
来源 | Stanford University
整理 | fendouai
一、文本分类
1. 文本分类问题举例:
- 这是一个垃圾邮件吗?
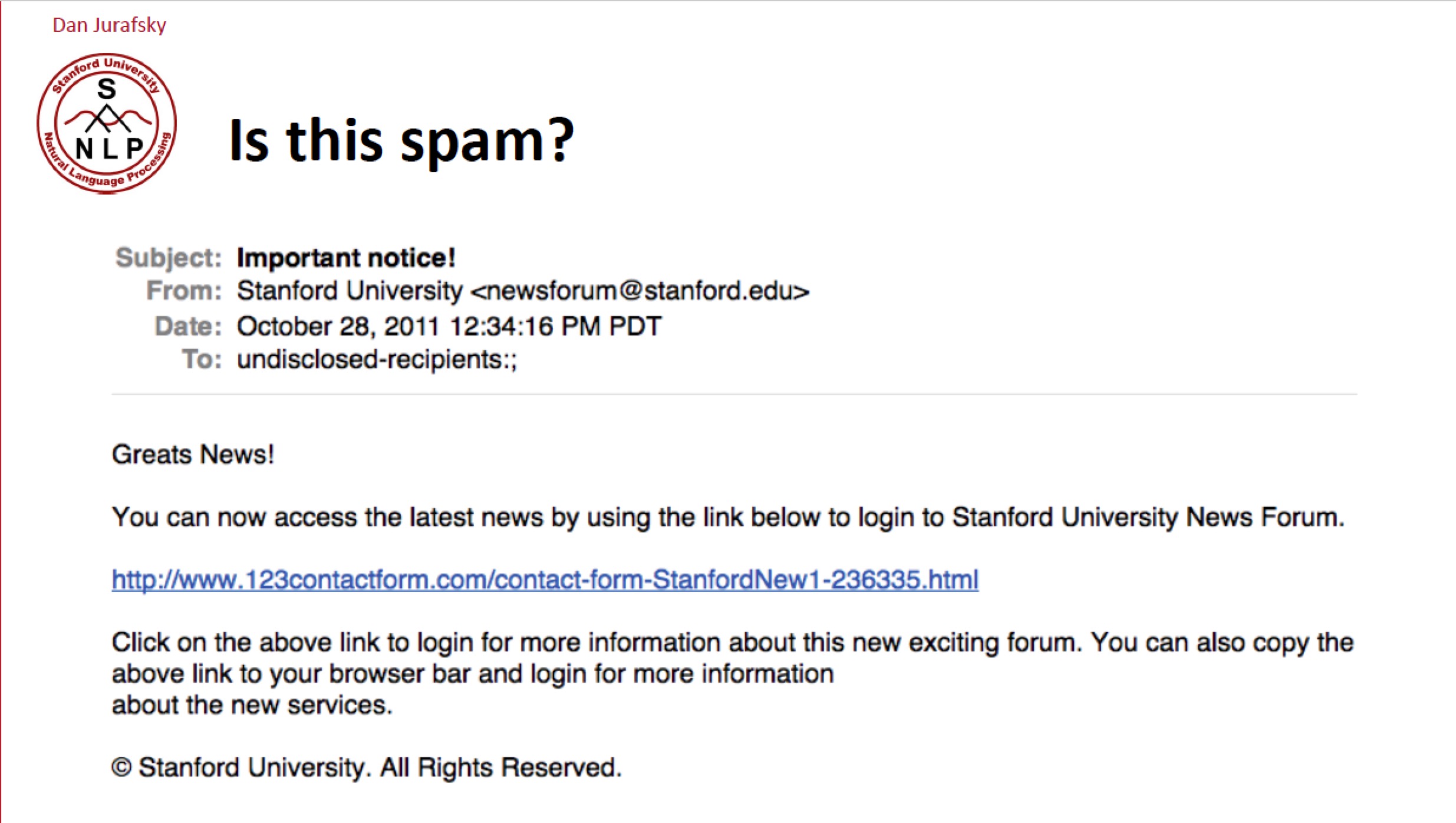
- 电影评价是正面的还是负面的?

- 这篇文章的主题是什么?

