
文档解析
文档解析是将信息转换为有价值的业务数据的第一步。这些信息通常以表格形式存储在商业文档中,或者顺便存储在没有明显图形边界的数据块中。无边界表格可能有助于简化我们人类对半结构化数据的视觉感知。从机器阅读的角度来看,这种在页面上呈现信息有相当多的缺点,这使得很难将属于假定的表结构的数据与周围的文本上下文分开。semi-structured data
作为一项业务挑战,表格数据提取可能有几个特别的或基于启发式�规则的解决方案,如果表格的布局或样式稍有不同,这些解决方案肯定会失败。在大范围内,人们应该使用更通用的方法来识别图像中的表状结构,更具体地说,应该使用基于深度学习的对象检测方法。
本教程的范围:
- 基于深度学习的目标检测
- TF2目标检测API的安装和设置
- 数据准备
- 型号配置
- 模范培训与节约
- 真实图像中的表格检测和细胞识别
基于深度学习的目标检测
Adrian Rosebrock,一位著名的简历研究人员,在他的《深度学习对象检测温和指南》(EuroœGentle Guide to Deep Learning Object Detect)《EURO�》中指出:EUROUREœ对象检测,无论是通过深度学习还是其他计算机视觉技术执行,都建立在图像分类的基础上,并寻求精确定位对象出现的区域(EUROU�)。按照他的建议,构建自定义对象检测器的一种方法是选择任何分类器,并在其之前使用算法来选择并提供可能包含对象的图像区域。在此方法中,您可以自由决定是使用传统的ML算法进行图像分类(是否使用CNN作为特征提取器),还是训练简单的神经网络来处理任意的大型数据集。尽管被证明是有效的,这种被称为R-CNN的两阶段目标检测范例仍然依赖于繁重的计算,并且不适合实时应用。Gentle guide to deep learning object detection utilising or not CNN as a feature extractor train a simple neural network
在上述帖子中还进一步指出,另一种方法是将预先训练的分类网络作为多组件深度学习对象检测框架(例如更快的R-œ、SSD或YOLO)中的基础(骨干)网络来对待�。因此,您将从其完整的端到端可培训架构中获益。
无论选择哪种方式,它都会使您进一步面对重叠边界框的问题。下面,我们将谈及为此目的执行非最大抑制。
同时,请参考任意新类的对象检测器的迁移学习流程图(见交互视图):interactive view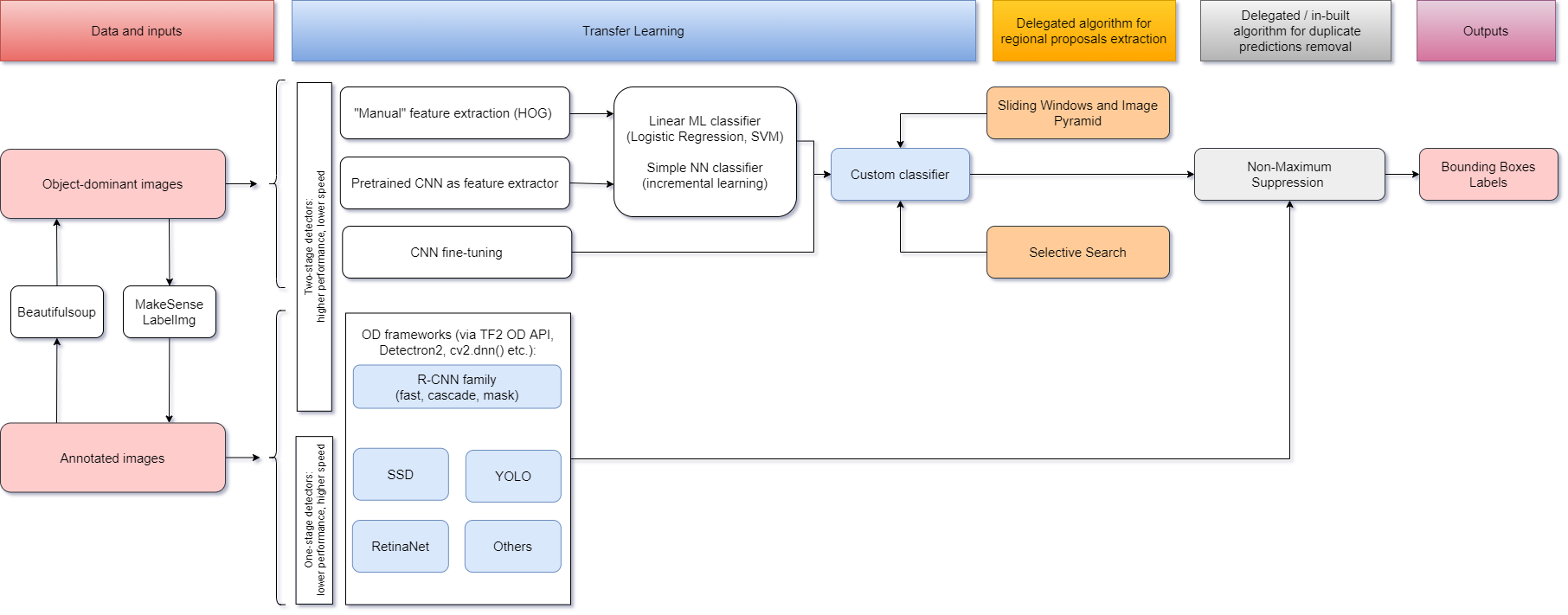
