
作者|Doug Steen
编译|VK
来源|Towards Data Science

当涉及到机器学习分类任务时,用于训练算法的数据越多越好。在监督学习中,这些数据必须根据目标类进行标记,否则,这些算法将无法学习独立变量和目标变量之间的关系。但是,在构建用于分类的大型标记数据集时,会出现两个问题:
- 标记数据可能很耗时。假设我们有1000000张狗图像,我们想将它们输入到分类算法中,目的是预测每个图像是否包含波士顿狗。如果我们想将所有这些图像用于监督分类任务,我们需要一个人查看每个图像并确定是否存在波士顿狗。
- 标记数据可能很昂贵。原因一:要想让人费尽心思去搜100万张狗狗照片,我们可能得掏钱。
那么,这些未标记的数据可以用在分类算法中吗?
这就是半监督学习的用武之地。在半监督方法中,我们可以在少量的标记数据上训练分类器,然后使用该分类器对未标记的数据进行预测。
由于这些预测可能比随机猜测更好,未标记的数据预测可以作为“伪标签”在随后的分类器迭代中采用。虽然半监督学习有很多种风格,但这种特殊的技术称为自训练。
自训练
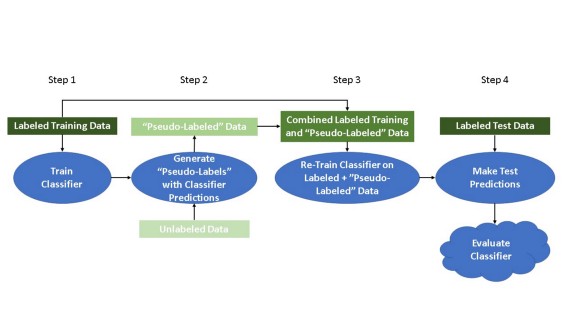
在概念层面上,自训练的工作原理如下:
步骤1:将标记的数据实例拆分为训练集和测试集。然后,对标记的训练数据训练一个分类算法。
步骤2:使用经过训练的分类器来预测所有未标记数据实例的类标签。在这些预测的类标签中,正确率最高的被认为是“伪标签”。
(第2步的几个变化:a)所有预测的标签可以同时作为“伪标签”使用,而不考虑概率;或者b)“伪标签”数据可以通过预测的置信度进行加权。)
步骤3:将“伪标记”数据与正确标记的训练数据连接起来。在组合的“伪标记”和正确标记训练数据上重新训练分类器。
步骤4:使用经过训练的分类器来预测已标记的测试数据实例的类标签。使用你选择的度量来评估分类器性能。
(可以重复步骤1到4,直到步骤2中的预测类标签不再满足特定的概率阈值,或者直到没有更多未标记的数据保留。)
好的,明白了吗?很好!让我们通过一个例子解释。
示例:使用自训练改进分类器
为了演示自训练,我使用Python和surgical_deepnet 数据集,可以在Kaggle上找到:https://www.kaggle.com/omnamahshivai/surgical-dataset-binary-classification
此数据集用于二分类,包含14.6k+手术的数据。这些属性是bmi、年龄等各种测量值,而目标变量complexing则记录患者是否因手术而出现并发症。显然,能够准确地预测患者是否会因手术而出现并发症,这对医疗保健和保险供应商都是最有利的。
导入库
对于本教程,我将导入numpy、pandas和matplotlib。我还将使用sklearn中的LogisticRegression分类器,以及用于模型评估的f1_score和plot_confusion_matrix 函数
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import f1_score
from sklearn.metrics import plot_confusion_matrix加载数据
# 加载数据
df = pd.read_csv('surgical_deepnet.csv')
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 14635 entries, 0 to 14634
Data columns (total 25 columns):
bmi 14635 non-null float64
Age 14635 non-null float64
asa_status 14635 non-null int64
baseline_cancer 14635 non-null int64
baseline_charlson 14635 non-null int64
baseline_cvd 14635 non-null int64
baseline_dementia 14635 non-null int64
baseline_diabetes 14635 non-null int64
baseline_digestive 14635 non-null int64
baseline_osteoart 14635 non-null int64
baseline_psych 14635 non-null int64
baseline_pulmonary 14635 non-null int64
ahrq_ccs 14635 non-null int64
ccsComplicationRate 14635 non-null float64
ccsMort30Rate 14635 non-null float64
