
作者|Orhan Gazi Yalçın
编译|VK
来源|Towards Datas Science
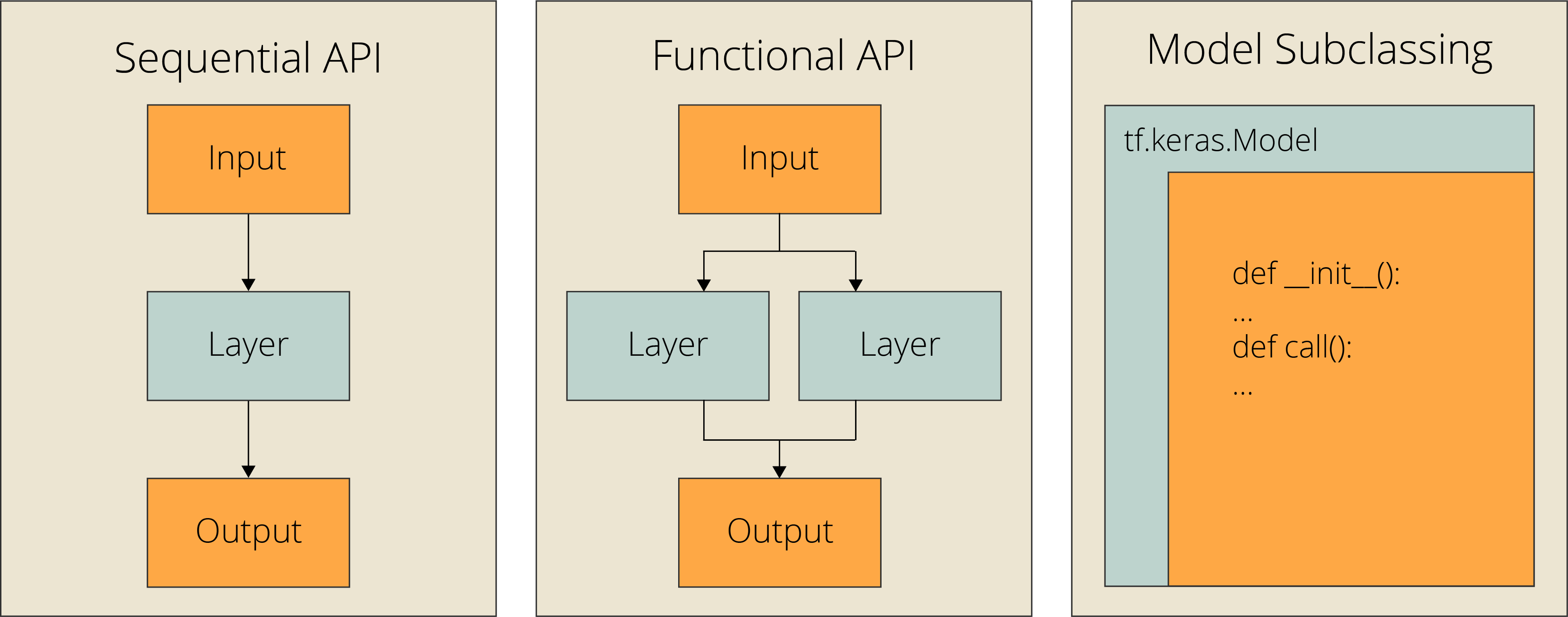
如果你看看不同的教程,搜索,花大量时间研究关于TensorFlow的Stack Overflow,你可能已经意识到有很多不同的方法来构建神经网络模型。
这一直是TensorFlow面临的问题。这就像是TensorFlow试图找到通往光明的深度学习环境的道路。由于TensorFlow是目前市场上最成熟的深度学习库,这基本上是你能得到的最好的。
Keras-TensorFlow的关系
背景
TensorFlow发展成为一个深度学习平台并不是一夜之间发生的。最初,TensorFlow将自己推销为一个符号数学库,用于跨一系列任务的数据流编程。因此,TensorFlow最初提供的主张并不是一个纯粹的机器学习库。目标是创建一个高效的数学库,以便在这种高效结构上构建的自定义机器学习算法能够在短时间内以高精度进行训练。
然而,用低级api重复地从头构建模型并不是很理想。因此,谷歌的工程师弗兰•库伊斯-克里特开发了Keras,作为一个独立的高层次的深度学习库。虽然Keras已经能够运行在不同的库之上,比如TensorFlow, Microsoft Cognitive Toolkit, Theano 或 PlaidML,但是TensorFlow过去和现在仍然是人们使用Keras的最常见的库。
现状
在看到了模型构建过程中的混乱之后,TensorFlow团队宣布Keras将成为在tensorflow2.0中构建和训练模型的核心高级API。另一种高级API,Estimator api
Estimator API和Keras API
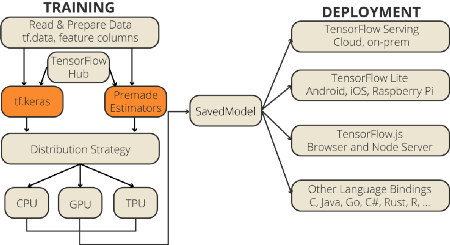
现在,让我们回到问题上来:有很多不同的方法,人们使用TensorFlow来构建他们的模型。这个问题的主要原因是TensorFlow未能采用单一模型API。
在1.x版本中,对于生产级项目,模型构建API是Estimator API。但是,随着最近的变化,keras api几乎赶上了Estimator API。最初,Estimator API具有更高的可伸缩性,允许分布式,并且具有方便的跨平台功能。然而,现在Estimator API的大部分优点都已被消除,因此,很快Keras API将很可能成为构建TensorFlow模型的唯一标准API。