2. 文本分类的应用
- 给文章确定分类,主题,流派
- 垃圾文本检测
- 原创鉴定
- 年龄,性别鉴定
- 语言鉴定
- 情感分析

3. 定义文本分类
- 输入:
一个文本 d
一组分类 C={c1,c2,…, cJ}
- 输出:
一个预测的分类 c∈C
4. 分类方法
1)手写规则
- 黑名单邮件地址 或者 (元 或者 被选择)
- 如果规则是由专家定义的,准确率可能会很高。
- 但是建立和维护这些规则代价都是昂贵的。

2)有监督机器学习
- 输入:
一个文本 d
一组分类 C={c1,c2,…, cJ}
一个手动打标的训练集 (d1,c1),….,(dm,cm)
- 输出:
一个分类器 γ : d->c

- 分类器种类
a. 朴素贝叶斯
b. 逻辑回归
c. 支持向量机
d. K 近邻
二、朴素贝叶斯
1. 基于贝叶斯规则的简单分类方法
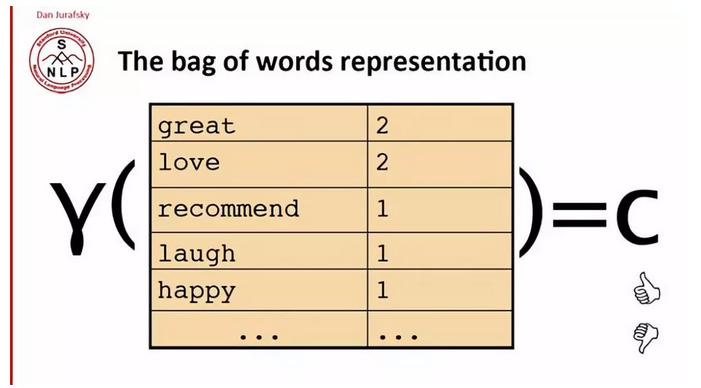
2. 依赖于简单的文本表示——词袋模型

1)词袋模型表示

2)词袋模型表示:使用单词的子集

词袋模型表示
3. 形式化朴素贝叶斯分类器
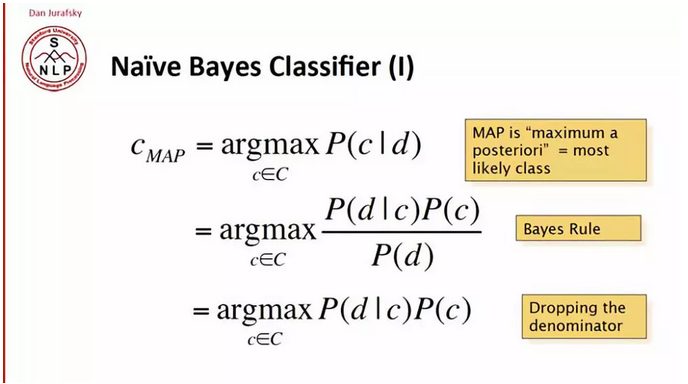
对于一个文档 d 和一个分类 c
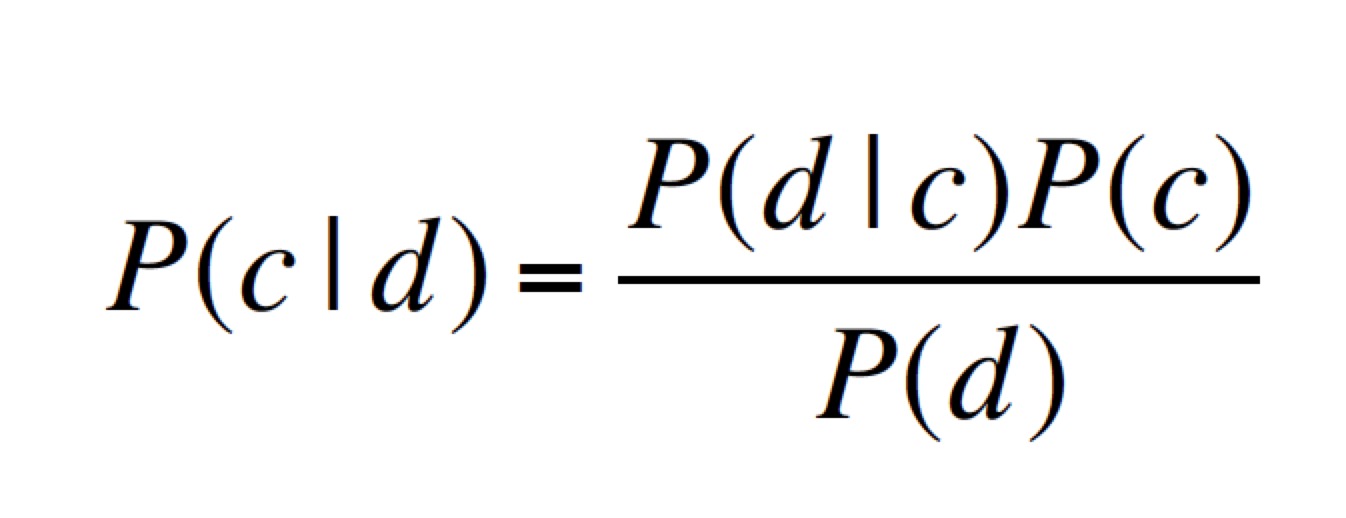