由于第二种方法具有速度快、繁琐、准确度高等优点,已被广泛用于商业和科学论文中的表状结构识别。例如,您可以很容易地找到使用YOLO、RetinaNet、Cascade R-CNN和其他框架从PDF文档中提取表格数据的实现。YOLO RetinaNet Cascade R-CNN
继续学习本教程,您将了解如何使用像TensorFlow(TF2)object Detection API这样的工具轻松地使用预先训练好的最先进的模型构建您的自定义对象检测器。
在您开始之前
请注意,这不是对深度学习对象检测的详尽介绍,而是对与TF2对象检测API(和其他工具)交互以解决特定开发环境(Anaconda/Win10)中的显著业务问题(如无边界表格检测)的逐个阶段的描述。在这篇文章的整个睡觉中,我们将比其他方面更详细地报道我们建模过程的某些方面和结果。尽管如此,您将在™中找到跟随我们实验的基本代码示例。要继续操作,您应该安装Anaconda和Tesseract,并下载协议Buf并将其添加到PATH中。
TF2目标检测API的安装和设置
在您选择的路径下创建一个新文件夹,我们在下文中将其称为“EUROUE˜PROJECT”“EUROU™”的根文件夹“EUROU™”。从您的终端窗口逐个运行以下命令:
# from <project’s root folder>
conda create -n <new environment name> \
python=3.7 \
tensorflow=2.3 \
numpy=1.17.4 \
tf_slim \
cython \
git它将在您的本地环境中安装核心和一些帮助器库,以使用TF2对象检测API并管理您的训练数据集。从这一步开始,您应该能够从TF2 Model Garden下载一个预先训练好的模型,并从它获得各自预先训练课程的推论。get inferences from it
数据准备
我希望你到目前为止™已经成功了!请记住,我们的最终目标是使用预先训练的模型执行迁移学习,以检测单个˜无边界欧元™类,该模型在初始培训时对此一无所知。如果你研究过我们的迁移学习流程图,你应该已经注意到,我们整个过程的起点是一个数据集,不管有没有注释。如果您需要注释,有大量的解决方案可供选择。选择与我们的示例兼容的XML格式的注释。tons of solutions
我们拥有的带注释的数据越多越好(重要的是:这篇文章的所有表格图像都是从像这样的开放数据源中选择的,并由作者进行注释/重新注释)。但是,一旦您尝试手动处理标记为™的数据,™就会明白这项工作有多单调乏味。不幸的是,没有一个流行的用于图像增强的python库能够处理所选的边界框。在不增加收集和注释新数据的高成本的情况下乘以初始数据集符合我们的利益。当TF-IMAGE包变得方便时就是这种情况。this one tf-image
