

Kaggle
Kaggle是一个数据科学家共享数据、交换思想和比赛的平台。人们通常认为Kaggle不适合初学者,或者它学习路线较为坎坷。
没有错。它们确实给那些像你我一样刚刚起步的人带来了挑战。作为一个(初级)数据科学家,我忍不住要在Kaggle上搜索有趣的数据集来开始我的旅程。我了解了泰坦尼克号数据集。
泰坦尼克号
数据集包含泰坦尼克号上乘客的信息。
我使用Python来可视化和理解更多关于数据集的信息。我用scikit-learn训练了一组分类器来预测一个人的生存几率。然后使用pickle保存模型,并使用Flask将其部署为本地主机上的Web应用程序。最后,我利用AWS来托管它。
代码可以在GitHub上找到。

1.数据检查
首先第一件事。我将数据导入了pandas的DataFrame。它包括乘客身份、存活时间、船票等级、姓名、性别、年龄、船上兄弟姐妹和配偶人数、船上父母和子女人数、船票号码、乘客车费、客舱号码和登船港,前5行数据如图。

可以立即观察到的是:
-每行的PassengerID都是唯一的,
–Survived是我们想要推断的目标
–Name可能没用
–Ticket是票务数据
-如果Ticket有缺失就被标记为NaN。
