
Fastai是一个建立在PyTorch上的深度学习库,它基于迁移学习原则运行,预先训练的模型(分类器)经过微调和训练,以根据新输入的数据做出预测,从而节省了时间,而不是从头开始训练我们的模型。要在您的计算机上运行FAST AI代码块,需要一个可以访问GPU的Google Colab。
!pip install -Uqq fastbook从FAST导入所需的库
from fastbook import *目标
基本上,本报告中使用FAST AI的图像分类过程分为;
- 数据采集、标识和清理
- 数据加载器
- 数据增强
- 模型培训(精益)
- 误差分析
- 模型优化
数据集
使用从DuckDuckGo和Kaggle中丢弃的图像收集、标记和清理每类狗、猫和兔子的1000个数据集,并在将数据保存到GDrive上后将其分配为数据的路径。
paths=”/content/drive/My Drive/fastai/1000animaldata”数据加载器
数据加载器为模型提供批量数据,这些数据作为训练和验证数据集可用。根据FAST AI约定,20%的训练数据被指定用于验证我们的模型,但是,可以使用RandomSplitter参数根据偏好调整此信息。为了达到较高的精度,在FAST AI中使用DataBlockAPI创建DataLoader,其中挡路函数将我们的数据集信息作为独立的ImageBlock包含,数据标签作为依赖的CategoryBlock包含。
animals = DataBlock(blocks=(ImageBlock, CategoryBlock), get_items=get_image_files,splitter=RandomSplitter(valid_pct=0.2, seed=42),get_y=parent_label,item_tfms=Resize(128))数据自动生成
为了避免在模型训练期间过度拟合,通常建议实施数据增强或数据转换。数据增强指的是创建输入数据的随机变体,使它们看起来不同,但实际上不会改变数据的含义。常见的图像数据增强技术有旋转、翻转、透视扭曲、亮度改变和对比度改变。这通常使用aug_transforms函数来实现。默认情况下,在Fasai中,只增加训练数据集,而不增加验证集。
使用Resize函数,可以使用不同的调整大小方法,如挤压、裁剪、填充,但是,这种数据转换方法经常有问题,可能会导致丢失一些重要的细节,因此,Resize经常被替换为RandomResizedCrop,这是一种帮助聚焦和识别图像中不同特征的转换。对于本报告中的结果,使用了数据增强技术。