上面的脚本将随机转换原始图像以及对象的边界框,并将新图像和相应的™文件保存到磁盘。这就是我们的数据集经过三倍扩展后的样子:
下一步将包括将数据拆分成训练集和测试集。基于TF2对象检测API的模型需要一种用于所有输入数据的特殊格式,称为TFRecord。您可以在™存储库中找到相应的脚本来拆分和转换您的数据。Github repository
型号配置
在这一步中,我们将创建一个标签映射文件(.pbtxt)来将我们的类标签(™˜Borderless)™链接到某个整数值。TF2对象检测API需要此文件用于培训和检测目的:
item {
id: 1
name: ‘borderless’
}实际的模型配置发生在相应的Pipeline.config文件中。您可以阅读模型配置简介,并决定是手动配置文件,还是通过运行Github存储库中的脚本来配置文件。intro to model configuration Github repository
现在,您的项目-euro™的根文件夹可能如下所示:
📦borderless_tbls_detection
┣ 📂images
┃ ┣ 📂processed
┃ ┃ ┣ 📂all_annots
┃ ┃ ┃ ┗ 📜…XML
┃ ┃ ┗ 📂all_images
┃ ┃ ┃ ┗ 📜…jpg
┃ ┣ 📂splitted
┃ ┃ ┣ 📂test_set
┃ ┃ ┃ ┣ 📜…jpg
┃ ┃ ┃ ┗ 📜…XML
┃ ┃ ┣ 📂train_set
┃ ┃ ┃ ┣ 📜…jpg
┃ ┃ ┃ ┗ 📜…XML
┃ ┃ ┗ 📂val_set
┃ ┗ 📜xml_style.XML
┣ 📂models
┃ ┗ 📂…
┣ 📂scripts
┃ ┣ 📜…py
┣ 📂train_logs
┣ 📂workspace
┃ ┣ 📂data
┃ ┃ ┣ 📜label_map.pbtxt
┃ ┃ ┣ 📜test.csv
┃ ┃ ┣ 📜test.record
┃ ┃ ┣ 📜train.csv
┃ ┃ ┣ 📜train.record
┃ ┃ ┣ 📜val.csv
┃ ┃ ┗ 📜val.record
┃ ┣ 📂models
┃ ┃ ┗ 📂efficientdet_d1_coco17_tpu-32
┃ ┃ ┃ ┗ 📂v1
┃ ┃ ┃ ┃ ┗ 📜pipeline.config
┃ ┣ 📂pretrained_models
┃ ┃ ┗ 📂datasets
┃ ┃ ┃ ┣ 📂efficientdet_d1_coco17_tpu-32