为了简单起见,我决定暂时放弃Ticket字段。这些字段可能包含有用的信息,但是需要大量的特征工程来提取它们。我们先从最简单的第一步开始。
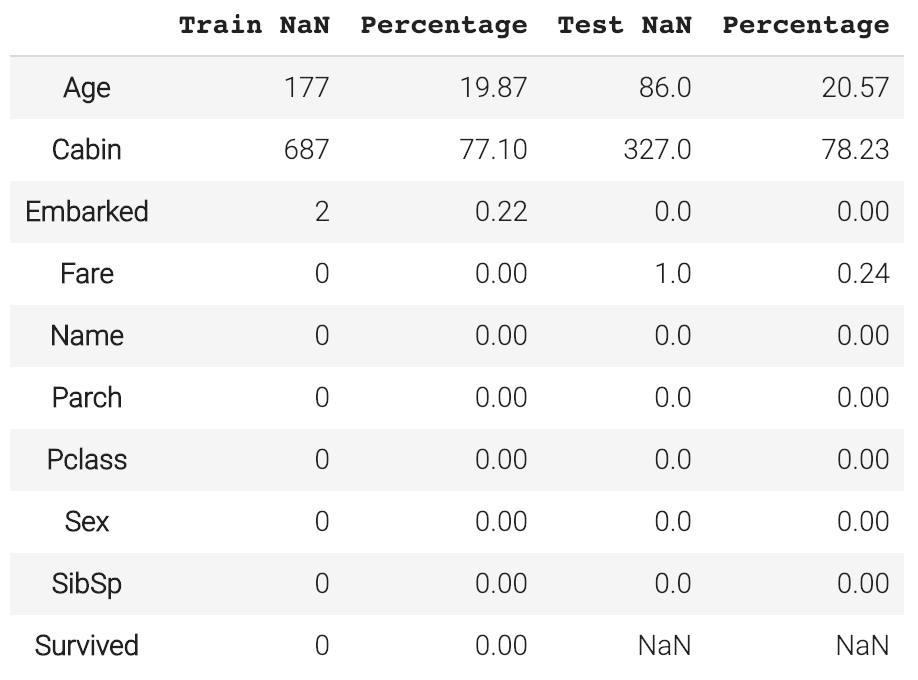
另一方面,让我们仔细看看缺失的数据。在变量Embarked和Fare中有一些缺失的条目。另一方面,约20%的乘客年龄没有被记录。这可能会给我们带来一个问题,因为Age可能是数据集中的关键预测因素之一。“妇女和儿童优先”是当时的行为准则,报告显示,他们确实是先得救的。Cabin大于77%的条目是缺失的,不大可能有帮助,我们先把它去掉。
2.数据可视化
Pair图(下面没有显示)通常是我在数据可视化任务开始时的首选,因为它通常很有帮助,而且它代码少。一行seaborn.pairplot()给你$n^2$的图(准确的是$n(n+1)/2$不同的图),其中n代表变量的数量。它让你对每一对变量之间的关系,以及每一个变量本身的分布有一个基本的了解。让我们研究一下不同的变量。
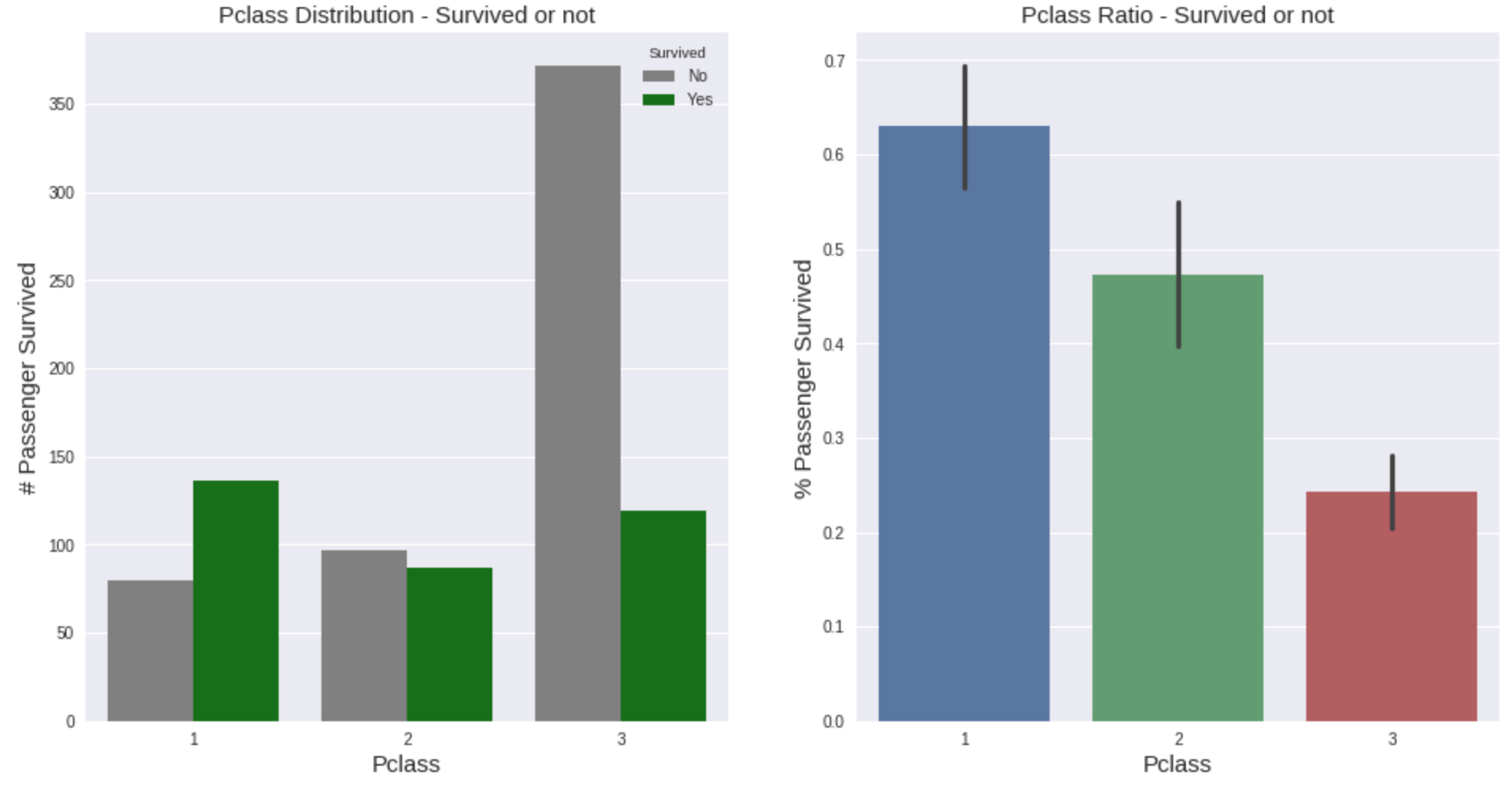
首先逐项检验目标变量与预测因子Survived的关系。通过seaborn.countplot(),我们发现大多数人属于第三类,这并不奇怪;一般来说,他们生存的可能性更低。即使有了这个单一的预测器,在其他一切未知的情况下,我们也可以推断,头等舱乘客生还的可能性更大,而三等舱乘客生还的可能性不大。