animal = animals.new(item_tfms=Resize(128), batch_tfms=aug_transforms(mult=4, do_flip=True, flip_vert=False, max_rotate=1.0, min_zoom=1.0, max_zoom=0.5, max_lighting=0.2, max_warp=0.05))
模范训练
在计算机视觉中,迁移学习通常是通过使用预先训练的模型来表示的。预先训练的模型是在像ImageNet这样的大型基准数据集上进行训练以解决与我们想要解决的问题类似的问题的模型。虽然在计算机视觉应用中也有其他的预训练模型,但RESNET图像分类器往往得到更多的应用,因为RESNET图像分类器在预训练模型时使用了不同类别的大量图像,从而携带了生成的权重和偏差,以便快速训练并根据训练中使用的新数据做出准确的预测。
- 如何在FAST AI中培训模特
深度学习模型具有多个隐含层,初始层只能识别简单的事物,这些简单事物的特征对预训练模型中的所有图像都是通用的。作为FAST AI中的惯例,为了使用作为基于预训练模型的RESNET图像分类器来训练新模型,模型的所有初始层将被冻结,而只有最后一层被解冻(learn.unFreeze(-1)),并且通过将权重初始化为随机值来训练以捕捉训练数据集的复杂特征,当自动计算损失函数时,将使用梯度进一步更新该随机值。为了提高我们训练的准确性,我们可以通过使用函数learn.unFreeze(-3)解冻和训练我们模型的其他更深层次的层来进行实验,这将解冻并训练最后三层,这个数字可以根据要训练的层的不同而变化。
RESNET是可用作最新图像分类模型的卷积神经网络。RESNET体系结构的示例包括具有表示层数的数字的resnet18、resnet34、resnet50、resnet101、resnet152。为了训练我们的模型,FAST AI库提供了FIT_ONE_CYCLE()和FINE_TUNE()等重要类。可以使用诸如学习率LR之类的超参数来提高精度,或者通过增加历元数来提高精度,直到验证损失显示出一些过拟合的迹象。该度量用于指示我们模型的错误率或准确性。
learn = cnn_learner(dls, resnet34, metrics=[error_rate,accuracy])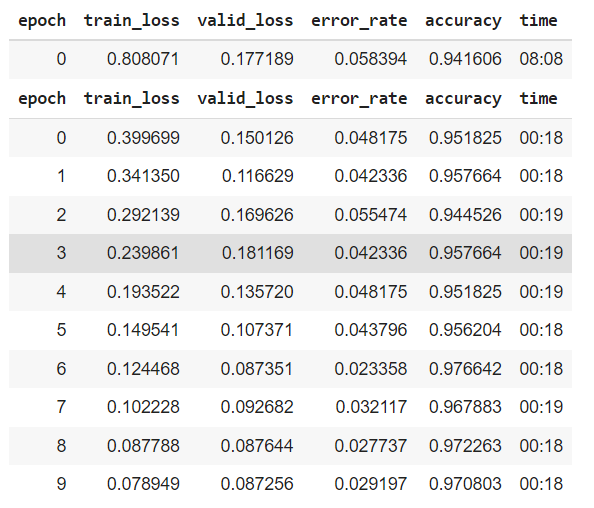
