
作者|Yogeeshwari S
编译|VK
来源|Towards Data Science
我很高兴与大家分享我的机器学习和深度学习经验,同时我们将在一个Kaggle竞赛得到解决方案。学习过程的分析也是非常直观,具有娱乐性和挑战性。希望这个博客最终能给读者一些有用的学习帮助。
目录
-
业务问题
-
误差度量
-
机器学习和深度学习在我们的问题中的应用
-
数据来源
-
探索性数据分析-EDA
-
现有方法
-
资料准备
-
模型说明
-
结果
-
我对改善RMSLE的尝试
-
未来的工作
-
GitHub存储库
-
参考引用

1.业务问题
Mercari是一家在日本和美国运营的电子商务公司,其主要产品是Mercari marketplace的应用程序。人们可以使用智能手机轻松地出售或购买物品。
应用程序的用户可以自由选择价格,同时列出商品。然而,这里的风险更高,因为如果价格表与市场价格相比过高或过低,消费者和客户都会处于亏损状态。上述问题的解决方案是自动推荐商品价格,因此,最大的社区购物应用程序希望向卖家提供价格建议。
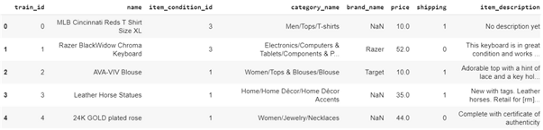
目前的问题是预测任何给定产品的价格,这说明这是一个回归问题。训练数据中的特征包括物品的train_id, name, item_condition_id, category_name, brand_name, price, shipping, item_description。
除了目标变量价格之外,我们在测试数据中拥有所有其他特征。这些特征不仅是离散的和连续的,而且包含卖家提供的商品的文字描述。例如,女性配饰产品的文字说明如下:

我们可以看到,这两种产品的售价不同,第一种售价16美元,第二种售价9美元。
因此,这里的挑战是,我们需要建立一个模型,根据上图所示的描述,以及产品名称、品牌名称、商品状况等,来预测产品的正确价格。
2.误差度量
这个问题的误差度量是均方根对数误差(RMSLE)。请参阅此博客以了解有关度量的更多信息
https://medium.com/analytics-vidhya/root-mean-square-log-error-rmse-vs-rmlse-935c6cc1802a
度量计算公式如下图所示:

RMSLE计算代码如下:
def rmsle_compute(y_true, y_pred):
#https://www.kaggle.com/gspmoreira/cnn-glove-single-model-private-lb-0-41117-35th
assert len(y_true) == len(y_pred)
score = np.sqrt(np.mean(np.power(np.log1p(y_pred) - np.log1p(y_true), 2)))
return score3.机器学习和深度学习在我们的问题中的应用
在这个人工智能(AI)时代,当我们想到AI的时候,有两个流行词分别是机器学习和深度学习。我们发现人工智能无处不在,它们现在是人类生活的一部分。无论是通勤(例如出租车预订)、医疗诊断、个人助理(如Siri、Alexa)、欺诈检测、犯罪侦查、在线客户支持、产品推荐、自动驾驶汽车,等等。利用先进的机器学习和深度学习算法,任何类型的预测问题都可以解决。
我们的问题是独特的,因为它是一个基于自然语言处理(NLP)的回归任务。NLP的第一步是将文本表示为数字,即将文本转换为数字向量表示,以构造回归函数。
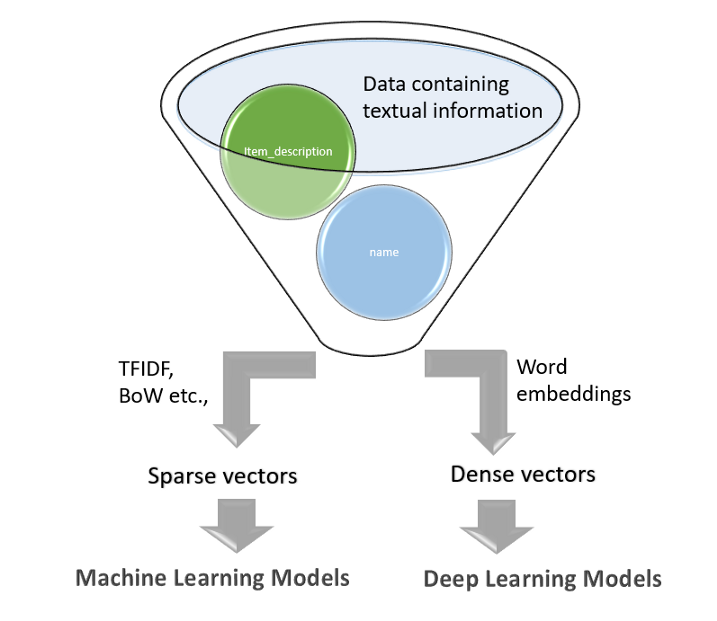
解决价格预测问题的一种方法是利用向量化技术,如TF-IDF、BoW,并构建固定大小的稀疏向量表示,这些表示将被经典的机器学习算法(例如简单线性回归器、基于树的回归器等)使用。
另一种方法是使用深层NLP体系结构(例如CNN、LSTM、GRU或它们的组合),这些体系结构可以独立学习特征,可以得到密集向量。在当前的分析中,我们正在研究这两种方法。
4.数据来源
这个分析的数据集来自Kaggle,一个流行的在线社区或者数据科学家的数据平台。

了解数据
训练集由140多万件产品组成,第二阶段测试集由340多万件产品组成。
列出训练/测试数据中的字段名:
- train_id 或者test_id — 列表的唯一id
- name — 卖方提供的产品名称。请注意,为避免数据泄漏,此字段中的价格被删除并表示为[rm]
- item_condition_id — 这里卖家提供物品条件
- category_name — 每个物品的类别列表
- brand_name — 每个商品所属的相应品牌
- price — 这是我们的目标变量,以美元表示(不在测试集中)
- shipping — 1,如果运费由卖方支付,否则为0
- item_description — 此处给出了每个物品的描述,价格被删除并表示为[rm]
以下数据的部分截图:
5.探索性数据分析-EDA
EDA是数据科学过程中的一个重要步骤,是一种统计方法,通常使用可视化方法从数据集中获得更多的见解。在深入研究EDA之前,让我们快速查看数据以了解更多信息。下面是检查空值的代码段:
print(train.isnull().sum())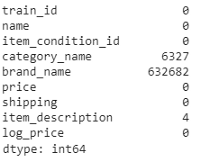
从上面的输出中,我们发现三列,即类别名称(category name)、品牌名称(brand name)和物品描述(item description)携带空值。其中,品牌名称包含了很多缺失的值(~632k)。列类别名称包含~6.3k个空值,而物品描述只有4个空值。让我们稍后在创建模型时再处理它们,现在我们逐个深入研究EDA特性。
5.1 类别名称的单变量分析
训练数据集中共有1287个类别。下面是用于计数的代码段:
category_count = train['category_name'].value_counts()
类别计数图如下所示:
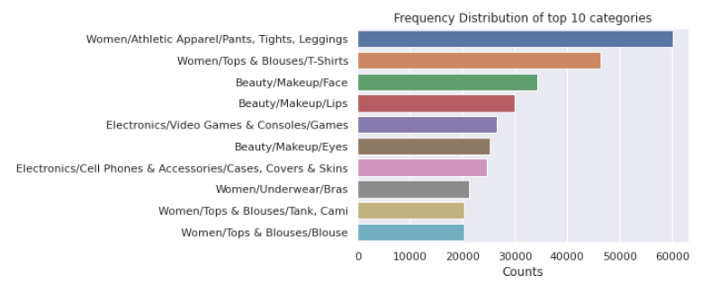
上面的条形图显示了出现频率最高的10个类别。人们会注意到,女装在所有群体中占据着制高点。
每个类别名称由3个子部分组成,用“/”分隔,并有主类别/子类别1/子类别2名称。重要的是要将它们分开,并将它们作为新的特征包含进来,这样我们的模型就能做出更好的预测。
划分类别
在我们的分析中,我们使用以下函数将每个类别的名称划分为主类别、子类别1、子类别2。
def split_categories(category):
'''
函数在数据集中划分类别列并创建3个新列:
'main_category','sub_cat_1','sub_cat_2'
'''
try:
sub_cat_1,sub_cat_2,sub_cat_3 = category.split("/")
return sub_cat_1,sub_cat_2,sub_cat_3
except:
return ("No label","No label","No label")
def create_split_categories(data):
'''
使用split_categories函数创建3个新列的函数
: 'main_category','sub_cat_1','sub_cat_2'
'''
