
作者|Daulet Nurmanbetov
编译|VK
来源|Towards Data Science

你有没有曾经需要把一份冗长的文件归纳成摘要?或者为一份文件提供一份摘要?如你所知,这个过程对我们人类来说是乏味而缓慢的——我们需要阅读整个文档,然后专注于重要的句子,最后,将句子重新写成一个连贯的摘要。
这就是自动摘要可以帮助我们的地方。机器学习在总结方面取得了长足的进步,但仍有很大的发展空间。通常,机器摘要分为两种类型
摘要提取:如果重要句子出现在原始文件中,提取它。

总结摘要:总结文件中包含的重要观点或事实,不要重复文章里的话。这是我们在被要求总结一份文件时通常会想到的。

我想向你展示最近的一些结果,用BERT_Sum_Abs总结摘要,Yang Liu和Mirella Lapata的工作Text Summarization with Pretrained Encoders:https://arxiv.org/pdf/1908.08345.pdf
BERT总结摘要的性能
摘要旨在将文档压缩成较短的版本,同时保留其大部分含义。总结摘要任务需要语言生成能力来创建包含源文档中没有的新单词和短语的摘要。摘要抽取通常被定义为一个二值分类任务,其标签指示摘要中是否应该包含一个文本范围(通常是一个句子)。
下面是BERT_Sum_Abs如何处理标准摘要数据集:CNN和Daily Mail,它们通常用于基准测试。评估指标被称为ROGUE F1分数
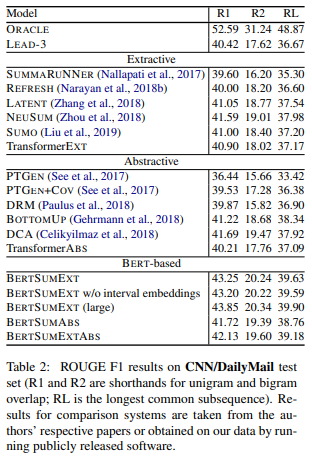
结果表明,BERT_Sum_Abs模型的性能优于大多数基于非Transformer的模型。更好的是,模型背后的代码是开源的,实现可以在Github上获得(https://github.com/huggingface/transformers/tree/master/examples/summarization/bertabs)。
示范和代码
让我们通过一个例子来总结一篇文章。我们将选择以下文章来总结摘要,美联储官员说,各国央行行长一致应对冠状病毒。这是全文
The Federal Reserve Bank of New York president, John C. Williams, made clear on Thursday evening that officials viewed the emergency rate cut they approved earlier this week as part of an international push to cushion the economy as the coronavirus threatens global growth.
Mr. Williams, one of the Fed’s three key leaders, spoke in New York two days after the Fed slashed borrowing costs by half a point in its first emergency move since the depths of the 2008 financial crisis. The move came shortly after a call between finance ministers and central bankers from the Group of 7, which also includes Britain, Canada, France, Germany, Italy and Japan.
“Tuesday’s phone call between G7 finance ministers and central bank governors, the subsequent statement, and policy actions by central banks are clear indications of the close alignment at the international level,” Mr. Williams said in a speech to the Foreign Policy Association.
Rate cuts followed in Canada, Asia and the Middle East on Wednesday. The Bank of Japan and European Central Bank — which already have interest rates set below zero — have yet to further cut borrowing costs, but they have pledged to support their economies.
Mr. Williams’s statement is significant, in part because global policymakers were criticized for failing to satisfy market expectations for a coordinated rate cut among major economies. Stock prices temporarily rallied after the Fed’s announcement, but quickly sank again.
Central banks face challenges in offsetting the economic shock of the coronavirus.
Many were already working hard to stoke stronger economic growth, so they have limited room for further action. That makes the kind of carefully orchestrated, lock step rate cut central banks undertook in October 2008 all but impossible.
Interest rate cuts can also do little to soften the near-term hit from the virus, which is forcing the closure of offices and worker quarantines and delaying shipments of goods as infections spread across the globe.
“It’s up to individual countries, individual fiscal policies and individual central banks to do what they were going to do,” Fed Chair Jerome H. Powell said after the cut, noting that different nations had “different situations.”
Mr. Williams reiterated Mr. Powell’s pledge that the Fed would continue monitoring risks in the “weeks and months” ahead. Economists widely expect another quarter-point rate cut at the Fed’s March 18 meeting.
The New York Fed president, whose reserve bank is partly responsible for ensuring financial markets are functioning properly, also promised that the Fed stood ready to act as needed to make sure that everything is working smoothly.
