
Kannada-MNIST:一个新的手写数字数据集
Kannada-MNIST:一个新的手写数字数据集
译者|VK
来源|Towards Data Science

TLDR:
我正在传播2个数据集:
Kannada-MNIST数据集:28×28灰度图像:60k 训练集 | 10k测试集
Dig-MNIST: 28×28灰度图像:10240(1024×10){见下图}

虽然这些数字符号是坎纳达(Kannada)语言,但是Kannada-MNIST数据集是为了替代MNIST数据集。
此外,我正在分发一个用同一种语言(主要是该语言的非本地用户)编写的10k个手写数字的额外数据集Dig-MNIST,可以用作额外的测试集。
资源列表:
GitHub👉: https://github.com/vinayprabhu/Kannada_MNIST
Kaggle👉: https://www.kaggle.com/higgstachyon/kannada-mnist
ArXiv👉 : https://arxiv.org/pdf/1908.01242.pdf
如果您在同行评审的论文中使用Kannada-MNIST,我们希望将其引用为:
Prabhu, Vinay Uday. “Kannada-MNIST: A new handwritten digits dataset for the Kannada language.” arXiv preprint arXiv:1908.01242 (2019)..
Bibtex:
[code lang=text]
@article{prabhu2019kannada,
title={Kannada-MNIST: A new handwritten digits dataset for the Kannada language},
author={Prabhu, Vinay Uday},
journal={arXiv preprint arXiv:1908.01242},
year={2019}
}
[/code]
介绍:
坎纳达语是印度卡纳塔克邦的官方行政语言,全球有近6000万人。此外,根据印度宪法第344(1)和351条,坎纳达语是印度22种预定语言之一。该语言是使用官方的坎纳达语脚本编写的,该脚本是Brahmic家族的元音附标文字,其起源可追溯到Kadamba脚本(公元325-550)。

不同的符号用于表示语言中的数字0-9,这些数字与当今世界许多地方流行的现代阿拉伯数字不同。与其他一些古老的数字系统不同,这些数字在卡纳塔克邦的日常生活中被大量使用,如下图所示,这些数字在车辆牌照上的普遍使用说明了这一点:

下图捕获以下现代字体中字体变化的MNIST化效果图:Kedage, Malige-i, Malige-n, Malige-b, Kedage-n, Malige-t, Kedage-t, Kedage-i, Lohit-Kannada, Sampige 和 Hubballi-Regular.

数据集策划:
Kannada-MNIST:
在印度班加罗尔招募了65名志愿者,他们是该语言的母语使用者和日常使用者。每位志愿者填写一张有着32×40网格的A3纸。每张A3纸包含每个数字的128个实例,我们假设它足够大以捕获大多数自然志愿者的字体的变化。使用Konica Accurio-Press-C6085扫描仪以600点/英寸的分辨率扫描得到了65张4963×3509的png图像。