#https://medium.com/analytics-vidhya/mercari-price-suggestion-challenge-a-machine-learning-regression-case-study-9d776d5293a0
data['main_category'],data['sub_cat_1'],data['sub_cat_2']=zip(*data['category_name'].\
apply(lambda x: split_categories(x)))此外,使用下面的代码行计算三列中每个列中的类别数:
main_category_count_te = test['main_category'].value_counts()
sub_1_count_te = test['sub_cat_1'].value_counts()
sub_2_count_te = test['sub_cat_2'].value_counts()上述分析表明,训练数据中有11个主要类别,这些类别又分为114个子类别(子类别1),这些子类别又被进一步分配到865个特定类别(子类别2)。绘制类别的代码如下所示:
def plot_categories(category,title):
'''
这个函数接受一个类别和标题作为输入,并绘制条形图。
'''
#https://seaborn.pydata.org/generated/seaborn.barplot.html
sns.set(style="darkgrid")
sns.barplot(x=category[:10].values, y=category[:10].index)
plt.title(title)
plt.xlabel('Counts', fontsize=12)
plt.show()#https://www.datacamp.com/community/tutorials/categorical-data
plot_categories(category_count,"Frequency Distribution of top 10 categories")拆分后该类别每列前10项的条形图如下:
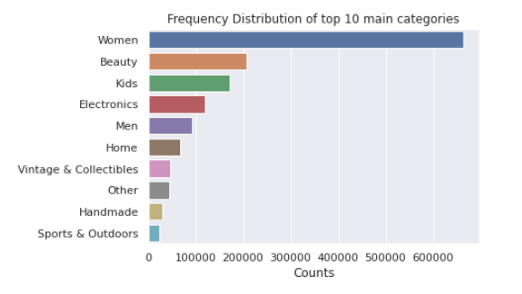
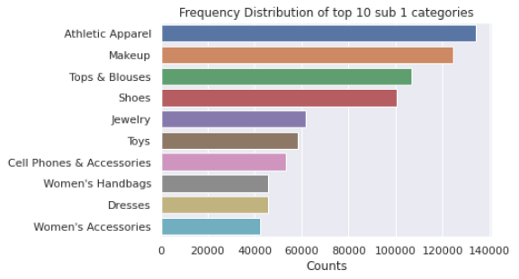
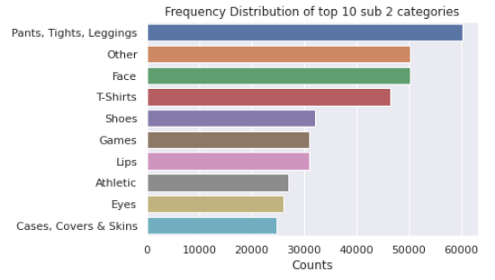
5.2品牌名称的单变量分析
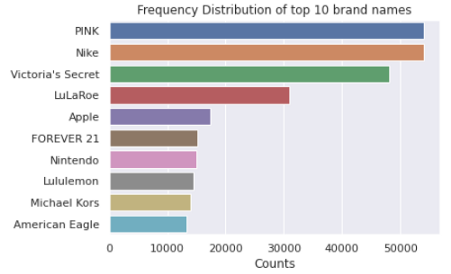
共有4807个品牌,其中最常出现的前10个品牌如下图所示:
绘图代码在这里:
#https://www.datacamp.com/community/tutorials/categorical-data
sns.barplot(x=brand_count[:10].values, y=brand_count[:10].index)
plt.title('Frequency Distribution of top 10 brand names')
plt.xlabel('Counts', fontsize=12)
plt.show()值得注意的是PINK 和NIKE 品牌,紧随其后的是维多利亚的秘密。
5.3价格单变量分析
由于价格是数值的,所以我们使用describe()函数来查看摘要。下面是代码片段:
train.price.describe()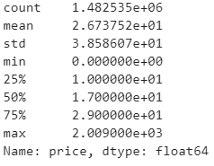
任何产品的最高价格为2009美元,最低价格为0。还应注意的是,75%的产品价格低于29美元,50%的产品价格低于17美元,而25%的产品价格低于10美元。平均价格区间为26.7美元。
价格变量分布
目标的分布
plt.title("Distribution of Price variable")
plt.xlabel("Price(USD)")
plt.ylabel("No. of products")
plt.hist(train['price'],bins=30)
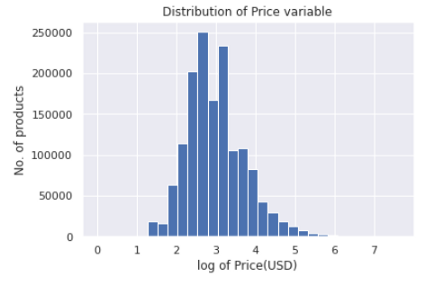
价格特征遵循右偏分布,如上图所示。正如这里所讨论的,由于分布的另一侧的点,倾斜分布会导致较高的均方误差(MSE)值,如果数据是正态分布,则MSE就不会那么大。
因此,对price特征进行log转换是不可避免的,如果数据是正态分布的,那么模型的性能也会更好(参见这里)。这是通过以下代码片段完成的:
def log_price(price):
return np.log1p(price)下图为对数转换后的价格变量图。
5.4物品描述的单变量分析
我们正在绘制词云以了解描述中常见的单词。对应的代码段,图如下:
word_counter = Counter(train['item_description'])
most_common_words = word_counter.most_common(500)
#https://www.geeksforgeeks.org/generating-word-cloud-python/
# 创建并生成一个词云图像:
stopwords = get_stop_words('en')
#https://github.com/Alir3z4/python-stop-words/issues/19
stopwords.extend(['rm'])
wordcloud = WordCloud(stopwords=stopwords,background_color="white").generate(str(most_common_words))
# 显示生成的图像:
plt.figure(figsize=(10,15))
plt.imshow(wordcloud, interpolation='bilinear')
plt.title("Word cloud generated from the item_descriptions\n")
plt.axis("off")
plt.show()
从上面的单词cloud中,我们可以注意到在我们的item_description中经常出现的单词。
描述的字数
单独的文本描述可能是这个问题(参考)的一个重要特征,即对于机器学习模型,并且将有助于嵌入深度学习模型的过程。
train['description_wc'] = [len(str(i).split()) for i in train['item_description']]为了进一步研究该特征,我们绘制了如下所示的箱线图和分布图,下面是代码:
箱线图
sns.boxplot(train['description_wc'],orient='v')
plt.title("Box plot of description word count")
plt.xlabel("item_description")
plt.ylabel("No. of words")
plt.show()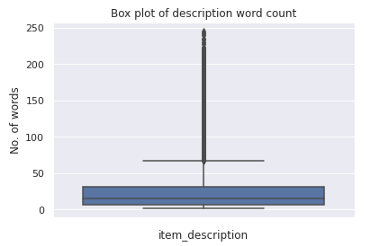
我们可以注意到,大多数描述包含大约少于40个单词。
分布图
plt.figure(figsize=(10,3))
sns.distplot(train['description_wc'], hist=False)
plt.title('Plot of the word count for each item description')