Since September, when an obscure but crucial corner of money markets experienced unusual volatility, the Fed has been temporarily intervening in the market to keep it calm. The goal is to keep cash flowing in the market for overnight and short-term loans between banks and other financial institutions. The central bank has also been buying short-term government debt.
“We remain flexible and ready to make adjustments to our operations as needed to ensure that monetary policy is effectively implemented and transmitted to financial markets and the broader economy,” Mr. Williams said Thursday.首先,我们需要获取模型代码,安装依赖项并下载数据集,如下所示,你可以在自己的Linux计算机上轻松执行这些操作:
# 安装Huggingface的Transformers
git clone https://github.com/huggingface/transformers && cd transformers
pip install .
pip install nltk py-rouge
cd examples/summarization
#------------------------------
# 下载原始摘要数据集。代码从Linux上的谷歌驱动器下载
wget --save-cookies cookies.txt --keep-session-cookies --no-check-certificate 'https://drive.google.com/uc?export=download&id=0BwmD_VLjROrfTHk4NFg2SndKcjQ' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/Code: \1\n/p'
wget --load-cookies cookies.txt --no-check-certificate 'https://drive.google.com/uc?export=download&confirm=<CONFIRMATION CODE HERE>&id=0BwmD_VLjROrfTHk4NFg2SndKcjQ' -O cnn_stories.tgz
wget --save-cookies cookies.txt --keep-session-cookies --no-check-certificate 'https://drive.google.com/uc?export=download&id=0BwmD_VLjROrfM1BxdkxVaTY2bWs' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/Code: \1\n/p'
wget --load-cookies cookies.txt --no-check-certificate 'https://drive.google.com/uc?export=download&confirm=<CONFIRMATION CODE HERE>&id=0BwmD_VLjROrfM1BxdkxVaTY2bWs' -O dailymail_stories.tgz
# 解压文件
tar -xvf cnn_stories.tgz && tar -xvf dailymail_stories.tgz
rm cnn_stories.tgz dailymail_stories.tgz
#将文章移动到一个位置
mkdir bertabs/dataset
mkdir bertabs/summaries_out
cp -r bertabs/cnn/stories dataset
cp -r bertabs/dailymail/stories dataset
# 选择要总结摘要的文章子集
mkdir bertabs/dataset2
cd bertabs/dataset && find . -maxdepth 1 -type f | head -1000 | xargs cp -t ../dataset2/在执行了上面的代码之后,我们现在执行下面所示的python命令来总结/dataset2目录中的文档摘要:
python run_summarization.py \
--documents_dir bertabs/dataset2 \
--summaries_output_dir bertabs/summaries_out \
--batch_size 64 \
--min_length 50 \
--max_length 200 \
--beam_size 5 \
--alpha 0.95 \
--block_trigram true \
--compute_rouge true这里的参数如下
documents_dir,文档所在的文件夹
summaries_output_dir,写入摘要的文件夹。默认为文档所在的文件夹
batch_size,用于训练的每个GPU/CPU的batch大小
beam_size,每个示例要开始的集束数
block_trigram,是否阻止由集束搜索生成的文本中重复的trigram
compute_rouge,计算评估期间的ROUGE指标。仅适用于CNN/DailyMail数据集
alpha,集束搜索中长度惩罚的alpha值(值越大,惩罚越大)
min_length,摘要的最小标记数
max_length,摘要的最大标记数
BERT_Sum_Abs完成后,我们获得以下摘要:
The Fed slashed borrowing costs by half a point in its first emergency move since the depths of the 2008 financial crisis. Rate cuts followed in Canada, Asia and the Middle East on Wednesday. The Bank of Japan and European Central Bank have yet to further cut borrowing costs, but they have pledged to support their economies.得到的摘要如下
The research team focused on the Presymptomatic period during which prevention may be most effective. They showed that communication between brain regions destabilizes with age, typically in the late 40's, and that destabilization associated with poorer cognition. The good news is that we may be able to prevent or reverse these effects with diet, mitigating the impact of encroaching Hypometabolism by exchanging glucose for ketones as fuel for neurons.结论
如你所见,BERT正在改进NLP的各个方面。这意味着,在开源的同时,我们每天都看到NLP的性能接近人类的水平。
NLP商业化产品正在接近,每一个新的NLP模型不仅在基准上建立了新的记录,而且任何人都可以使用。就像OCR技术在10年前被商品化一样,NLP在未来几年也将如此。
原文链接:https://towardsdatascience.com/summarization-has-gotten-commoditized-thanks-to-bert-9bb73f2d6922
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/07/17/bert%e7%94%9f%e6%88%90%e6%96%87%e6%9c%ac%e6%91%98%e8%a6%81/