因此,在本文中,我们将只关注在TensorFlow中构建模型的Keras API方法,其中有三种:
-
使用Sequential API
-
使用Functional API
-
模型子类化
我将直接将它们与相应的模型构建代码进行比较,这样你就可以实际测试它们了。让我们深入研究编码。
进行比较的初始代码
为了测试这三种Keras方法,我们需要选择一个深度学习问题。利用MNIST进行图像分类是一个非常简单的任务。我们试图实现的是利用著名的MNIST数据集训练一个识别手写数字的模型。
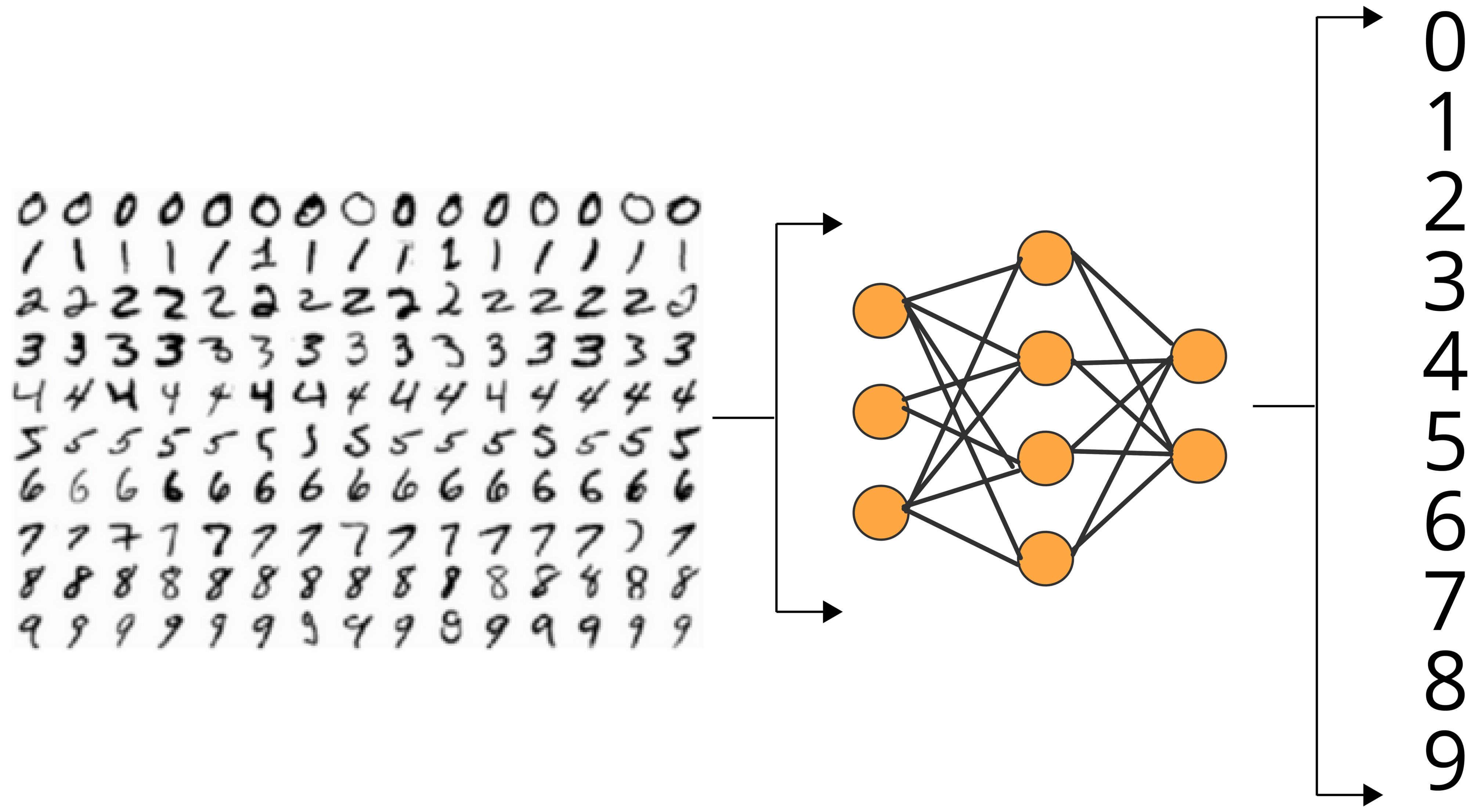
MNIST数据集(MNIST dataset)是一个大型手写数字数据库,通常用于训练各种图像处理系统。MNIST数据库包含6万张训练图片和1万张测试图片,这些图片来自美国人口普查局员工和美国高中生。如果你想遵循完整的教程,你可以找到我的关于图像分类的单独教程:
https://towardsdatascience.com/image-classification-in-10-minutes-with-mnist-dataset-54c35b77a38d
通过下面的代码,我们将导入所有层和模型,这样在接下来的部分中就不会打扰我们了。我们还下载MNIST数据集并对其进行预处理,以便它可以用于我们将使用这三种不同方法构建的所有模型。只需运行以下代码:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras import Input
from tensorflow.keras import Model
from tensorflow.estimator import DNNClassifier
from tensorflow.keras.datasets.mnist import load_data
(x_train, y_train), (x_test, y_test)= load_data( path="mnist.npz" )