plt.xlabel('Number of words in each description')
plt.show()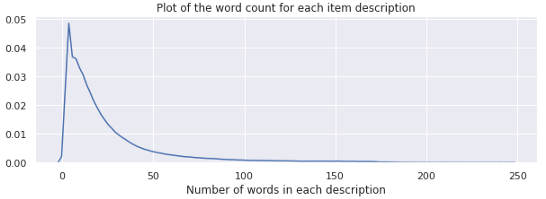
描述字数的密度图是右偏的。
统计数据摘要
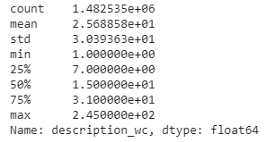
Summary stats表明item_description的最小长度为1,而最大长度为245。平均长度约为25个单词。少数描述比较长,而大多数描述包含不到40个单词,正如我们在箱线图中看到的那样。
5.5物品条件的单变量分析
离散特征item_condition_id 的范围是1到5。该特征具有顺序性,1的物品是“最好的”,条件5的物品是“最差的”。item_condition_id的条形图如下所示:
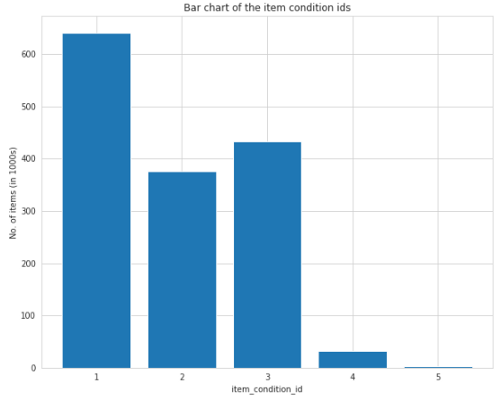
大多数待售商品状况良好,如上图所示。因此,条件1的物品较高,其次是条件3和2,而条件4和5的物品较低。
5.6双变量分析
了解目标变量与其他特征的关联类型将有助于特征工程。因此,将价格变量与其他两个变量进行比较。
价格与运费
和往常一样,图表有助于我们更好地理解事物。代码和绘图如下所示:
#https://seaborn.pydata.org/generated/seaborn.boxplot.html
ax = sns.boxplot(x=train['shipping'],y=train['log_price'],palette="Set3",hue=train['shipping'])
handles, _ = ax.get_legend_handles_labels()
ax.legend(handles, ["seller pays", "Buyer pays"])
plt.title('Price distribution', fontsize=15)
plt.show()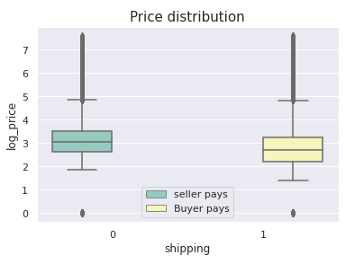
我们可以观察到,当商品价格较高时,卖方支付运费,反之亦然。
价格与描述长度
我们上面所做的两个变量的绘图。
plt.scatter(train['description_wc'],train['price'],alpha=0.4)
plt.title("Price Vs Description length")
plt.xlabel("Description length")
plt.ylabel("Price(USD)")
plt.show()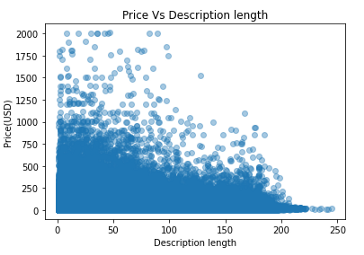
值得注意的是,描述长度较短的商品价格往往高于描述长度较长的商品。
6.现有方法
有一些博客和论文已经使用简单的机器学习或深度学习方法提出了解决方案。我们将简要介绍其中一些:
MLP
Pawel和Konstantin以他们惊人的解决方案赢得了这场比赛。他们使用了一种基于前馈神经网络的方法,即一种简单的MLP,它可以有效地处理稀疏特征。
他们所执行的一些预处理技巧包括对分类列进行一次one-hot编码、使用PorterStemmer进行词干分析、BoW-1,2-grams(带和不带TF-IDF)、将不同字段(如名称、品牌名称和物品描述)串联到单个字段中。他们的最终得分是0.37:https://www.kaggle.com/lopuhin/mercari-golf-0-3875-cv-in-75-loc-1900-s
CNN
在本研究中,作者使用了CNN架构,结合max-pooling,分别对名称和物品描述进行向量化。他使用预训练好的GloVE向量进行词嵌入,嵌入是在名称和物品描述中得到的。一些有用的技巧是在最后一个全连接层之前使用跳跃连接并且进行一些离散特征的连接,以及使用了词嵌入的平均池层。作者通过一个单一的深度学习模型取得了0.41的惊人成绩:https://www.kaggle.com/gspmoreira/cnn-glove-single-model-private-lb-0-41117-35th
LGBM + Ridge
在这里,作者应用了一个基于树的梯度提升框架LightGBM,以实现更快的训练和更高的效率。该研究还使用了一种简单、快速的岭回归模型进行训练。一些特色技术包括:使用CountVectorizer对name和category_name列进行向量化,TfidfVectorizer用于item_description,dummy 变量创建用于item_condition_id和shipping_id,以及LabelBinarizer用于品牌名。两个模型合二为一后,作者得到了0.44分:https://www.kaggle.com/tunguz/more-effective-ridge-lgbm-script-lb-0-44823
GRU+2 Ridge
在这项研究中,作者使用RNN、Ridge和RidgeCV构建了一个关联模型,其RMSLE约为0.427。这里应用的一些有用的技巧包括使用GRU层实现文本特征,为RNN训练采用早停策略,在两个epoch使用小批量大小,以及用于岭回归模型的超过300k个特征:https://www.kaggle.com/valkling/mercari-rnn-2ridge-models-with-notes-0-42755#RNN-Model
7.数据准备
清理数据
根据这一参考资料,Mercari网站上的最低价格为3美元。因此,在我们的训练数据中,我们保留价格高于3美元的物品。下面显示的是相同的代码段:
#https://www.kaggle.com/valkling/mercari-rnn-2ridge-models-with-notes-0-42755
train = train.drop(train[(train.price < 3.0)].index)处理空值/缺失值
从EDA中,我们知道3列,即category_name, brand_name, 和item_description包含空值。因此,我们用适当的值来代替它们。我们使用以下函数执行此操作:
def fill_nan(dataset):
'''
函数填充各列中的NaN值
'''
dataset["item_description"].fillna("No description yet",inplace=True)
dataset["brand_name"].fillna("missing",inplace=True)
dataset["category_name"].fillna("missing",inplace=True)训练测试集拆分
在我们的分析中,价格是目标变量y。基于误差函数来评估回归模型的拟合度是很重要的,我们需要对y进行观察和预测。训练数据分为训练集和测试集。
对于基本线性回归模型,测试集包含10%的数据,对于深度学习模型,测试集包含总数据的20%。
缩放目标变量
目标变量的标准化是使用sklearn的StandardScaler函数。预处理如下图所示:
global y_scalar
y_scalar = StandardScaler()
y_train = y_scalar.fit_transform(log_price(X_train['price']).values.reshape(-1, 1))