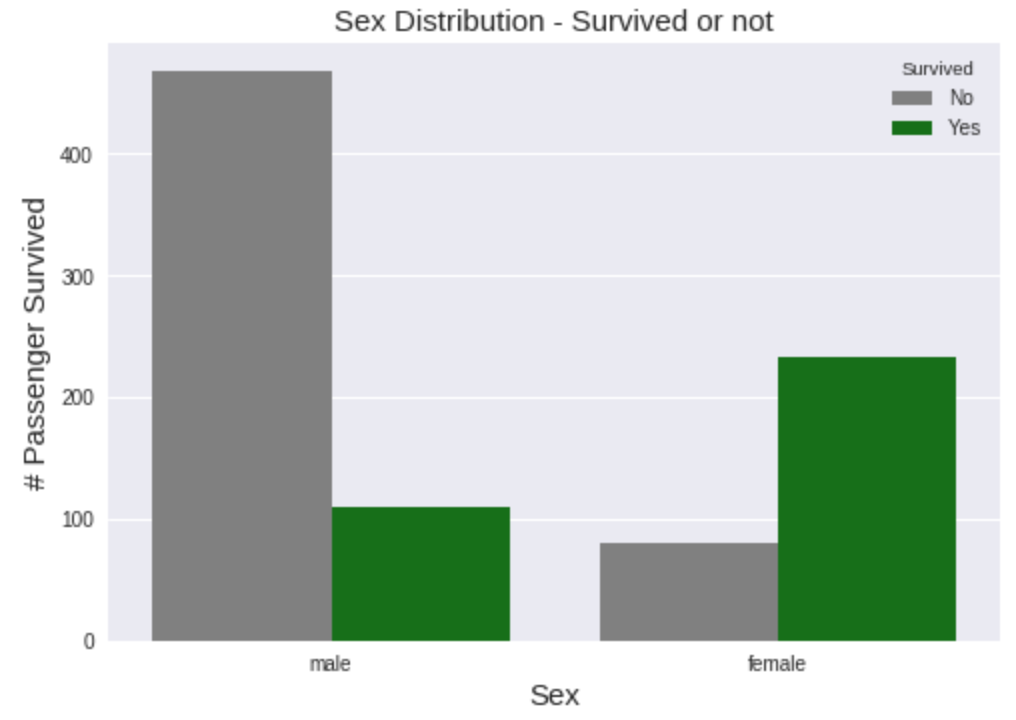
与此同时,妇女和儿童更有可能生存下来,这与前面提到的“妇女和儿童优先”理论相一致。如果我们只检查三个变量Pclass、Sex和Age,头等舱的年轻女性乘客将是最有可能存活下来的。
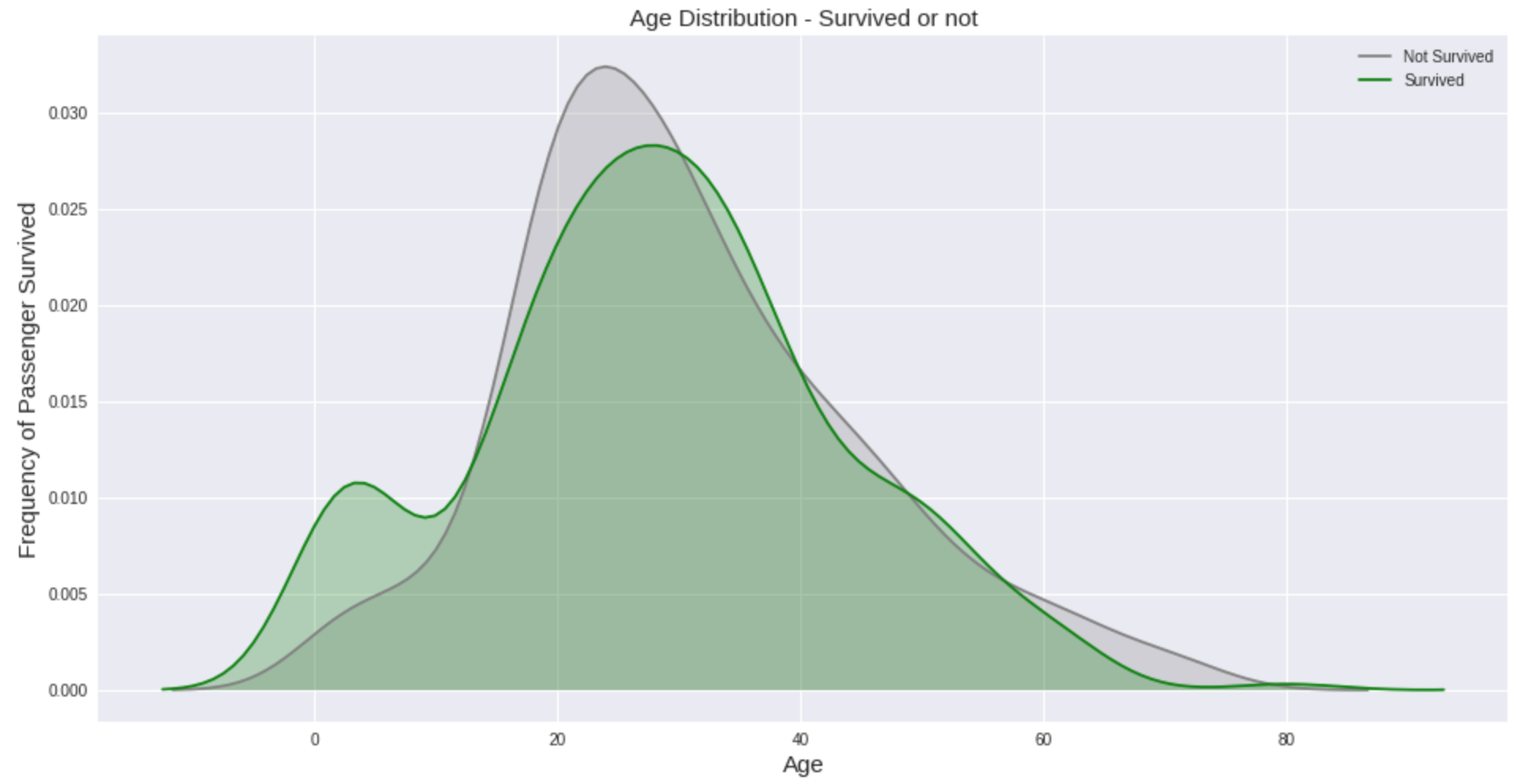
然而,可能很难解释密度图seaborn.kdeplot()。对于“幸存”和“未幸存”这两个类别,它们的跨度很广,而“未幸存”类别的平均值和方差较小。值得注意的是,在“幸存”类的分配中有一个有趣的尾部,即三个人以每人512美元的价格获得头等舱船票。他们都是在瑟堡港上船的,都活了下来。
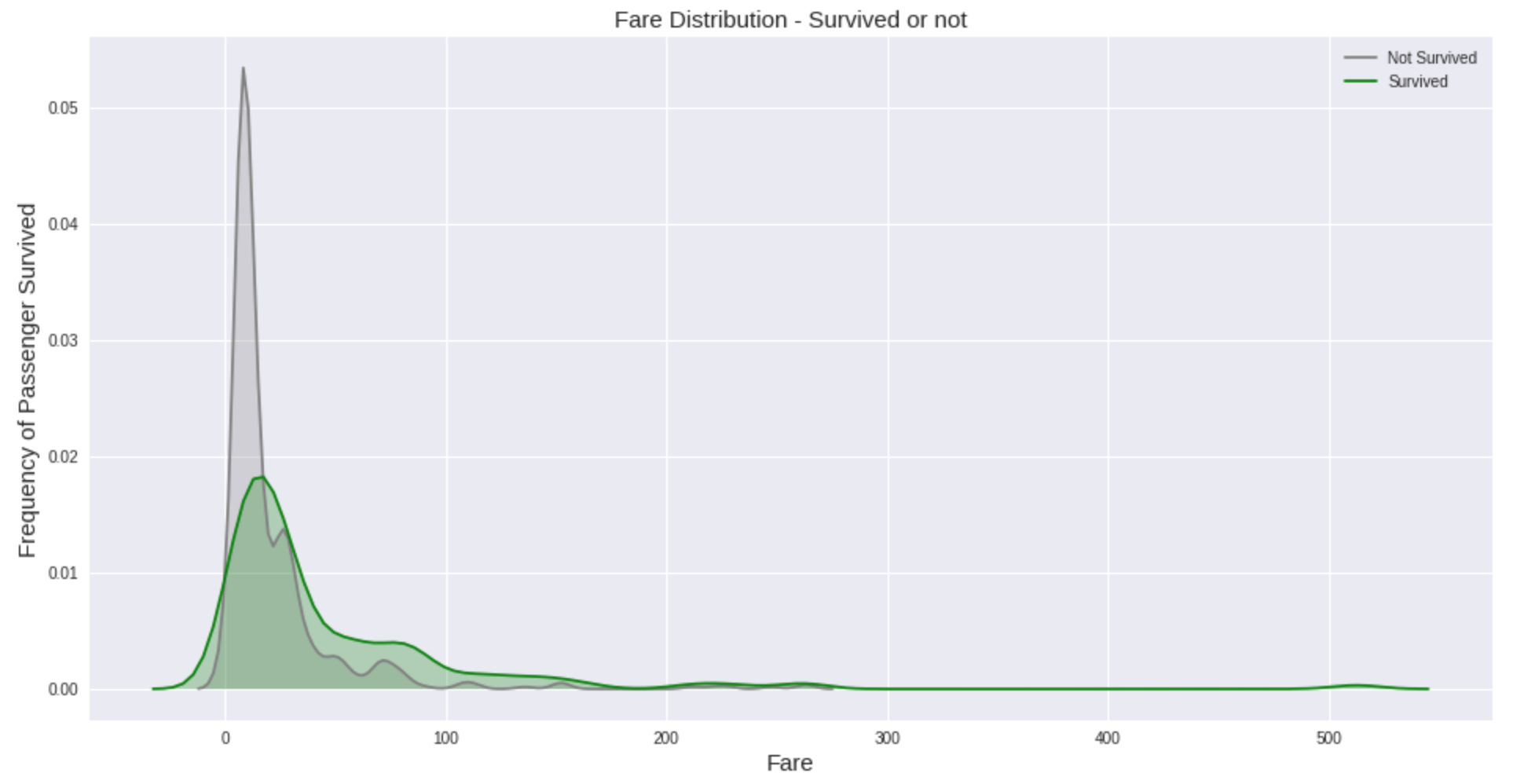
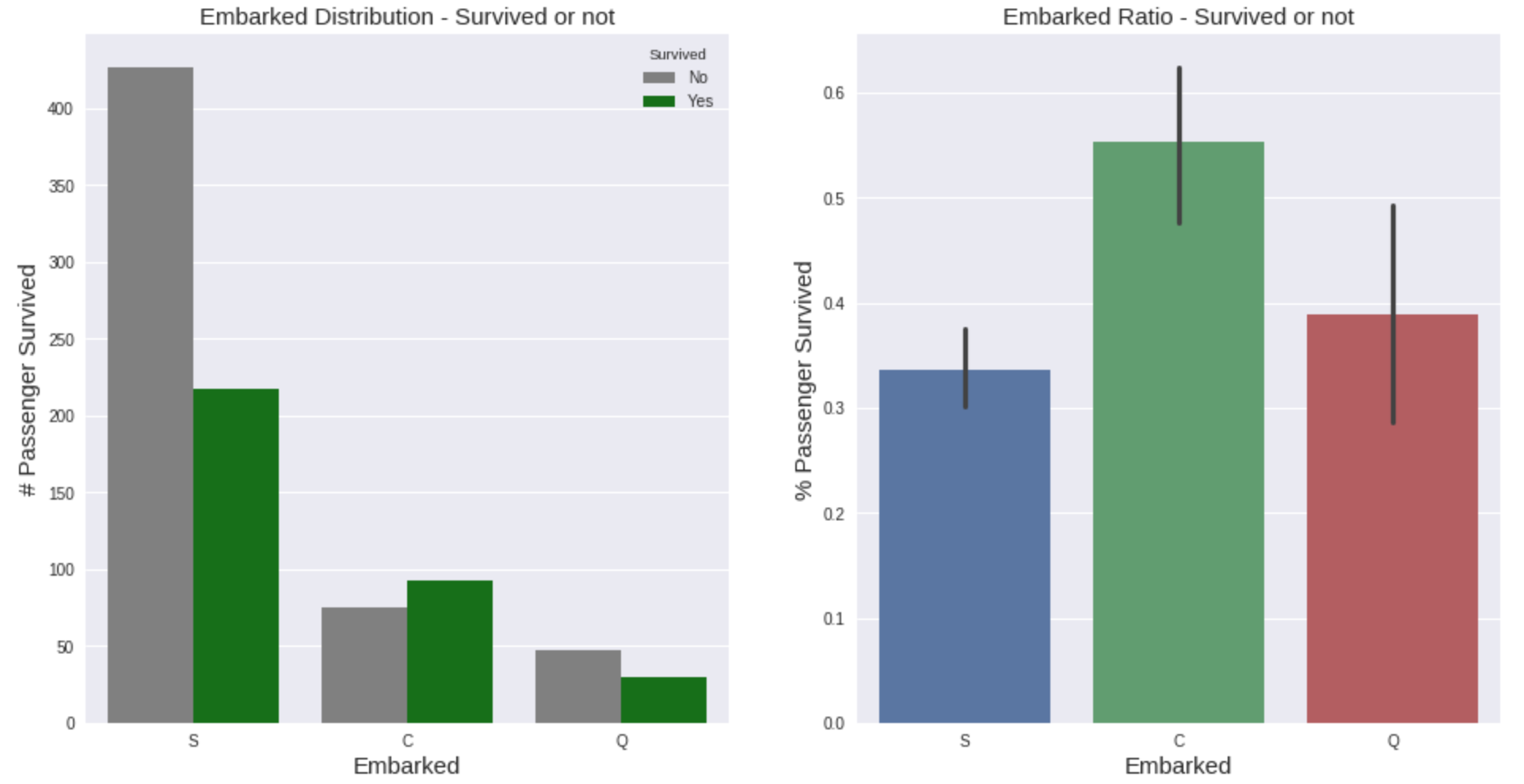
另一方面,embarkation似乎也在决定谁能活下来方面发挥了作用。大多数人在南安普顿港上船——这是旅程的第一站,他们的存活率最低。也许他们被分配到离出口更远的船舱里,或者花更多的时间在游轮上可以让人们放松或疲劳。或者它只是由第三个变量间接造成的——比如在第一个港口登机的女性/儿童/头等舱乘客更少。还需要进一步的调查。
