
作者|Soner Yıldırım
编译|VK
来源|Towards Data Science

探索性数据分析(EDA)是数据科学或机器学习管道的重要组成部分。为了使用数据创建一个健壮且有价值的产品,你需要研究数据,理解变量之间的关系,以及数据的底层结构。数据可视化是EDA中最有效的工具之一。
在这篇文章中,我们将尝试使用可视化功能来研究客户流失数据集:https://www.kaggle.com/sonalidasgupta95/churn-prediction-of-bank-customers
我们将创建许多不同的可视化效果,并尝试在每一个可视化中引入Matplotlib或Seaborn库的一个特性。
我们首先导入相关库并将数据集读入pandas数据帧。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style='darkgrid')
%matplotlib inline
df = pd.read_csv("/content/Churn_Modelling.csv")
df.head()
该数据集包含10000个客户(即行)和14个关于银行客户及其产品的特征。这里的目标是使用所提供的特征来预测客户是否会流失(即退出=1)。
让我们从catplot开始,这是Seaborn库的一个分类图。
sns.catplot(x='Gender', y='Age', data=df, hue='Exited', height=8, aspect=1.2)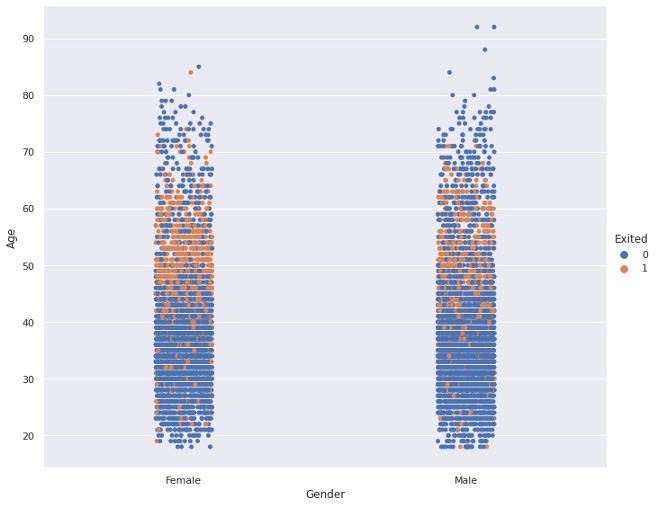
研究发现:45到60岁的人比其他年龄段的人更容易离职(即离开公司)。女性和男性之间没有太大的差别。
hue参数用于根据类别变量区分数据点。
下一个可视化是散点图,它显示了两个数值变量之间的关系。让我们看看客户的工资和余额是否相关。
plt.figure(figsize=(12,8))
plt.title("Estimated Salary vs Balance", fontsize=16)
sns.scatterplot(x='Balance', y='EstimatedSalary', data=df)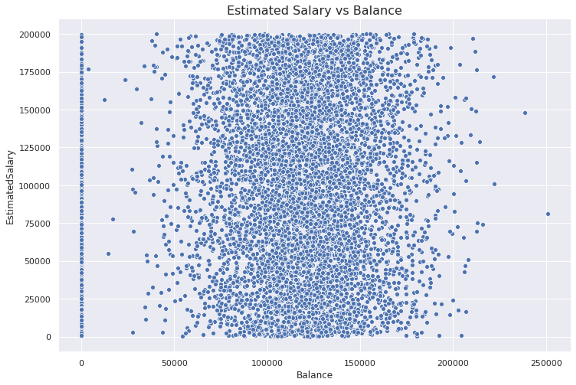
我们第一次使用matplotlib.pyplot接口来创建Figure对象并设置标题。然后,我们用Seaborn在这个图形对象上画出了实际的图表。
研究结果:估计工资与余额之间不存在有意义的关系或相关性。余额似乎具有正态分布(不包括余额为零的客户)。
下一个可视化是箱线图,它显示了一个变量在中位数和四分位数上的分布。
plt.figure(figsize=(12,8))
ax = sns.boxplot(x='Geography', y='Age', data=df)
ax.set_xlabel("Country", fontsize=16)
ax.set_ylabel("Age", fontsize=16)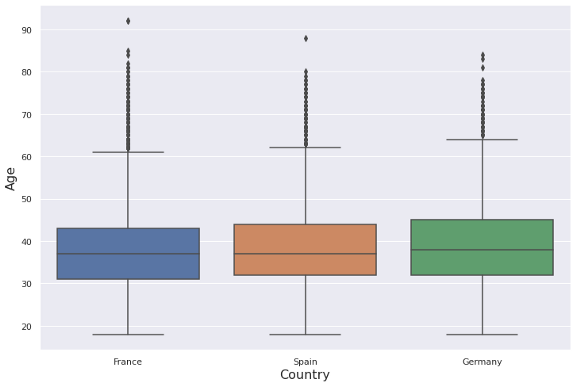
我们还使用set_xlabel和set_ylabel调整了x和y轴的字体大小。
以下是箱线图:
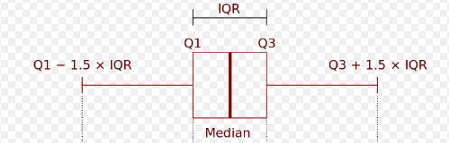