Dig-MNIST:
我们招募了8名年龄在20到40岁之间的志愿者,这些志愿者在32×40格的纸上写坎纳达数字,所有人都用Z-Grip系列黑色墨水或者Zebra钢笔写在商业的Mead Cambridge Quad写字板上。写字板的参数为8–1/2″ x 11″,四边形,白色,80页/画本。然后我们使用戴尔-S3845cdn扫描仪进行扫描,扫描仪设置如下:
- 输出颜色:灰度
- 原始类型:文本
- 变淡/加深:加深+3
- 大小:自动检测
用于书写数字的纸张尺寸缩小了(US-letter与A3)使得扫描图像(.tif)更小,均约为1600×2000。
与MNIST比较:
1:平均像素强度分布
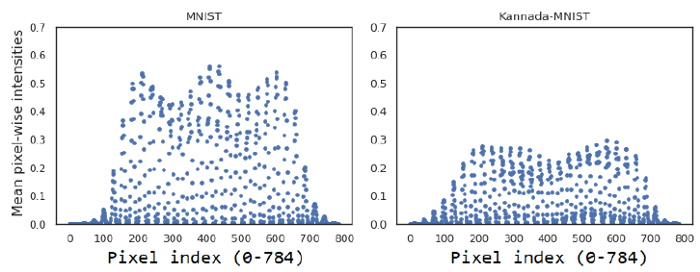
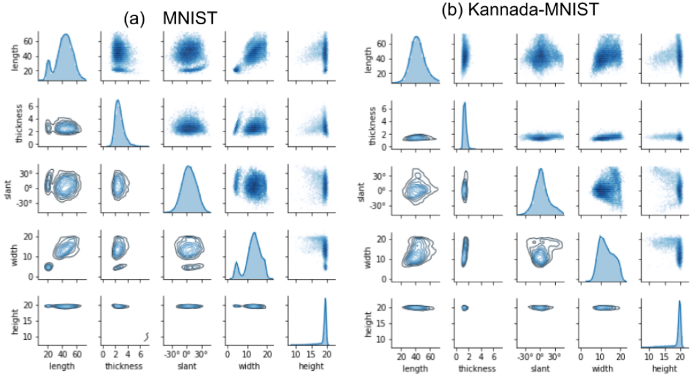
2:形态属性
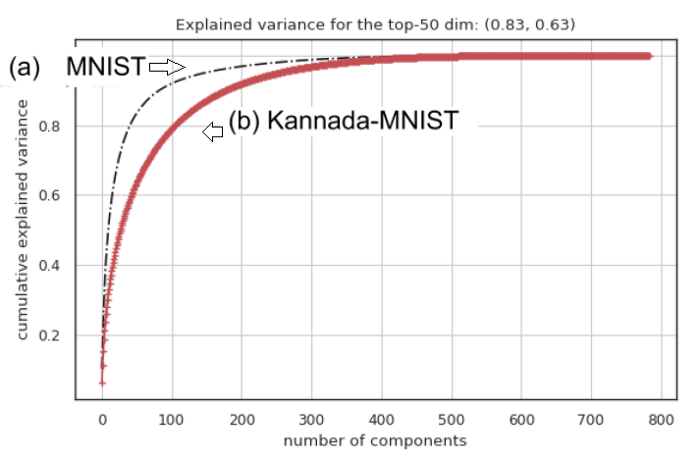
3:PCA分析
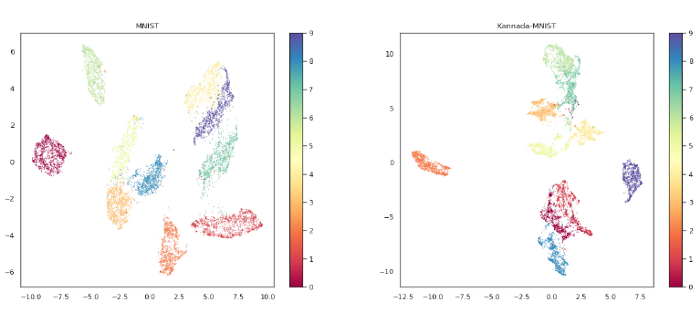
4:UMAP可视化
一些分类基准点:
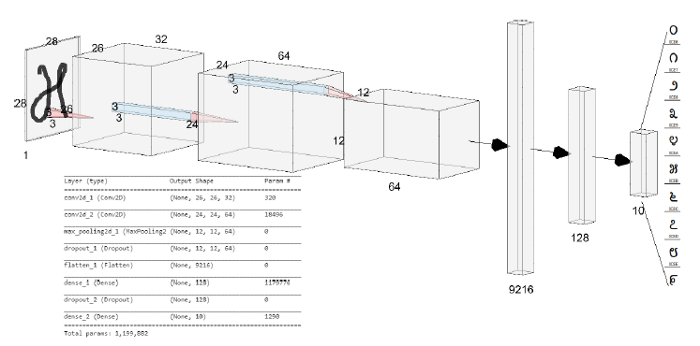
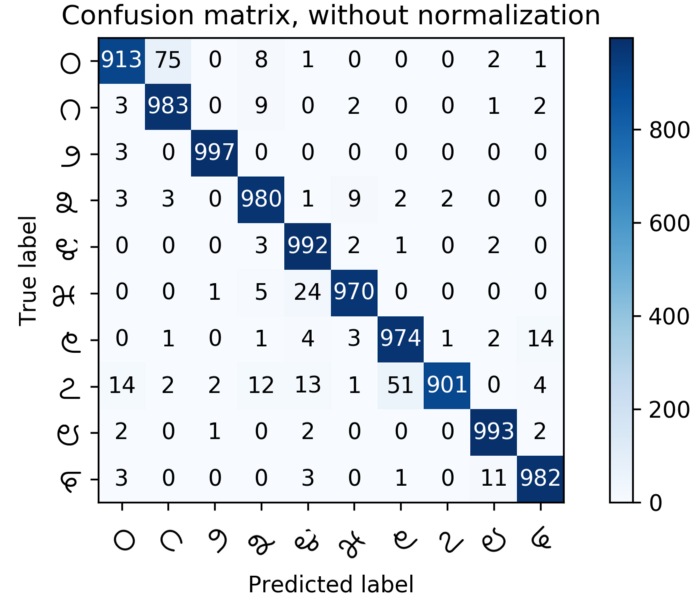
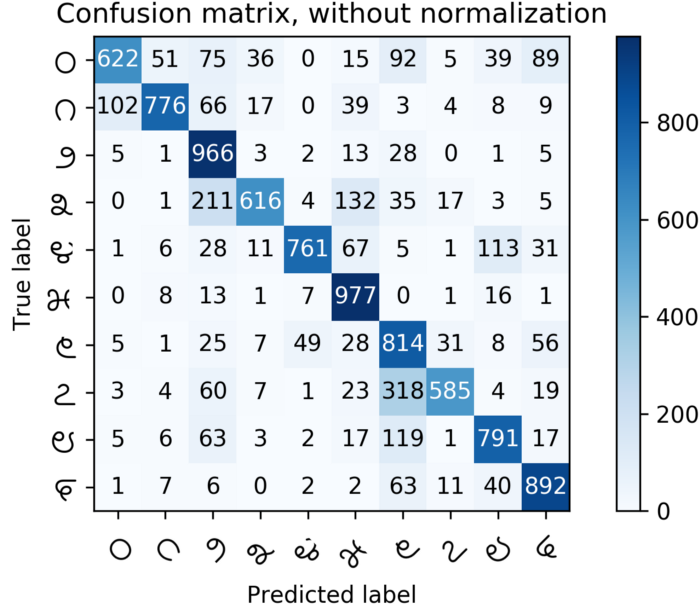
我使用标准的MNIST-cnn体系结构来获得一些基本的准确度基准(参见下图)
####(a) Kannada-MNIST训练集的训练以及Kannada-MNIST测试集的测试
####(b) Kannada-MNIST训练集的训练以及Dig-MNIST上的测试
###向机器学习社区开放挑战
我们向整个机器学习社区提出以下开放的挑战