y_test = y_scalar.transform(log_price(X_test['price']).values.reshape(-1, 1))由于我们的目标变量是使用上述函数进行标准化的,所以在计算误差度量之前,将预测进行逆变换是很重要的。这是通过使用以下函数来完成的:
def scale_back(x):
'''
函数对缩放值进行逆变换
'''
x= np.expm1(y_scalar.inverse_transform(x.reshape(-1,1))[:,0])
return x8.模型说明
让我们详细介绍机器学习和深度学习管道。
8.1机器学习管道

在这一分析中,自然语言处理的概念,如BoW,TFIDF等被用来向量化文本的机器学习回归模型。
构建特征
在执行EDA时,我们添加了四个新特征,即通过拆分列category生成三个新列,并从item_description中添加文本描述的字数。另外,我们根据名称文本的长度再创建一个列。所以,我们有五个新特征。
我们的数据集包括离散特征、数字特征和文本特征。必须对离散特征进行编码,并将文本特征向量化,以创建模型使用的特征矩阵。
离散特征编码
我们使用sci工具包中的CountVectorizer函数对离散特征(如category_name, main_category,sub_cat_1,sub_cat_2,brand_name)进行one-hot编码,并使用get_dummies()函数对shipping_id 和item_condition_id 进行编码。其代码如下:
def one_hot_encode(train,test):
'''
函数对离散列进行one-hot编码
'''
vectorizer = CountVectorizer(token_pattern='.+')
vectorizer = vectorizer.fit(train['category_name'].values) # 只在训练数据上拟合
column_cat = vectorizer.transform(test['category_name'].values)
#向量化main_category列
vectorizer = vectorizer.fit(train['main_category'].values) # 只在训练数据上拟合
column_mc = vectorizer.transform(test['main_category'].values)
#向量化sub_cat_1列
vectorizer = vectorizer.fit(train['sub_cat_1'].values) # 只在训练数据上拟合
column_sb1 = vectorizer.transform(test['sub_cat_1'].values)
#向量化sub_cat_2列
vectorizer = vectorizer.fit(train['sub_cat_2'].values) # 只在训练数据上拟合
column_sb2 = vectorizer.transform(test['sub_cat_2'].values)
#向量化brand列
vectorizer = vectorizer.fit(train['brand_name'].astype(str)) # 只在训练数据上拟合
brand_encodes = vectorizer.transform(test['brand_name'].astype(str))
print("created OHE columns for main_category,sub_cat_1,sub_cat_2\n")
print(column_cat.shape)
print(column_mc.shape)
print(column_sb1.shape)
print(column_sb2.shape)
print(brand_encodes.shape)
print("="*100)
return column_cat,column_mc,column_sb1,column_sb2,brand_encodes
def get_dummies_item_id_shipping(df):
df['item_condition_id'] = df["item_condition_id"].astype("category")
df['shipping'] = df["shipping"].astype("category")
item_id_shipping = csr_matrix(pd.get_dummies(df[['item_condition_id', 'shipping']],\
sparse=True).values)
return item_id_shipping文本特征向量化
我们分别使用BoW(用uni-和bi-grams)和TFIDF(用uni-、bi-和tri-grams)对文本特征名称和条目描述进行编码。其函数如下:
def vectorizer(train,test,column,no_of_features,n_range,vector_type):
'''
函数使用TFIDF/BoW对文本进行向量化
'''
if str(vector_type) == 'bow':
vectorizer = CountVectorizer(ngram_range=n_range,max_features=no_of_features).fit(train[column]) #拟合
else:
vectorizer = TfidfVectorizer(ngram_range=n_range, max_features=no_of_features).fit(train[column]) # 只在训练数据上拟合
# 我们使用vectorizer将文本转换为矢量
transformed_text = vectorizer.transform(tqdm(test[column]))
###############################
print("After vectorizations")
print(transformed_text.shape)
print("="*100)
return transformed_text使用上述函数的代码如下:
X_train_bow_name = vectorizer(X_train,X_train,'name',100000,(1,2),'bow')
X_test_bow_name = vectorizer(X_train,X_test,'name',100000,(1,2),'bow')
X_train_tfidf_desc = vectorizer(X_train,X_train,'item_description',100000,(1,3),'tfidf')
X_test_tfidf_desc = vectorizer(X_train,X_test,'item_description',100000,(1,3),'tfidf')特征矩阵
最后的矩阵是通过将所有编码特征(包括离散特征和文本特征)以及两个数字特征(即文本描述的字数和名称)串联起来生成的。参考代码如下:
x_train_set = hstack((X_train_bow_name,X_train_tfidf_desc,tr_cat,X_train['wc_name'].values.reshape(-1,1),X_train['wc_desc'].values.reshape(-1,1))).tocsr()
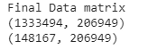
x_test_set = hstack((X_test_bow_name,X_test_tfidf_desc,te_cat,X_test['wc_name'].values.reshape(-1,1),X_test['wc_desc'].values.reshape(-1,1))).tocsr()最终生成的矩阵包含206k多个特征。事实上,这有很多特征。
首次选择模型
为这个问题选择一个合适的算法可能是一项艰巨的任务,尤其是对初学者来说。

我们学习根据数据维度、线性度、训练时间、问题类型等来选择算法,如这里所讨论的。
在我们的分析中,我们首先实验简单的线性模型,如线性回归,支持向量回归,对于这两个模型,我们选择了来自scikit-learn的SGDRegressor 。接下来,我们训练岭回归。
我们使用以下函数使用GridSearchCV超参数调整所有模型的参数:
def hyperparameter_tuning_random(x,y,model_estimator,param_dict,cv_no):
start = time.time()
hyper_tuned = GridSearchCV(estimator = model_estimator, param_grid = param_dict,\
return_train_score=True, scoring = 'neg_mean_squared_error',\
cv = cv_no, \
verbose=2, n_jobs = -1)
hyper_tuned.fit(x,y)
print("\n######################################################################\n")
print ('Time taken for hyperparameter tuning is {} sec\n'.format(time.time()-start))
print('The best parameters_: {}'.format(hyper_tuned.best_params_))
return hyper_tuned.best_params_线性回归
线性回归的目的是减少预测与实际数据之间的误差。我们使用带有“squared_loss”和超参数调整的SGDregressor 训练简单线性回归模型。下面显示了代码:
#超参数调优
parameters = {'alpha':[10**x for x in range(-10, 7)],
}
model_lr_reg = SGDRegressor(loss = "squared_loss",fit_intercept=False,l1_ratio=0.6)
best_parameters_lr = hyperparameter_tuning_random(x_train_set,y_train,model_lr_reg,parameters,3)
model_lr_best_param = SGDRegressor(loss = "squared_loss",alpha = best_parameters_lr['alpha'],\
fit_intercept=False)
model_lr_best_param.fit(x_train_set,y_train)
y_train_pred = model_lr_best_param.predict(x_train_set)
y_test_pred = model_lr_best_param.predict(x_test_set)在我们的测试数据中,这个简单的模型得出了最佳α=0.001的RMSLE为0.513。
SVR:
支持向量回归(SVR)是指用不超过ε的值来预测偏离实际数据的函数。我们使用SGDRegressor训练一个SVR,“epsilon_unsensitive”作为损失,alphas作为超参数。根据我们的测试数据,该模型产生了α=0.0001的RMSLE为0.632。在我们的例子中,简单的线性回归比支持向量机的性能要好得多。SVR代码如下:
#超参数调优
parameters_svr = {'alpha':[10**x for x in range(-4, 4)]}
model_svr = SGDRegressor(loss = "epsilon_insensitive",fit_intercept=False)
best_parameters_svr = hyperparameter_tuning_random(x_train_set,y_train,model_svr,parameters_svr,3)
model_svr_best_param = SGDRegressor(loss = "epsilon_insensitive",alpha = 0.0001,\
fit_intercept=False)
model_svr_best_param.fit(x_train_set,y_train[:,0])
y_train_pred_svr = model_svr_best_param.predict(x_train_set)
y_test_pred_svr = model_svr_best_param.predict(x_test_set)岭回归
岭回归是线性回归的近亲,通过L2范数给出一些正则化来防止过度拟合。我们在线性模型下使用scikit-learn的Ridge得到了很好的拟合,α=6.0的RMSLE为0.490。下面是具有超参数调整的Ridge模型代码:
#超参数调优
parameters_ridge = {'alpha':[0.0001,0.001,0.01,0.1,1.0,2.0,4.0,5.0,6.0]}
model_ridge = Ridge(
solver='auto', fit_intercept=True,
max_iter=100, normalize=False, tol=0.05, random_state = 1,
)
rs_ridge = hyperparameter_tuning_random(x_train_set,y_train,model_ridge,parameters_ridge,3)
ridge_model = Ridge(
solver='auto', fit_intercept=True,
max_iter=100, normalize=False, tol=0.05, alpha=6.0,random_state = 1,
)
ridge_model.fit(x_train_set, y_train)RidgeCV
它是一个交叉验证估计器,可以自动选择最佳超参数。换言之,具有内置交叉验证的岭回归。对于我们的问题,这比Ridge表现得更好,我们构建了RidgeCV模型,根据我们的测试数据,alpha6.0的RMSLE为0.442。代码如下:
from sklearn.linear_model import RidgeCV
print("Fitting Ridge model on training examples...")