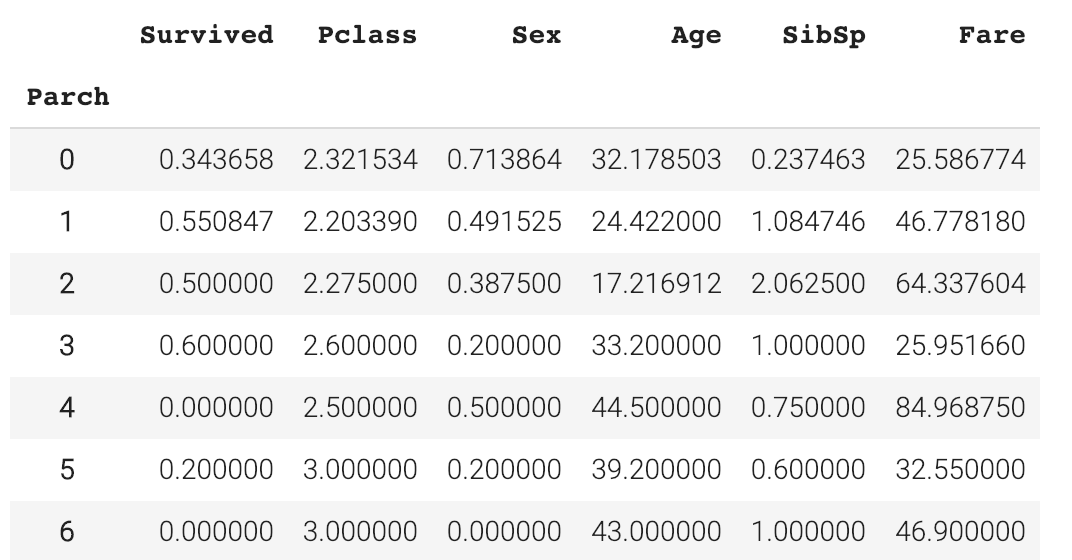
如果你喜欢表而不是图,我们还可以通过pandas.DataFrame.groupby()可视化数据,并对每个类取平均值。然而,我不认为下面的Parch表中有一个清晰的模式。
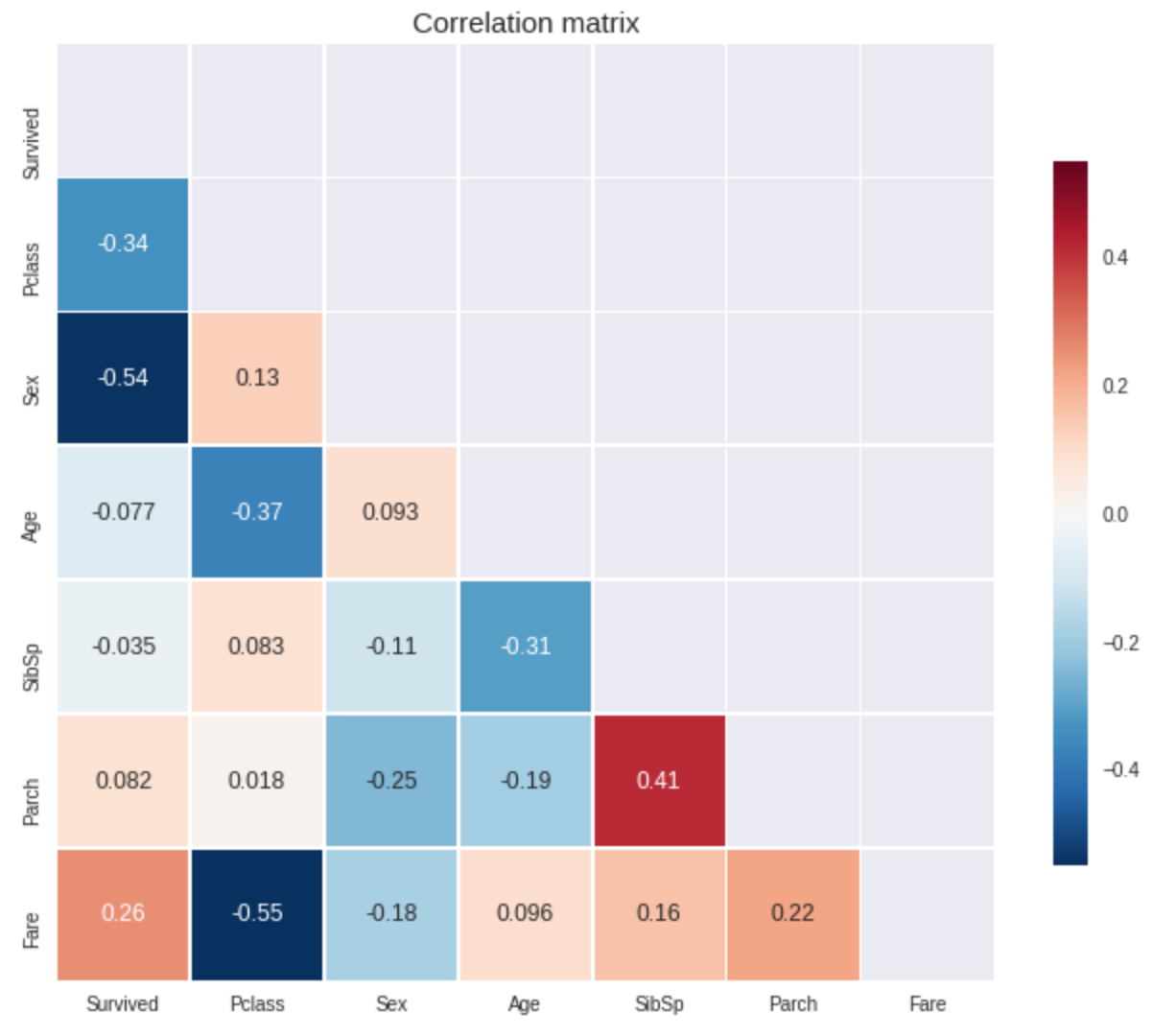
由seaborn.heatmap()生成的相关矩阵说明了任意两个变量之间的相关强度。如你所见,Sex与Survived的相关性最高,而Fare和Pclass高度相关。SibSp和Parch在预测一个人的生存机会上似乎没有起到很大的作用,尽管我们的直觉告诉我们不是这样的。
3.缺失的数据填充
我们在之前的数据检查中发现有很多数据项丢失。例如,我们似乎不知道60岁的托马斯·斯托里(ThomasStorey)花了多少钱买票。直觉告诉我们,船票票价在很大程度上取决于船票等级和登机港,我们可以用上面的相关矩阵进行交叉检验。因此,我们只取南安普顿三等舱票价的平均值。这只是一个有根据的猜测,可能是错误的,但它已经足够好了。记住,要获得无噪声的数据是不可能的,机器学习模型应该对噪声具有鲁棒性。