# 确保这些值是浮点数,这样除法后就可以得到小数点
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# 通过将RGB代码除以最大RGB值来规范化
x_train /= 255
x_test /= 255现在,这一部分已经结束,让我们集中讨论构建张量流模型的三种方法。
构建Keras模型的3种方法
有三种方法可以在TensorFlow中构建Keras模型:
-
Sequential API:当你试图使用单个输入、输出和层分支构建简单模型时,Sequential API是最好的方法。对于想快速学习的新手来说,这是一个很好的选择。
-
Functional API:函数API是构建Keras模型最流行的方法。它可以完成Sequential API所能做的一切。此外,它允许多个输入、多个输出、分支和层共享。它是一种简洁易用的方法,并且仍然允许很好的定制灵活性。
-
模型子类化:模型子类化是为需要完全控制模型、层和训练过程的高级开发人员设计的。你需要创建一个定义模型的自定义类,而且你可能不需要它来执行日常任务。但是,如果你是一个有实验需求的研究人员,那么模型子类化可能是最好的选择,因为它会给你所有你需要的灵活性。
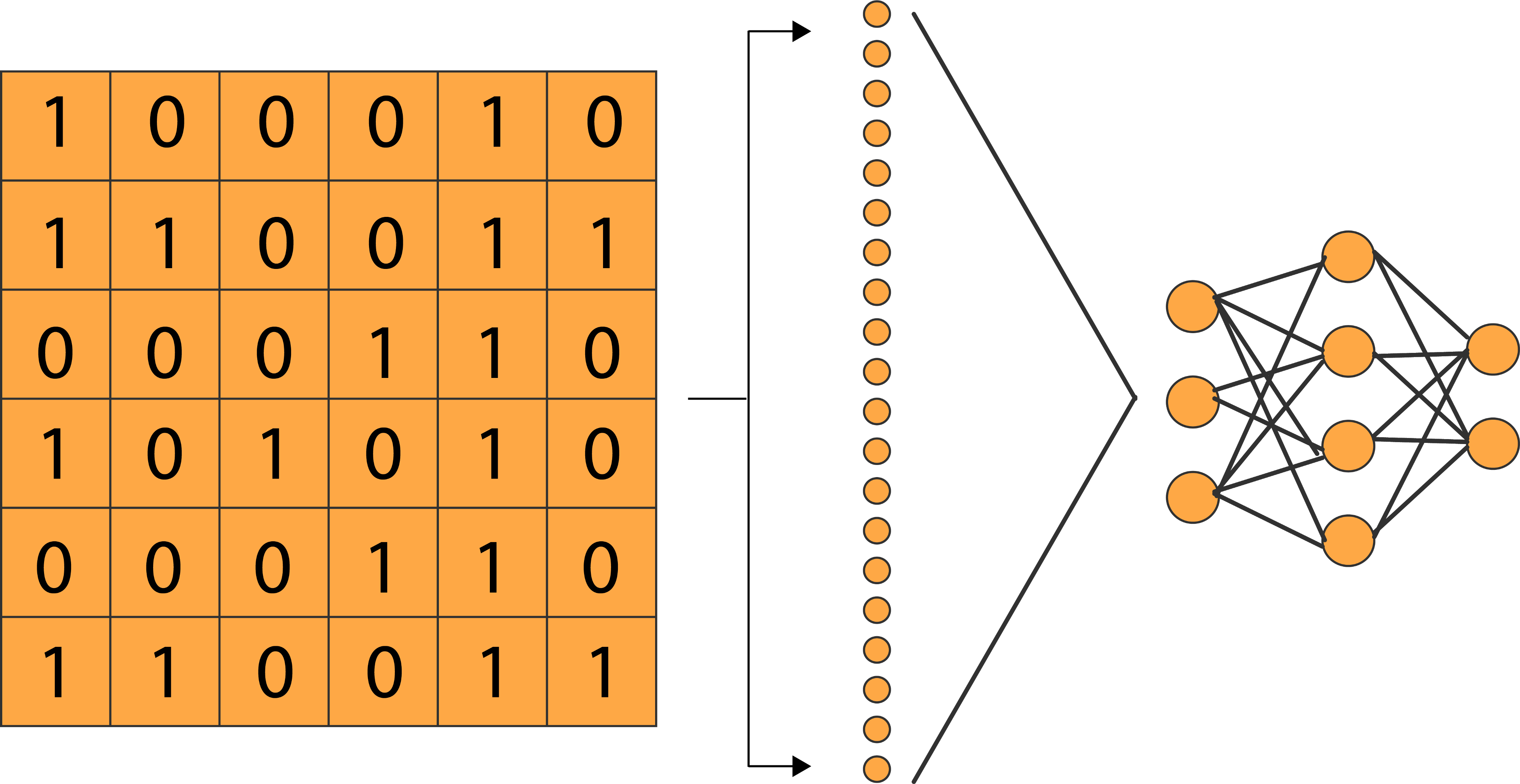
让我们看看这些方法是如何实现的。我们将建立一个具有单一平坦层的基本前馈神经网络,将二维图像阵列转换为一维阵列和两个全连接层。
Sequential API
在Sequential API中,我们需要tf.keras.Models模块。我们可以简单地将下面的所有层作为一个单独的层来传递。如你所见,这很简单。
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(256,'relu'),
Dense(10, "softmax"),
])Functional API
对于Functional API,我们需要单独定义我们的输入。然后,我们需要创建一个输出对象,同时创建所有层,这些层相互关联并与输出相关联。最后,我们创建一个接受输入和输出作为参数的模型对象。代码仍然非常干净,但是我们在Functional API中有了更大的灵活性。
inputs = Input(shape=(28, 28))