ridge_modelCV = RidgeCV(
fit_intercept=True, alphas=[6.0],
normalize=False, cv = 2, scoring='neg_mean_squared_error',
)
ridge_modelCV.fit(x_train_set1, y_train)
preds_ridgeCV = ridge_modelCV.predict(x_test_set1)我们可以观察到RidgeCV表现得最好。为了进一步提高分数,我们正在探索使用深度学习来解决这个问题
8.2深度学习
递归神经网络(RNN)擅长处理序列数据信息。我们使用门控递归单元(GRU),它是一种新型的RNN,训练速度更快。
从GRU中,我们在name, item_description列获取文本特征向量,对于其他类别字段,我们使用嵌入后再展平向量。所有这些共同构成了我们的深度学习模型的80维特征向量。

嵌入
除了训练测试的划分,深度学习(DL)管道的数据准备遵循与ML管道相同的例程。如前所述,DL管道需要密集向量,而神经网络嵌入是将离散变量表示为密集向量的有效方法
标识化和填充
嵌入层要求输入是整数编码的。因此,我们使用Tokenizer API对文本数据进行编码,下面是代码片段:
def tokenize_text(train,test,column):
#参考AAIC课程
global t
t = Tokenizer()
t.fit_on_texts(train[column].str.lower())
vocab_size = len(t.word_index) + 1
#对文档进行整数编码
encoded_text_tr = t.texts_to_sequences(train[column].str.lower())
encoded_text_te = t.texts_to_sequences(test[column].str.lower())
return encoded_text_tr,encoded_text_te,vocab_size标识化后的样本描述数据截图如下:

在标识化之后,我们填充序列。名称和描述文本的长度不同,Keras希望输入序列的长度相同。我们计算超出特定范围的数据点的百分比,以确定填充的长度。
下面显示了选择描述文本填充长度的代码:
print("% of sequence containing len > 160 is")
len(X_train[X_train.wc_desc > 160])/X_train.shape[0]*100
从上面的图像我们可以看到长度在160以上的点的百分比为0.7,即<1%。因此我们用160填充描述文本。类似地,我们计算name列,得到10。对应的代码片段如下所示:
print("% of name containing len > 10 is")
len(X_train[X_train.wc_name > 10])/X_train.shape[0]*100
此外,我们对离散变量进行编码,代码片段如下:
def rank_category(dataset,column_name):
'''这个函数接受列名,并返回具有排名后类别'''
counter = dataset[column_name].value_counts().index.values
total = list(dataset[column_name])
ranked_cat = {}
for i in range(1,len(counter)+1):
ranked_cat.update({counter[i-1] : i})
return ranked_cat,len(counter)
def encode_ranked_category(train,test,column):
'''
这个函数调用rank_category函数并返回已编码的列 '''
train[column] = train[column].astype('category')
test[column] = test[column].astype('category')
cat_list = list(train[column].unique())
ranked_cat_tr,count = rank_category(train,column)
encoded_col_tr = []
encoded_col_te = []
for category in train[column]:
encoded_col_tr.append(ranked_cat_tr[category])
for category in test[column]:
if category in cat_list:
encoded_col_te.append(ranked_cat_tr[category])
else:
encoded_col_te.append(0)
encoded_col_tr = np.asarray(encoded_col_tr)
encoded_col_te = np.asarray(encoded_col_te)
return encoded_col_tr,encoded_col_te,count注意:所有的嵌入都是和模型本身一起学习的。
整个数据准备管道以及编码、标识化和填充都由以下函数执行:
def data_gru(train,test):
global max_length,desc_size,name_size
encoded_brand_tr,encoded_brand_te,brand_len = encode_ranked_category(train,test,'brand_name')
encoded_main_cat_tr,encoded_main_cat_te,main_cat_len = encode_ranked_category(train,test,'main_category')
encoded_sub_cat_1_tr,encoded_sub_cat_1_te,sub_cat1_len = encode_ranked_category(train,test,'sub_cat_1')
encoded_sub_cat_2_tr,encoded_sub_cat_2_te,sub_cat2_len = encode_ranked_category(train,test,'sub_cat_2')
tokenized_desc_tr,tokenized_desc_te,desc_size = tokenize_text(train,test,'item_description')
tokenized_name_tr,tokenized_name_te,name_size = tokenize_text(train,test,'name')
max_length = 160
desc_tr_padded = pad_sequences(tokenized_desc_tr, maxlen=max_length, padding='post')
desc_te_padded = pad_sequences(tokenized_desc_te, maxlen=max_length, padding='post')
del tokenized_desc_tr,tokenized_desc_te
name_tr_padded = pad_sequences(tokenized_name_tr, maxlen=10, padding='post')
name_te_padded = pad_sequences(tokenized_name_te, maxlen=10, padding='post')
del tokenized_name_tr,tokenized_name_te
gc.collect()
train_inputs = [name_tr_padded,desc_tr_padded,encoded_brand_tr.reshape(-1,1),\
encoded_main_cat_tr.reshape(-1,1),encoded_sub_cat_1_tr.reshape(-1,1),\
