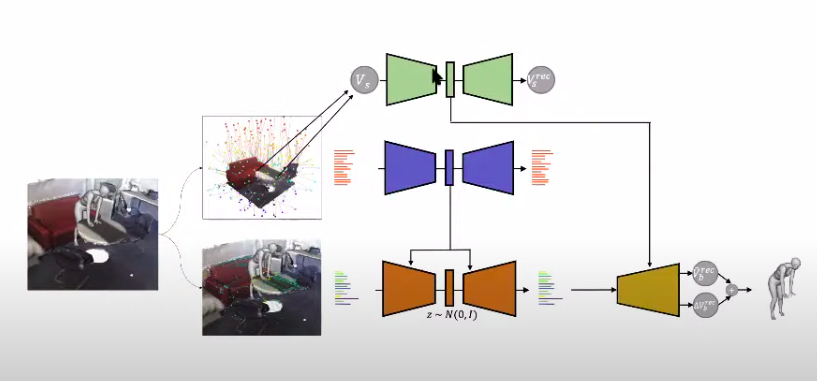
研究人员建议不仅使用距离对场景进行编码,而且还使用网格曲面的绝对(x,y,z)坐标进行编码。负责这种编码的其他VAE及其潜在向量在流水线结束时被馈送到回归MLP
基于交互的优化
整体位置法的最后一步是基于交互的优化。
它们在体型的θ参数上引入了复杂的损失。这种损失一方面有助于克服相互渗透(如右数第三栏所示),另一方面也迫使网络产生更自然的身体姿势(见第一栏)。
结果评价
为了评估结果的质量,作者请评审员参与。他们编写了一个工具,用户可以在其中比较两个不同的人类网格,并决定哪一个模型“更好”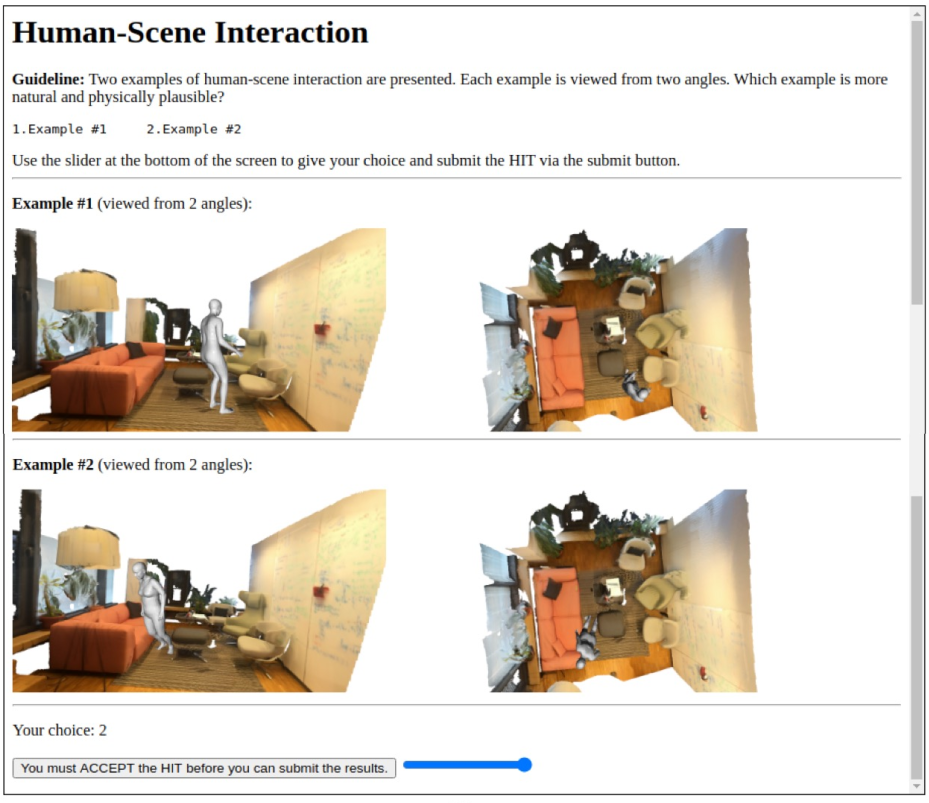
这将导致以下结果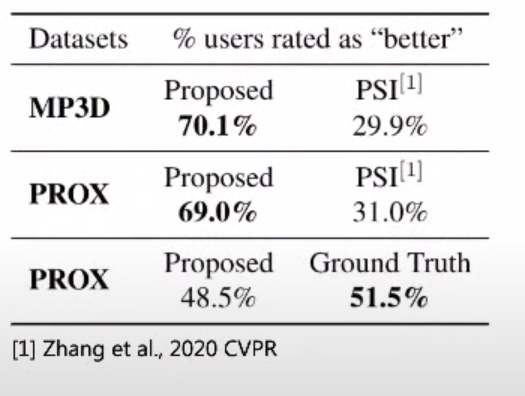
在评估阶段,在两个数据集上,大约70%的用户认为所提出的模型比以前的模型要好于(来自相同作者的)PSI模型。而且非常鼓舞人心和有趣的是,48.5%的用户认为生成的人类比地面真相本身更可信。您可能还会注意到,结果仅适用于Prox,并且模型是针对Prox进行培训的。PSI model
给我看密码!
本文向我们展示了在三维人体形状生成领域取得的丰硕成果。这一结果可能对研究室内3D模型的研究人员和开发人员有用,也许我们会在不久的将来看到类似的方法用于虚拟辅助技术或电脑游戏,谁知道呢。但您今天可以重现结果,因为作者提供了他们在GitHub上进行的实验的代码库。github
参考文献
[1]Place:3D环境中关节和接触的邻近学习https://arxiv.org/abs/2012.12877https://arxiv.org/abs/2012.12877
[2]直观了解变分自动编码器https://medium.com/r?url=https%3A%2F%2Ftowardsdatascience.com%2Fintuitively-understanding-variational-autoencoders-1bfe67eb5dafhttps://medium.com/r?url=https%3A%2F%2Ftowardsdatascience.com%2Fintuitively-understanding-variational-autoencoders-1bfe67eb5daf
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/08/01/%e6%94%be%e7%bd%ae%e6%96%b9%e6%b3%95%ef%bc%9a3d%e5%9c%ba%e6%99%af%e4%b8%8a%e7%9a%84%e4%ba%ba%e4%bd%93%e7%94%9f%e6%88%90%e5%99%a8/