┃ ┃ ┃ ┃ ┣ 📂checkpoint
┃ ┃ ┃ ┃ ┃ ┣ 📜checkpoint
┃ ┃ ┃ ┃ ┃ ┣ 📜ckpt-0.data-00000-of-00001
┃ ┃ ┃ ┃ ┃ ┗ 📜ckpt-0.index
┃ ┃ ┃ ┃ ┣ 📂saved_model
┃ ┃ ┃ ┃ ┃ ┣ 📂assets
┃ ┃ ┃ ┃ ┃ ┣ 📂variables
┃ ┃ ┃ ┃ ┃ ┃ ┣ 📜variables.data-00000-of-00001
┃ ┃ ┃ ┃ ┃ ┃ ┗ 📜variables.index
┃ ┃ ┃ ┃ ┃ ┗ 📜saved_model.pb
┃ ┃ ┃ ┃ ┗ 📜pipeline.config
┃ ┃ ┃ ┗ 📜efficientdet_d1_coco17_tpu-32.tar.gz
┃ ┣ 📜exporter_main_v2.py
┃ ┗ 📜model_main_tf2.py
┣ 📜config.py
â”— 📜setup.py模范培训与节约
我们™做了很多工作才来到这里,把所有的东西都准备好开始训练。以下是如何做到这一点:
# from <project’s root folder>
tensorboard — logdir=<logs folder>现在,您可以在http://localhost:6006:的浏览器中监控培训过程http://localhost:6006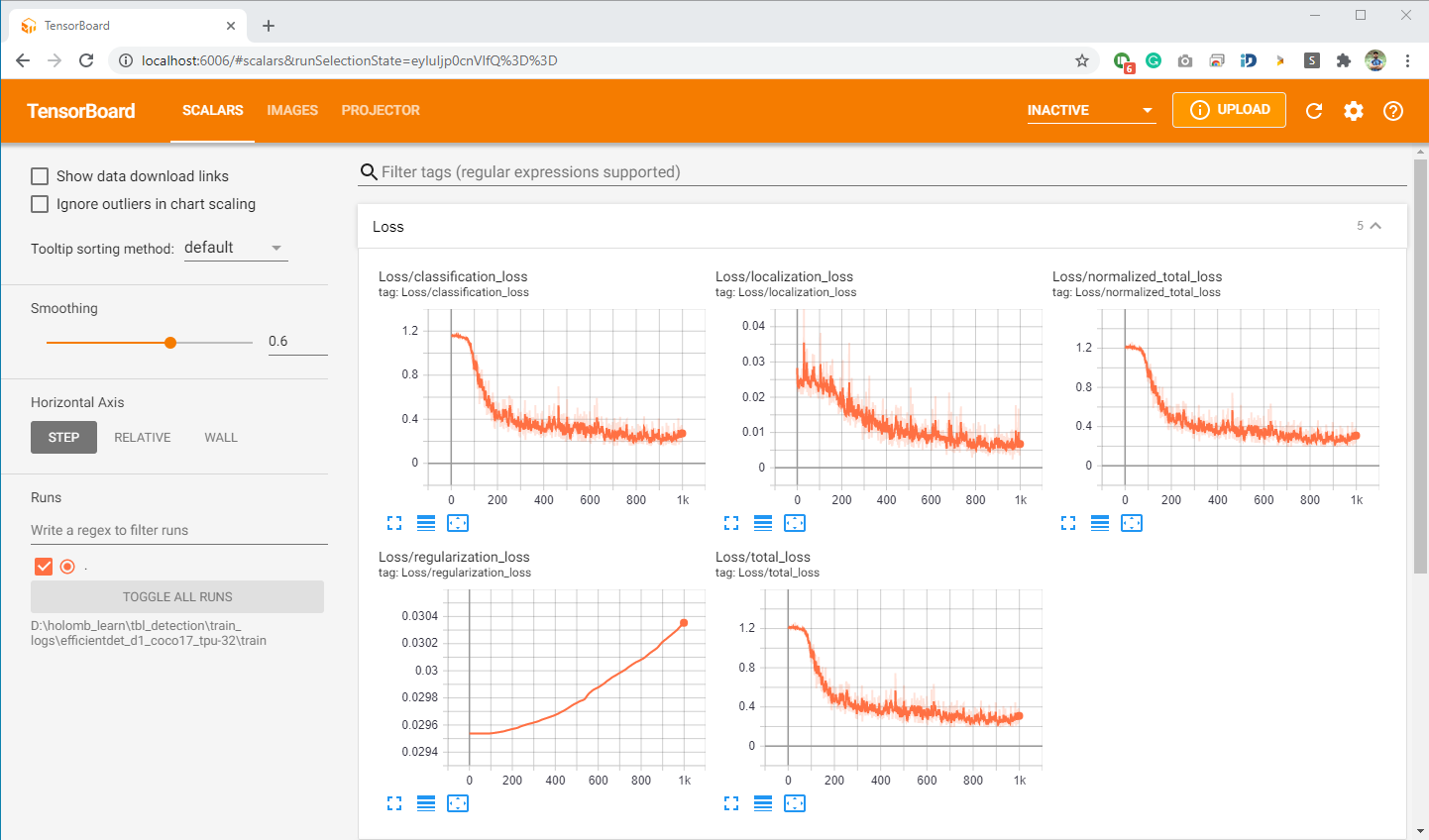
要在培训完成后导出您的模型,只需运行以下命令:
# from <project’s root folder>
python workspace\exporter_main_v2.py \
— input_type=image_tensor \
— pipeline_config_path=%PIPELINE_CONFIG_PATH% \
— trained_checkpoint_dir=%MODEL_DIR% \
— output_directory=saved_models\efficientdet_d1_coco17_tpu-32图像中的表格检测和单元格识别
网管和借条
保存了新的微调模型后,就可以开始检测文档中的表了。前面我们已经提到了目标检测系统的一个不可避免的问题-重叠边界框。考虑到我们正在处理的无边界表的过度分段特性,我们的模型偶尔会为单个对象输出比您预期的更多的边界框。毕竟,这是我们的物体探测器正确发射的标志。(™:这是一个信号,表明我们的物体探测器发射正确。)要处理重叠边界框(引用同一对象)的移除,可以使用非最大抑制。non-maximum suppression