encoded_sub_cat_2_tr.reshape(-1,1),train['shipping'],\
train['item_condition_id'],train['wc_desc'],\
train['wc_name']]
test_inputs = [name_te_padded,desc_te_padded,encoded_brand_te.reshape(-1,1),\
encoded_main_cat_te.reshape(-1,1),encoded_sub_cat_1_te.reshape(-1,1),\
encoded_sub_cat_2_te.reshape(-1,1),test['shipping'],\
test['item_condition_id'],test['wc_desc'],\
test['wc_name']]
item_condition_counter = train['item_condition_id'].value_counts().index.values
list_var = [brand_len,main_cat_len,sub_cat1_len,sub_cat2_len,len(item_condition_counter)]
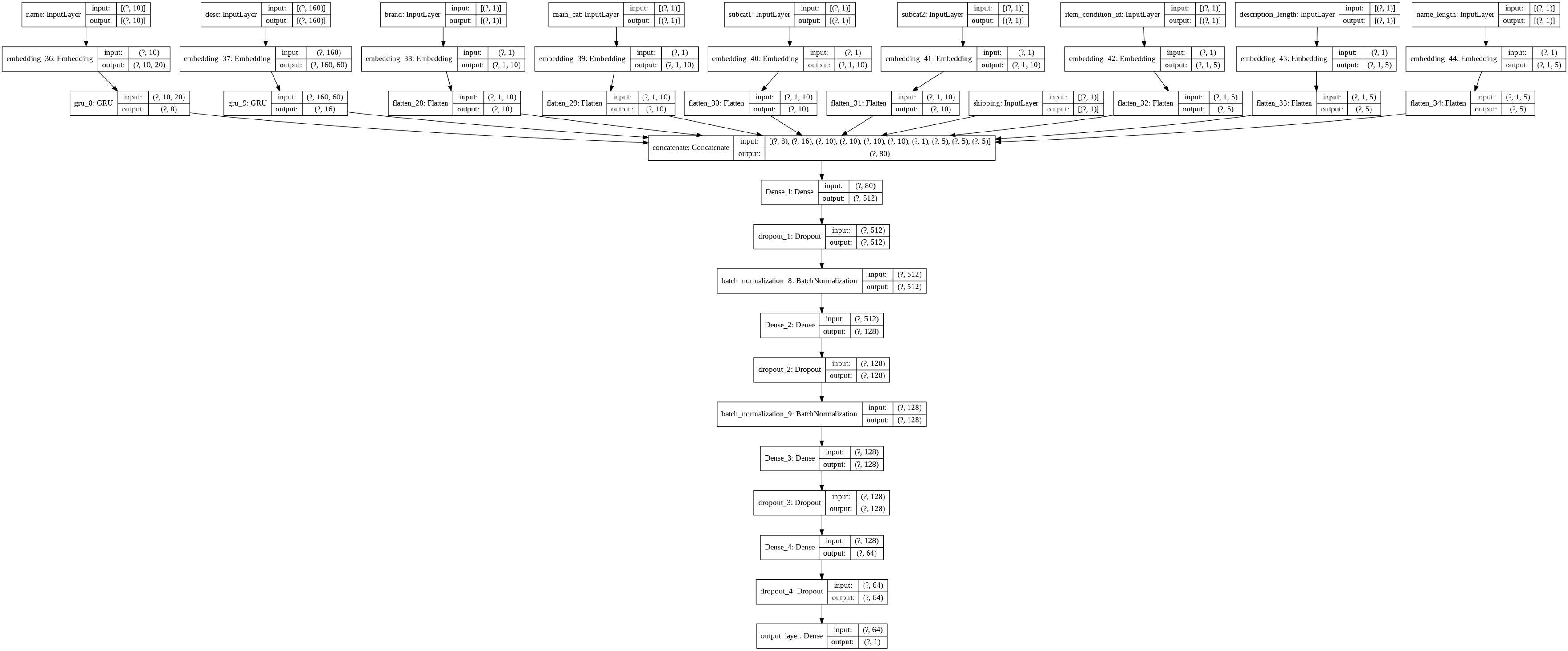
return train_inputs,test_inputs,list_var网络体系结构
对当前网络设计的分析正是受到了这个的启发(https://www.kaggle.com/valkling/mercari-rnn-2ridge-models-with-notes-0-42755#RNN-Model)。此外,我们在这个框架中对Dropout层和batch-normalization层进行了实验。以下是构建我们网络的代码片段:
def construct_GRU(train,var_list,drop_out_list):
#name的GRU输入层
input_name = tf.keras.layers.Input(shape=(10,), name='name')
embedding_name = tf.keras.layers.Embedding(name_size, 20)(input_name)
gru_name = tf.keras.layers.GRU(8)(embedding_name)
#description的GRU输入层
input_desc = tf.keras.layers.Input(shape=(max_length,), name='desc')
embedding_desc = tf.keras.layers.Embedding(desc_size, 60)(input_desc)
gru_desc = tf.keras.layers.GRU(16)(embedding_desc)
#input layer for brand_name的输入层
input_brand = tf.keras.layers.Input(shape=(1,), name='brand')
embedding_brand = tf.keras.layers.Embedding(var_list[0] + 1, 10)(input_brand)
flatten1 = tf.keras.layers.Flatten()(embedding_brand)
#main_category的输入层
input_cat = tf.keras.layers.Input(shape=(1,), name='main_cat')
Embed_cat = tf.keras.layers.Embedding(var_list[1] + 1, \
10,input_length=1)(input_cat)
flatten2 = tf.keras.layers.Flatten()(Embed_cat)
#sub_cat_1的输入层
input_subcat1 = tf.keras.layers.Input(shape=(1,), name='subcat1')
Embed_subcat1 = tf.keras.layers.Embedding(var_list[2] + 1, \
10,input_length=1)(input_subcat1)
flatten3 = tf.keras.layers.Flatten()(Embed_subcat1)
#sub_cat_2的输入层
input_subcat2 = tf.keras.layers.Input(shape=(1,), name='subcat2')
Embed_subcat2 = tf.keras.layers.Embedding(var_list[3] + 1, \
10,input_length=1)(input_subcat2)
flatten4 = tf.keras.layers.Flatten()(Embed_subcat2)
#shipping的输入层
input_shipping = tf.keras.layers.Input(shape=(1,), name='shipping')
#item_condition_id的输入层
input_item = tf.keras.layers.Input(shape=(1,), name='item_condition_id')
Embed_item = tf.keras.layers.Embedding(var_list[4] + 1, \
5,input_length=1)(input_item)
flatten5 = tf.keras.layers.Flatten()(Embed_item)
#数字特征的输入层
desc_len_input = tf.keras.layers.Input(shape=(1,), name='description_length')
desc_len_embd = tf.keras.layers.Embedding(DESC_LEN,5)(desc_len_input)
flatten6 = tf.keras.layers.Flatten()(desc_len_embd)
#name_len的输入层
name_len_input = tf.keras.layers.Input(shape=(1,), name='name_length')
name_len_embd = tf.keras.layers.Embedding(NAME_LEN,5)(name_len_input)
flatten7 = tf.keras.layers.Flatten()(name_len_embd)
# 级联
concat_layer = tf.keras.layers.concatenate(inputs=[gru_name,gru_desc,flatten1,flatten2,flatten3,flatten4,input_shipping,flatten5,\
flatten6,flatten7],name="concatenate")
#全连接层
Dense_layer1 = tf.keras.layers.Dense(units=512,activation='relu',kernel_initializer='he_normal',\
name="Dense_l")(concat_layer)
dropout_1 = tf.keras.layers.Dropout(drop_out_list[0],name='dropout_1')(Dense_layer1)
batch_n1 = tf.keras.layers.BatchNormalization()(dropout_1)
Dense_layer2 = tf.keras.layers.Dense(units=128,activation='relu',kernel_initializer='he_normal',\
name="Dense_2")(batch_n1)