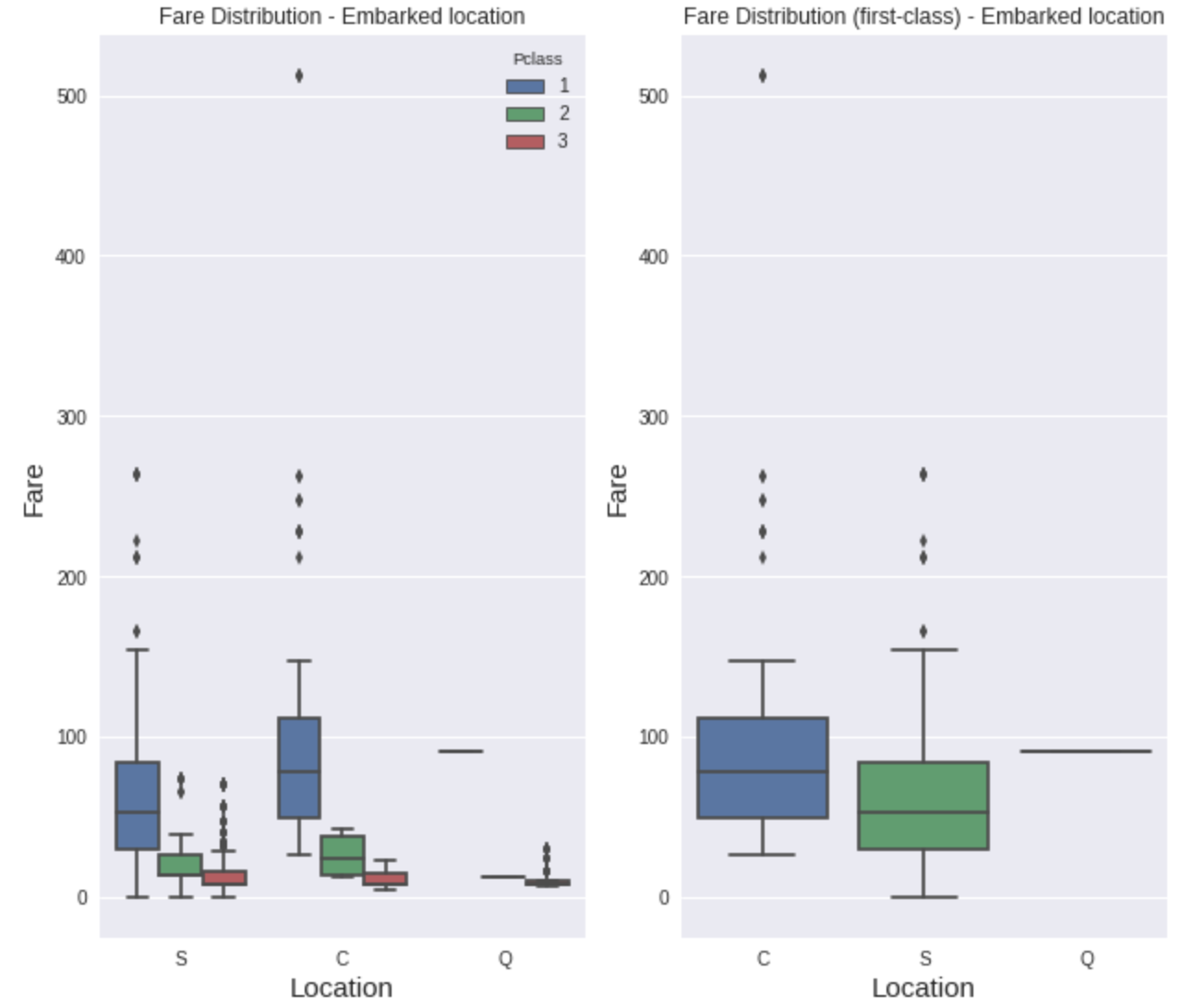
还有两个女人,我们不知道她们上了船。票的等级与票价密切相关。由于她们两人都花了80美元买了头等舱的座位,我猜是在瑟堡(图中的C)。
如果在一个特定的变量中只有很少的缺失项,我们可以使用上面的技巧,通过取最大似然值来进行有根据的猜测。尽管如此,如果我们丢失的数据更多的话,做同样的事情是非常危险的,比如Age缺失了20%。
我们目前能猜测的已经猜测完了。由于我们丢弃了Cabin,并且填入了其他缺失的条目,所以我们可以利用所有其他变量,通过随机森林回归变量来推断缺失的Age。80%的“训练”数据可以推断出剩下的20%。
4.特征工程
虽然其中大多数的头衔是“先生”、“夫人”和“小姐”,但也有一些不太常见的头衔——“博士”、“牧师”、“上校”等,其中一些只出现过一次,如“女士”、“多纳”、“上校”等。他们罕见的头衔对模型训练没什么帮助。为了找到模式,你需要数据。让我们把那些相对罕见的标题归类为“罕见”。
分类数据在模型训练之前需要格外小心。分类器无法处理字符串输入,如“Mr”、“Southampton”等。虽然我们可以将它们映射到整数,比如(‘Mr’、’Miss’、’Mrs’、’Rare’)→(1,2,3,4),但是不应该有头衔等级的概念。当医生并不意味着你就高人一等。为了不误导机器并意外地构造出一个性别歧视的人工智能,我们应该对它们进行一次one-hot编码。他们成为:
((1,0,0,0),(0,1,0,0),(0,0,1,0),(0,0,0,1))
另一方面,我决定增加两个变量——FamilySize和IsAlone。加上FamilySize=SibSp+Parch+1更有意义,因为整个家庭都会在游轮上待在一起。此外,孤独可能是一个关键因素。你可能更容易做出鲁莽的决定,或者你可以在不照顾家人的情况下在灾难中更加灵活。通过一次添加一个变量,我发现它们在模型中的存在提高了整体的可预测性。

5.模型评估
我尝试了我所知道的最流行的分类器——随机森林、支持向量机、KNN、AdaBoost等等。
XGBoost最终以87%的测试精度脱颖而出。为了提高分类器的鲁棒性,我们训练了一组不同性质的分类器,并通过多数投票得到最终结果。
最后,我把它提交给Kaggle,获得了80%的准确率。不坏。总有改进的余地。
例如,在Cabin和Ticket中肯定隐藏了一些有用的信息,但是为了简单起见,我们放弃了它们。我们还可以创建更多的特征
但我暂时先不谈这个。
6.部署为Web应用程序
在Python中,Flask是一个易于使用的web框架。
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello():
return "Write something here.
"
app.run(host='0.0.0.0', port=60000)
你可以在本地主机中浏览它。

我们还需要什么?我们希望人们填写一个表单来收集所需的数据并将其传递给机器学习模型。模型将有一个输出,我们将把用户重定向到该页面。
我们将使用WTForms在Python中构建一个表单,单个表单由一个类定义,它看起来像下面这样:
from wtforms import Form, TextField, validators, SubmitField, DecimalField, IntegerField, SelectField
class ReusableForm(Form):
sex = SelectField('Sex:',choices=[('1', 'Male'), ('0', 'Female') ],
validators=[validators.InputRequired()])
fare = DecimalField('Passenger Fare:',default=33,places=1,
validators=[validators.InputRequired(),
validators.NumberRange(min=0,
max=512,
message='Fare must be between 0 and 512')])
submit = SubmitField('Predict')
我找到了一个来自WillKoehrsen的HTML模板,并在其上进行了构建。
7.云托管
现在网页可以通过我的本地主机查看,一切正常。最后一步是在线托管。现在有三种主要的云托管服务——AWS、GCP和Azure。AWS是目前最受欢迎的,所以我选择了12个月的免费服务。
我使用我的私有密钥连接到Linux服务器实例,将我的存储库迁移到服务器,运行我的脚本,它工作了!

对我来说不太好…

原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/02/28/%e4%bd%a0%e8%83%bd%e5%9c%a8%e6%b3%b0%e5%9d%a6%e5%b0%bc%e5%85%8b%e5%8f%b7%e4%b8%8a%e6%b4%bb%e4%b8%8b%e6%9d%a5%e5%90%97%ef%bc%9fkaggle%e7%9a%84%e7%bb%8f%e5%85%b8%e6%8c%91%e6%88%98/