Ğ�еRe是我们检测器的推论在执行非最大抑制后的原始外观:
似乎我们已经成功地解决了这些问题,用预测的重叠矩形包围了一个对象,但我们的检测仍然没有达到地面真实边界框的要求。™将会发生,因为没有一个模型是完美的。我们可以用交集对并集(IOU)比率来衡量我们检测器的准确性。作为分子,我们计算预测包围盒和地面真实包围盒之间的重叠面积。作为分母,我们计算预测边界框和地面真实边界框所包含的面积。借条得分>0.5时通常被认为是欧元良好的˜™预测[罗森布罗克,2016年]。Rosenbrock, 2016
对于我们测试集中的一些映像,我们有以下指标:
细胞识别和OCR
这些将是我们的三部分算法的最后步骤:在检测到(1)表之后,我们将(2)使用OpenCV识别其单元格(因为该表是无边界的),并将它们彻底分配到适当的行和列,然后继续(3)通过使用pytesseract的光学字符识别(OCR)从每个分配的单元格中提取文本。
大多数单元格识别算法都是基于表格的线条结构。清晰且可检测的线条是正确识别细胞所必需的。因为我们的表格没有,我们将手动重建表格网格,在阈值处理和调整大小的图像上搜索白色垂直和水平间隙。此方法与这里使用的方法有些类似。here
完成此步骤后,我们可以使用OpenCV查找轮廓(即我们的单元格边框),使用以下命令将它们排序并分配到表格状结构中:
整个工作流程如图所示: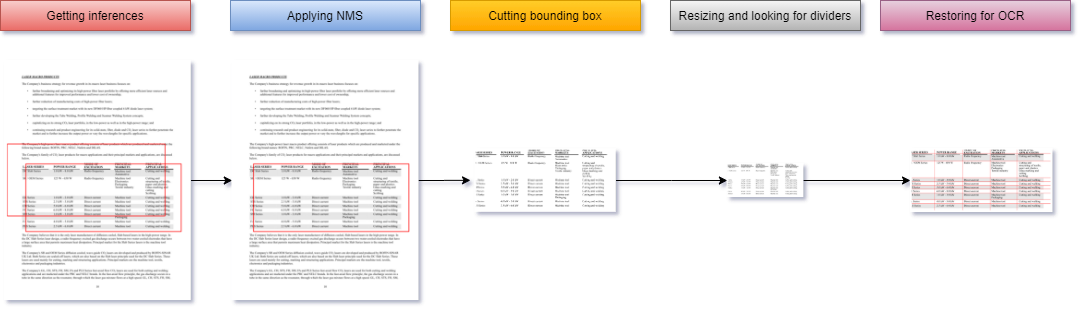
在这一点上,我们已经按照正确的顺序对所有框和它们的值进行了排序。它只需要取出每个基于图像的盒子,通过膨胀和侵蚀为OCR做好准备,然后让pytesseract识别包含的字符串:
最后的想法
哦,这是一个很长的步行™!我们的自定义对象检测器可以识别文档中的半结构化信息块(也称为无边框表格),以进一步将其转换为机器可读的文本。虽然这个模型并不像我们预期的那样准确。因此,我们有很大的改进空间:
- 在我们模型的配置文件中进行更改
- 与模型花园中的其他模型一起玩耍
- 执行更保守的数据增强
- 尝试重用先前针对表数据进行培训的模型(尽管不适用于TF2对象检测API)
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/06/22/%e5%9f%ba%e4%ba%8e%e6%b7%b1%e5%ba%a6%e5%ad%a6%e4%b9%a0%e5%92%8copencv%e7%9a%84%e6%97%a0%e8%be%b9%e7%95%8c%e8%a1%a8%e6%a0%bc%e6%a3%80%e6%b5%8b/