x = Flatten()(inputs)
x = Dense(256, "relu")(x)
outputs = Dense(10, "softmax")(x)
model = Model(inputs=inputs, outputs=outputs, name="mnist_model")模型子类化
让我们继续讨论模型子类化。在模型子类化中,我们从创建一个扩展类基于tf.keras.Model 。模型子类化有两个关键功能:
__init__函数充当构造函数。多亏了__init__,我们可以初始化模型的属性(例如,layer)。super调用父构造函数( tf.keras.Model中的构造函数)self用于引用实例属性。- call function是在定义层之后定义操作的地方。
为了使用模型子类化来构建同一个模型,我们需要编写更多的代码,如下所示:
class CustomModel(tf.keras.Model):
def __init__(self, **kwargs):
super(CustomModel, self).__init__(**kwargs)
self.layer_1 = Flatten()
self.layer_2 = Dense(256, "relu")
self.layer_3 = Dense(10, "softmax")
def call(self, inputs):
x = self.layer_1(inputs)
x = self.layer_2(x)
x = self.layer_3(x)
return x
model = CustomModel(name='mnist_model')结尾代码
现在你可以用三种不同的方法创建同一个模型,你可以选择其中任何一个,构建模型,并运行下面的代码。
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x=x_train,y=y_train, epochs=10)
model.evaluate(x_test, y_test)上面的行负责模型配置、训练和评估。当我们比较这三种方法的性能时,我们发现它们非常接近,但略有不同。