dropout_2 = tf.keras.layers.Dropout(drop_out_list[1],name='dropout_2')(Dense_layer2)
batch_n2 = tf.keras.layers.BatchNormalization()(dropout_2)
Dense_layer3 = tf.keras.layers.Dense(units=128,activation='relu',kernel_initializer='he_normal',\
name="Dense_3")(batch_n2)
dropout_3 = tf.keras.layers.Dropout(drop_out_list[2],name='dropout_3')(Dense_layer3)
Dense_layer4 = tf.keras.layers.Dense(units=64,activation='relu',kernel_initializer='he_normal',\
name="Dense_4")(dropout_3)
dropout_4 = tf.keras.layers.Dropout(drop_out_list[3],name='dropout_4')(Dense_layer4)
#输出层
final_output = tf.keras.layers.Dense(units=1,activation='linear',name='output_layer')(dropout_4)
model = tf.keras.Model(inputs=[input_name,input_desc,input_brand,input_cat,input_subcat1,input_subcat2,\
input_shipping,input_item,desc_len_input,name_len_input],
outputs=[final_output])
#我们指定了模型的输入和输出
print(model.summary())
img_path = "GRU_model_2_lr.png"
plot_model(model, to_file=img_path, show_shapes=True, show_layer_names=True)
return model下面是我们的网络:
深度学习模型
共训练了四个不同Dropout和学习率的模型。每个网络由四个Dropout层组成,对于每一层,我们尝试对所有模型使用不同的Dropout率(有关详细信息,请参阅结果)。
训练
对于训练模型1和模型2,我们使用具有默认学习率的Adam优化器。此外,这些模型被训练为3个epoch,batch量大小加倍。模型1和模型2的试验数据的RMSLE分别为0.436和0.441。模型训练说明如下:

模型3和4使用Adam优化器和预定学习率进行训练,batch大小为1024个。对于epoch 1和2,学习率为0.005,对于最后一个epoch,我们将其降低到0.001。模型4的训练如下:

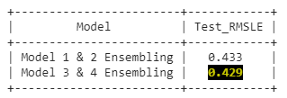
模型平均集成
模型平均是一种降低神经网络高方差的集成学习技术。在当前的分析中,我们对在不同条件下训练的模型进行集成,这些模型的正则化程度不同。每一款模型的训练时间约为30至35分钟。考虑到训练时间,我们只包含了两个模型。因此,在四个模型中,创建了两个模型组,即一个来自模型1和模型2,实现后RMSLE 0.433,另一个来自模型3和4,RMSLE为0.429
集成模型1和2的代码如下所示:
#https://machinelearningmastery.com/model-averaging-ensemble-for-deep-learning-neural-networks/
y_hats = np.array([preds_m1_te,te_preds_m2]) #making an array out of all the predictions
# 平均集成
mean_preds = np.mean(y_hats, axis=0)
print("RMSLE on test: {}".format(rmsle_compute(X_test['price'],scale_back(mean_preds))))我们观察到模型3和4的集成表现最好。
最终模型
为了获得Kaggle的最终分数,我们现在在Kaggle中进行训练。我们建立了两个模型相同的模型模型3和4进行装配。下面展示的是在Kaggle训练过的模型的截图:
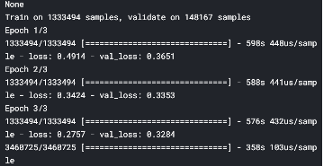
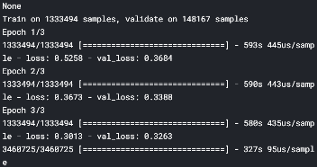
对这两个模型的平均模型在我们的最终测试数据(包含约340万个产品)中产生0.428的Kaggle分数。因此,我们的得分排名前10%。
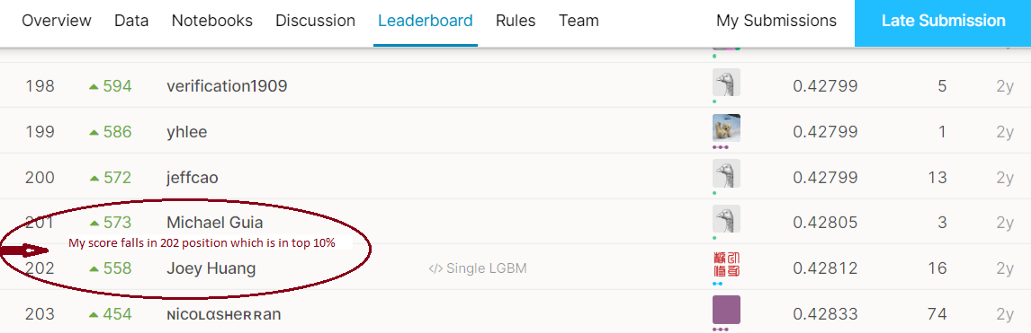
9.结果
以下是模型输出的摘要截图:
机器学习管道的输出:

深度学习管道的输出:

集成模型的输出
Kaggle提交分数:

10.改善RMSLE的尝试
提高我们得分的策略如下:
-
不去除停用词:这个问题的一个关键是删除停用词会影响RMSLE分数。保留停用词可以提高分数。
-
考虑到更多的文本特征用于模型构建:我们总共得到206k个特征,其中包括仅从文本数据中提取的200k个特征。在这个问题中,更加重视文本信息可以提高分数。
-
bigram和Tri-gram:在NLP中,如果我们打算在向量化过程中添加一些语义,通常会包含n-gram,如bigram、Tri-gram等。
-
根据价格过滤数据:Mercari不允许发布低于3美元的商品。因此,那些产品价格低于3美元的是错误的。删除它们将有助于模型的性能更好。
-
小批量和少epoch的模型训练:使用1024的batch和更好的学习率调度程序提高了分数
-
整合两个神经网络模型:这一策略是目前研究所独有的,它将领先者的得分推得更高。我们通过训练两个神经网络模型并建立它们的集成来进行预测分析。
11.未来工作
可以通过探索以下选项来提高分数:
-
使用多层感知器是解决这一问题的常用方法
-
利用CNN与RNN结合处理文本数据
-
添加更多GRU层或进一步微调
这些是我们随后将要探讨的一些可能性。
12.GitHub存储库
请参考我的GitHub存储库查看完整代码:https://github.com/syogeeshwari/Mercari_price_prediction
13.参考引用
-
https://github.com/pjankiewicz/mercarisolution/blob/master/presentation/build/yandex.pdf
-
https://www.kaggle.com/valkling/mercari-rnn-2ridge-models-with-notes-0-42755
-
https://medium.com/analytics-vidhya/mercari-price-suggestion-challenge-66500ac1f88a
-
https://machinelearningmastery.com/ensemble-methods-for-deep-learning-neural-networks/
-
https://machinelearningmastery.com/model-averaging-ensemble-for-deep-learning-neural-networks/
-
https://www.appliedaicourse.com/course/11/Applied-Machine-learning-course
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/10/19/mercari%e6%95%b0%e6%8d%ae%e9%9b%86-%e6%9c%ba%e5%99%a8%e5%ad%a6%e4%b9%a0%e6%b7%b1%e5%ba%a6%e5%ad%a6%e4%b9%a0%e8%a7%86%e8%a7%92/