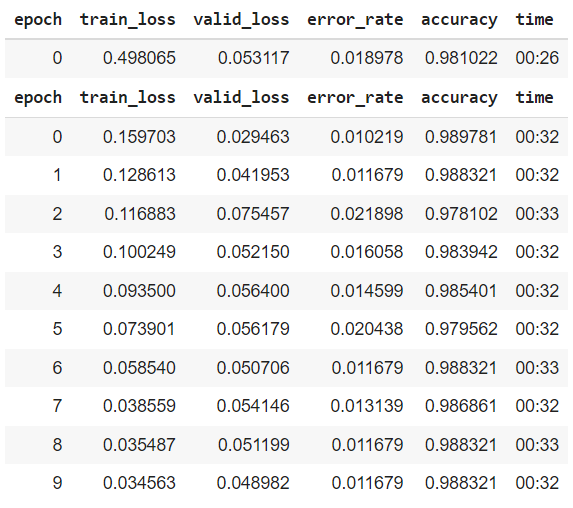
从上图的结果来看,图像大小和数据批次的加倍提高了模型的精度,这是因为随机梯度下降(SGD)被用作FAST AI中最小化损失/成本函数的优化器。SDG随机抽样少量的数据点,称为“小批量”,更新权值/参数并计算梯度,以提高精度和降低计算成本
误差分析
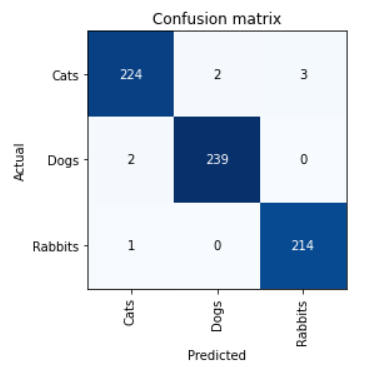
要检查模型预测的准确性,可以使用念力矩阵()和PLOT_TOP_LOSES()函数。
interp = ClassificationInterpretation.from_learner(learn)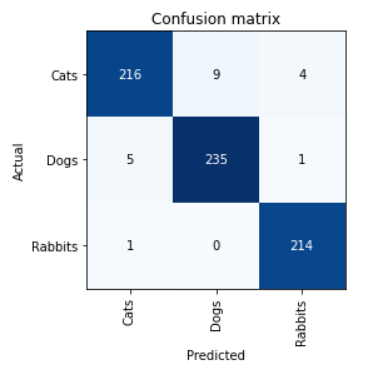
interp.plot_top_losses(8, nrows=1)模型优化
- 比较更深入的RESNET架构
RESNET被认为是为了解决神经网络深层的涂漆梯度问题。因此,层数较多的模型应该比层数较少的模型对输入数据有更好的概括性。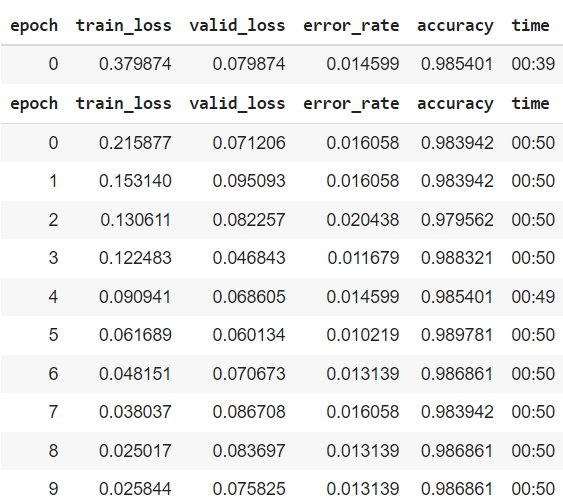
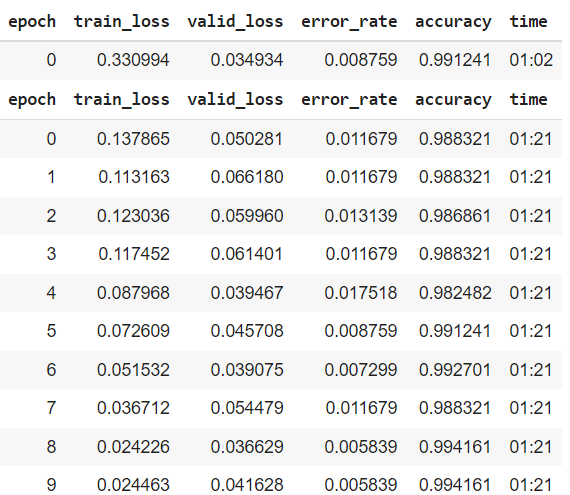
- 比较增加纪元数的效果
历元是所有训练向量被使用一次来更新权重的次数的度量。对于批量训练,在权值更新之前的一个时期内,所有训练样本同时通过学习算法,即训练数据集通过算法的一次完整通过。纪元数是算法的一个重要的超参数,因为它帮助我们使用来自训练和验证损失的结果来识别我们的模型何时过拟合,并帮助我们决定何时停止训练我们的模型。然而,对于本研究而言,在比较第10个历元和第100个历元的结果时,增加历元数对模型训练精度的影响不大。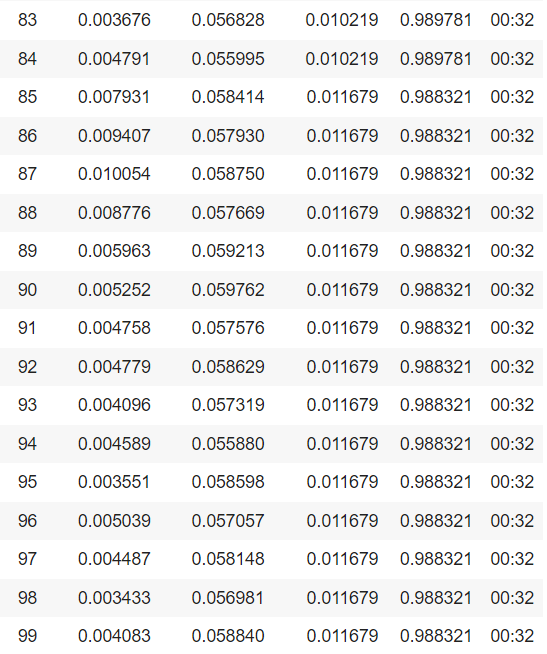
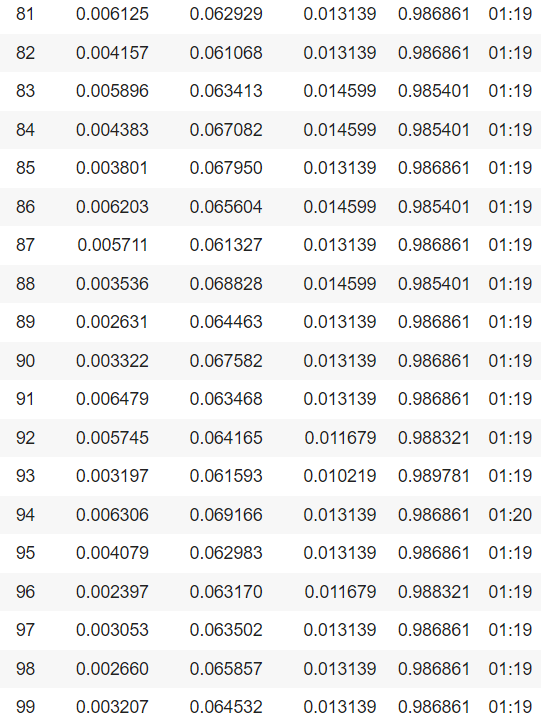
- 比较图像清理效果
使用分类器resnet34和resnet101在100个历元训练数据集后,两种分类器都给出了准确的结果,但由于隐藏层较多,resnet101的计算复杂度较高。因此,随后继续使用resnet34对模型进行训练。根据来自训练模型的顶部损失图的结果,使用ImageClassfierCleaner函数来清理损失较高的数据。
cleaner = ImageClassifierCleaner(learn34)然后使用取消已删除数据与数据路径的链接