MAP 是最大化后验概率,或者说:最有可能的类别。
根据贝叶斯规则,转化为
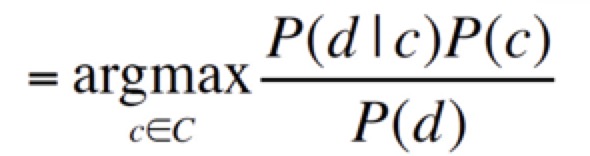
去掉共同的分母,转化为
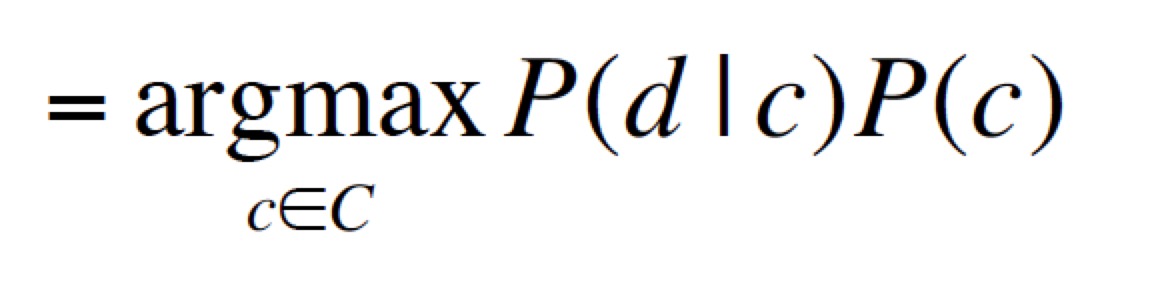
文档 d 表示为 特征 x1 .. xn

这个类别出现的概率是多少?我们可以只计算在语料中的相对的频率,这些参数是不是只有在非常非常大的训练集的情况下才能够确认。

4. 多项朴素贝叶斯独立假设
- 词袋模型假设:假设位置并不重要
- 条件假设:假设 特征概率 P(xi,cj)是独立的,在类别 c 给出的情况下。

可以推出以下等式:
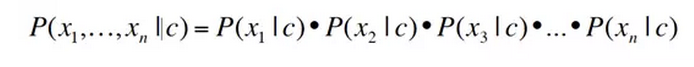
多项朴素贝叶斯分类器

三、应用多项朴素贝叶斯分类器到文本分类
positions 在测试文档中所有的词位置

编译自:
https://web.stanford.edu/class/cs124/lec/naivebayes.pdf
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2018/08/25/%e6%96%87%e6%9c%ac%e5%88%86%e7%b1%bb%e5%92%8c%e6%9c%b4%e7%b4%a0%e8%b4%9d%e5%8f%b6%e6%96%af%ef%bc%8c%e4%bd%a0%e7%9c%9f%e7%9a%84%e7%90%86%e8%a7%a3%e4%ba%86%e5%90%97%ef%bc%9f/