中值是所有点排序时中间的点。Q1(第一个或下四分位数)是数据集下半部分的中值。Q3(第三或上四分位数)是数据集上半部分的中值。
因此,箱线图为我们提供了关于分布和异常值的概念。在我们创建的箱线图中,顶部有许多异常值(用点表示)。
发现:年龄变量的分布是右偏的。由于上侧的异常值,平均值大于中值。
在变量的单变量分布中可以观察到右偏态。让我们创建一个distplot来观察分布。
plt.figure(figsize=(12,8))
plt.title("Distribution of Age", fontsize=16)
sns.distplot(df['Age'], hist=False)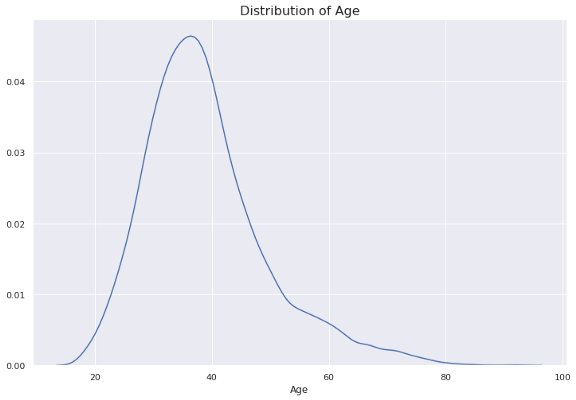
右边的尾巴比左边的重。原因是我们在箱线图上观察到的异常值。
distplot在默认情况下也提供了一个直方图,但是我们使用hist参数更改了它。
Seaborn库还提供了不同类型的pair图,这些图提供了变量之间成对关系的概述。让我们先从数据集中随机抽取一个样本,使曲线图更具吸引力。原始数据集有10000个观测值,我们将选取一个包含100个观测值和4个特征的样本。
subset=df[['CreditScore','Age','Balance','EstimatedSalary']].sample(n=100)
g = sns.pairplot(subset, height=2.5)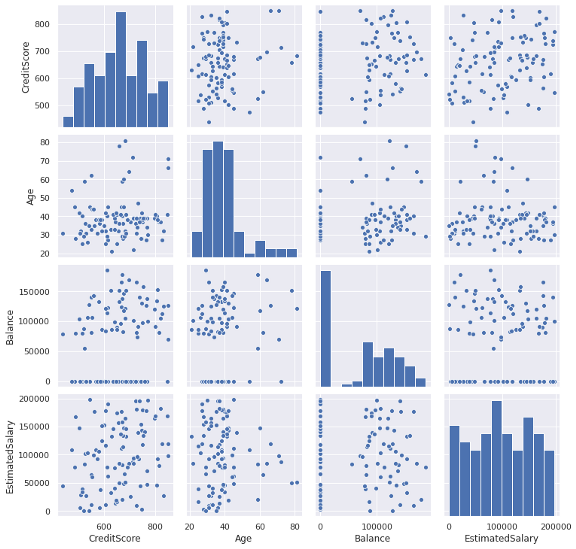
在对角线上,我们可以看到变量的直方图。网格的另一部分表示变量与变量之间的关系。
另一个观察成对关系的工具是热图,它采用矩阵并生成彩色编码图。热图主要用于检查特征和目标变量之间的相关性。
让我们首先使用pandas的corr函数创建一些特征的相关矩阵。
corr_matrix = df[['CreditScore','Age','Tenure','Balance',
'EstimatedSalary','Exited']].corr()我们现在可以绘制这个矩阵。
plt.figure(figsize=(12,8))
sns.heatmap(corr_matrix, cmap='Blues_r', annot=True)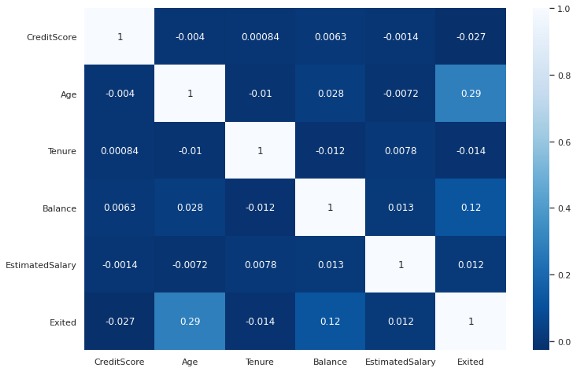
发现:“年龄”和“余额”列与客户流失呈正相关。
随着数据量的增加,分析和探索数据变得越来越困难。可视化是探索性数据分析中的一个重要工具,当它被有效和恰当地使用时,它就有了强大的力量。可视化也有助于向你的听众传达信息或告诉他们你的发现。
没有一种适合所有类型的可视化方法,因此某些任务需要不同类型的可视化。根据任务的不同,不同的选择可能更合适。所有可视化都有一个共同点,那就是它们是探索性数据分析和数据科学中讲故事部分的好工具。
原文链接:https://towardsdatascience.com/a-practical-guide-for-data-visualization-9f1a87c0a4c2
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/10/19/%e6%95%b0%e6%8d%ae%e5%8f%af%e8%a7%86%e5%8c%96%e5%ae%9e%e7%94%a8%e6%95%99%e7%a8%8b/