| Method | Sequential API | Functional API | Model Subclassing |
|---|---|---|---|
| Loss | 0.08746038377285004 | 0.08131594955921173 | 0.0781003013253212 |
| Accuracy | 97.82% | 98.06% | 98.20% |

我们更复杂的模型子类化方法优于Sequential API和Functional API。这表明,这些方法在低端的设计上也有细微差别。然而,这些差异可以忽略不计。
最终评估
现在,你已经了解了这三种Keras方法之间的异同。但是,让我们用一个表格来总结一下:
| Feature | Sequential API | Functional API | Model Subclassing |
|---|---|---|---|
| Customization | Low | Medium | High |
| Difficulty to Build | Easy | Medium | Difficult |
| Layer Sharing | No | Yes | Yes |
| Multiple Branch | No | Yes | Yes |
| Multiple Input | No | Yes | Yes |
| Multiple Output | No | Yes | Yes |
| Best Suited For | Beginners | Professionals | Resarchers |
总之,如果你刚刚起步,请坚持使用Sequential API。在深入研究更复杂的模型时,请尝试Functional API。如果你正在攻读博士学位,或者只是喜欢进行独立研究,试试模型子类化。如果你是专业人士,请坚持使用Functional API。它可能会满足你的需要。
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/10/19/%e7%94%a8keras%e6%9e%84%e5%bb%ba%e7%a5%9e%e7%bb%8f%e7%bd%91%e7%bb%9c%e7%9a%843%e7%a7%8d%e6%96%b9%e6%b3%95/