complication_rsi 14635 non-null float64
dow 14635 non-null int64
gender 14635 non-null int64
hour 14635 non-null float64
month 14635 non-null int64
moonphase 14635 non-null int64
mort30 14635 non-null int64
mortality_rsi 14635 non-null float64
race 14635 non-null int64
complication 14635 non-null int64
dtypes: float64(7), int64(18)
memory usage: 2.8 MB数据集中的属性都是数值型的,没有缺失值。由于我这里的重点不是数据清理,所以我将继续对数据进行划分。
数据划分
为了测试自训练的效果,我需要将数据分成三部分:训练集、测试集和未标记集。我将按以下比例拆分数据:
- 1% 训练
- 25% 测试
- 74% 未标记
对于未标记集,我将简单地放弃目标变量complexing,并假装它从未存在过。
所以,在这个病例中,我们认为74%的手术病例没有关于并发症的信息。我这样做是为了模拟这样一个事实:在实际的分类问题中,可用的大部分数据可能没有类标签。然而,如果我们有一小部分数据的类标签(在本例中为1%),那么可以使用半监督学习技术从未标记的数据中得出结论。
下面,我随机化数据,生成索引来划分数据,然后创建测试、训练和未标记的划分。然后我检查各个集的大小,确保一切都按计划进行。
X_train dimensions: (146, 24)
y_train dimensions: (146,)
X_test dimensions: (3659, 24)
y_test dimensions: (3659,)
X_unlabeled dimensions: (10830, 24)类分布
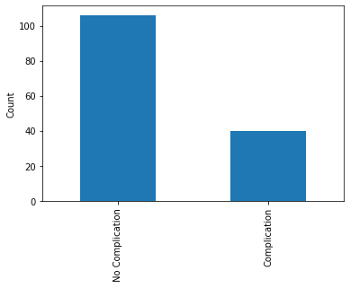
多数类的样本数((并发症))是少数类(并发症)的两倍多。在这样一个不平衡的类的情况下,我想准确度可能不是最佳的评估指标。
选择F1分数作为分类指标来判断分类器的有效性。F1分数对类别不平衡的影响比准确度更为稳健,当类别近似平衡时,这一点更为合适。F1得分计算如下:
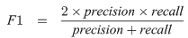
其中precision是预测正例中正确预测的比例,recall是真实正例中正确预测的比例。
初始分类器(监督)
为了使半监督学习的结果更真实,我首先使用标记的训练数据训练一个简单的Logistic回归分类器,并对测试数据集进行预测。
Train f1 Score: 0.5846153846153846
Test f1 Score: 0.5002908667830134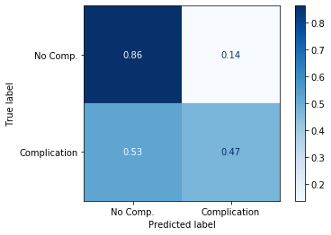
分类器的F1分数为0.5。混淆矩阵告诉我们,分类器可以很好地预测没有并发症的手术,准确率为86%。然而,分类器更难正确识别有并发症的手术,准确率只有47%。
预测概率
对于自训练算法,我们需要知道Logistic回归分类器预测的概率。幸运的是,sklearn提供了.predict_proba()方法,它允许我们查看属于任一类的预测的概率。如下所示,在二元分类问题中,每个预测的总概率总和为1.0。
array([[0.93931367, 0.06068633],
[0.2327203 , 0.7672797 ],
[0.93931367, 0.06068633],
...,
[0.61940353, 0.38059647],
[0.41240068, 0.58759932],
[0.24306008, 0.75693992]])自训练分类器(半监督)
既然我们知道了如何使用sklearn获得预测概率,我们可以继续编码自训练分类器。以下是简要概述:
第1步:首先,在标记的训练数据上训练Logistic回归分类器。
第2步:接下来,使用分类器预测所有未标记数据的标签,以及这些预测的概率。在这种情况下,我只对概率大于99%的预测采用“伪标签”。
第3步:将“伪标记”数据与标记的训练数据连接起来,并在连接的数据上重新训练分类器。
第4步:使用训练好的分类器对标记的测试数据进行预测,并对分类器进行评估。
重复步骤1到4,直到没有更多的预测具有大于99%的概率,或者没有未标记的数据保留。
下面的代码使用while循环在Python中实现这些步骤。
Iteration 0
Train f1: 0.5846153846153846
Test f1: 0.5002908667830134
Now predicting labels for unlabeled data...