- 当使用Kannada-MNIST对在MNIST上预训练的CNN进行再训练时,描述遗忘的特性。我们注意到,Kannada-MNIST中3和7的字形与MNIST中2的字形非常相似。
- 对使用字体1生成的纯合成数据进行训练,并进行增强,以实现Kannada-MNIST和Dig-MNIST数据集的高准确度。
- 跨不同的语言的来复制本文中描述的过程,特别是印度里的语言。
- 至于Dig-MNIST数据集,我们看到一些志愿者违反了网格的边界,因此一些图像要么只有部分字形或者笔划,要么从外观上可以说是它们可能属于两个不同类别中的任何一个。关于这些图像,值得看看我们是否可以设计一个分类器,将分配的softmax质量分配给候选类。
- 我们共享原始扫描图像背后的主要原因是促进对自动分割算法的研究,该算法将解析来自网格的各个数字图像,这可能反过来导致数据集的升级版本拥有更高质量的图像。
- 通过训练Kannada-MNIST数据集并在Dig-MNIST数据集上进行测试而无需借助图像预处理来实现MNIST级的准确度。
- Prabhu, Vinay Uday, Sanghyun Han, Dian Ang Yap, Mihail Douhaniaris, Preethi Seshadri, and John Whaley. “Fonts-2-Handwriting: A Seed-Augment-Train framework for universal digit classification.” arXiv preprint arXiv:1905.08633 (2019). [ https://arxiv.org/abs/1905.08633 ] ↩
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2019/08/20/kannada-mnist/