for idx in cleaner.delete(): cleaner.fns[idx].unlink()虽然错误分类的数据使用
for idx,cat in cleaner.change(): shutil.move(str(cleaner.fns[idx]), paths/cat)然后,创建一个新的数据读取器,并重新训练模型以提高模型精度。该模型在Epoch20用resnet34进行了进一步的训练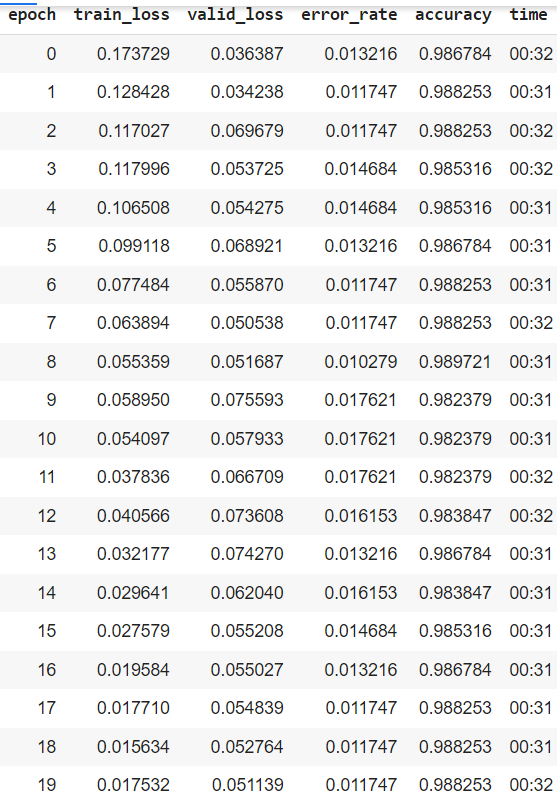
将模型保存并部署为Web应用程序
- 保存并导出模型
使用Learner.export保存并导出100纪元时的resnet34结果。它接受两个输入参数Learning和fname,以便导出模型并将其保存在GDrive上,特别是在您希望以后随时访问的文件夹/Content/GDrive/MyDrive/中。fname包含路径/Content/GDrive/MyDrive/+您导出的型号名称,扩展名为.pkl。导出的模型另存为PKL文件,该文件由PICKLE(Python模块)创建。/content/gdrive/MyDrive /content/gdrive/MyDrive
Learner.export(learn, fname=’/content/gdrive/MyDrive/animal-classification-new.pkl’)- 创建Web应用程序
使用Heroku软件为模型演示创建Web应用程序。
获取我的Heroku Web应用程序的链接,用于分类猫、狗和兔子。Get the link to my Heroku web application for Cats, Dogs and Rabbits classification.
- 上传您的模型
将扩展名为.pkl的模型下载到计算机上,然后将其上传到dropbox.com,并将Dropbox链接上传到先前创建的Heroku Web应用程序上。dropbox link 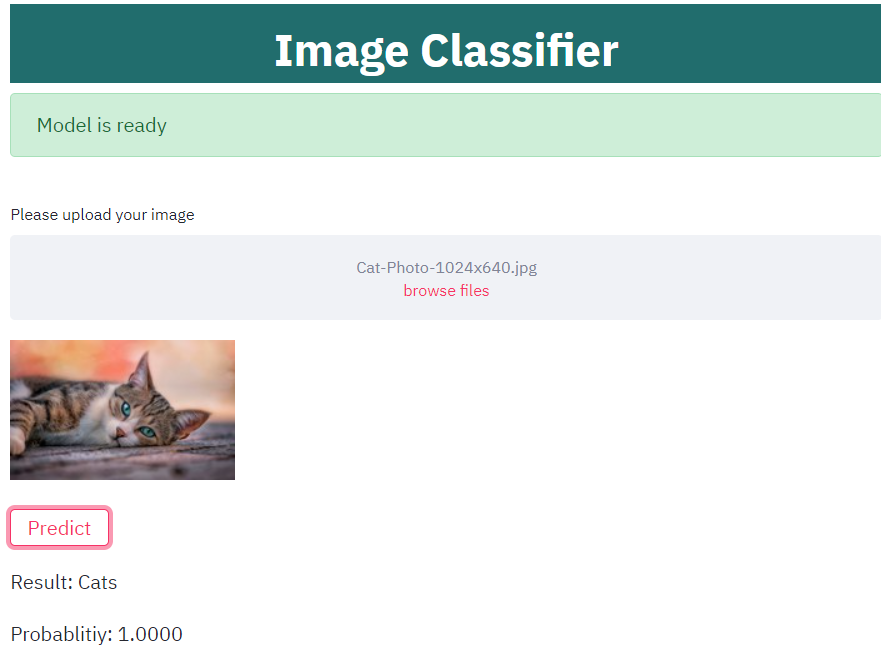
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/08/04/%e5%9f%ba%e4%ba%8efast-ai%e7%9a%84%e5%8a%a8%e7%89%a9%e5%88%86%e7%b1%bb/