42 high-probability predictions added to training data.
10788 unlabeled instances remaining.
Iteration 1
Train f1: 0.7627118644067796
Test f1: 0.5037463976945246
Now predicting labels for unlabeled data...
30 high-probability predictions added to training data.
10758 unlabeled instances remaining.
Iteration 2
Train f1: 0.8181818181818182
Test f1: 0.505431675242996
Now predicting labels for unlabeled data...
20 high-probability predictions added to training data.
10738 unlabeled instances remaining.
Iteration 3
Train f1: 0.847457627118644
Test f1: 0.5076835515082526
Now predicting labels for unlabeled data...
21 high-probability predictions added to training data.
10717 unlabeled instances remaining.
...
Iteration 44
Train f1: 0.9481216457960644
Test f1: 0.5259179265658748
Now predicting labels for unlabeled data...
0 high-probability predictions added to training data.
10079 unlabeled instances remaining.自训练算法经过44次迭代,就不能以99%的概率预测更多的未标记实例了。即使一开始有10,830个未标记的实例,在自训练之后仍然有10,079个实例未标记(并且未被分类器使用)。
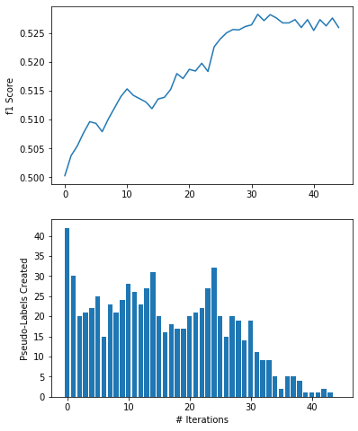
经过44次迭代,F1的分数从0.50提高到0.525!虽然这只是一个小的增长,但看起来自训练已经改善了分类器在测试数据集上的性能。上图的顶部面板显示,这种改进大部分发生在算法的早期迭代中。同样,底部面板显示,添加到训练数据中的大多数“伪标签”都是在前20-30次迭代中出现的。
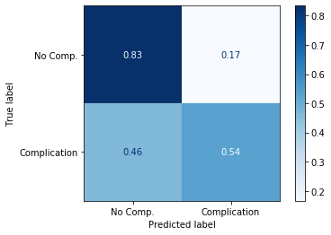
最后的混淆矩阵显示有并发症的手术分类有所改善,但没有并发症的手术分类略有下降。有了F1分数的提高,我认为这是一个可以接受的进步-可能更重要的是确定会导致并发症的手术病例(真正例),并且可能值得增加假正例率来达到这个结果。
警告语
所以你可能会想:用这么多未标记的数据进行自训练有风险吗?答案当然是肯定的。请记住,尽管我们将“伪标记”数据与标记的训练数据一起包含在内,但某些“伪标记”数据肯定会不正确。当足够多的“伪标签”不正确时,自训练算法会强化糟糕的分类决策,而分类器的性能实际上会变得更糟。
可以使用分类器在训练期间没有看到的测试集,或者使用“伪标签”预测的概率阈值,可以减轻这种风险。
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/10/19/%e8%87%aa%e8%ae%ad%e7%bb%83%e5%92%8c%e5%8d%8a%e7%9b%91%e7%9d%a3%e5%ad%a6%e4%b9%a0%e4%bb%8b%e7%bb%8d/

评论列表(1条)
老师你好,我是一名学生 刚开始接触半监督学习,请问能问您要源代码学习一下吗?感谢!!