
里程碑:传统探测器
早期的大多数目标检测算法都是基于手工制作的特征构建的。由于当时缺乏有效的图像表示,人们不得不设计复杂的特征表示,以及各种加速技巧来耗尽有限的计算资源。
维奥拉·琼斯探测器(2001)
原文:使用增强的简单特征级联进行快速目标检测Rapid Object Detection using a Boosted Cascade of Simple Features
18年前(本文发表于2019年),P.Viola和M.Jones首次在没有任何约束(例如肤色分割)的情况下实现了人脸的实时检测。
主播检测器遵循最直接的检测方式,即滑动窗口:遍历图像中所有可能的位置并进行缩放,以查看是否有任何窗口包含人脸。虽然这似乎是一个非常简单的过程,但其背后的计算远远超出了当时的计算机-欧元™的能力。主播检测器融合了三项重要技术,极大地提高了检测速度:
整体图像
积分图像是一种加速盒滤波或卷积过程的计算方法。VJ检测器采用Haar小波作为图像的特征表示。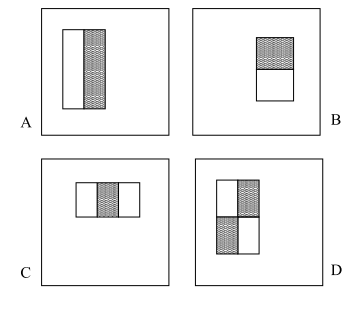
积分图像使得主播检测器中每个窗口的计算复杂度与其窗口大小无关。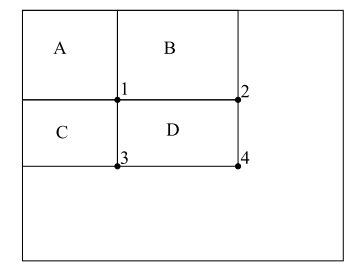
位置1处的积分图像的值是矩形A中像素的总和。位置2处的值是A+B,位置3处的值是A+C,位置4处的值是A+B+C+D。然后,D内的和可以计算为4+1-(2+3)。
功能选择

作者没有使用一组人工选择的Haar基滤波器,而是使用Adboost算法从一个巨大的随机特征库(约180k维)中选择了一小部分对人脸检测最有帮助的特征。每一轮提升都会从18万个潜在特征中选择一个特征。
问:180k维的特征池到底是什么?
原始论文声称-EUROœ考虑到探测器的基本分辨率是24×24,详尽的矩形特征集相当大,超过180,000。?EURO�因此我认为?EUROœ180K?EURO�就是从这里开始的。但是如何计算准确的数字呢?这实际上取决于功能的总数。如果我们遵循OpenCV中建议的约定,使用如下所示的5个功能:suggested in OpenCV
功能池的总大小可以按如下所示计算。因此,当使用5个特征时,矩形特征集的大小为160k,而当使用6个特征时,大小为180k。
检测级联
在VJ检测器中引入了多级检测模式,减少了背景窗口的计算量,增加了人脸目标的计算量。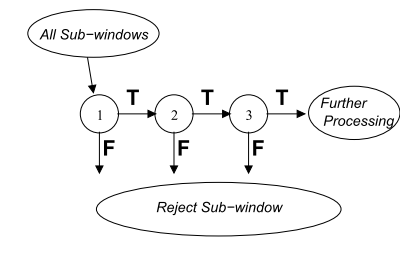
检测过程的总体形式是退化决策树的形式,我们称之为“EUROUREœCASCADE?EURE�”。来自第一分类器的肯定结果触发对第二分类器的评估,该第二分类器也已被调整以实现非常高的检测率。第二个分类器的肯定结果会触发第三个分类器,依此类推。任何时候的否定结果都会导致立即拒绝子窗口。级联中的阶段是通过使用AdaBoost训练分类器,然后调整阈值来最小化假阴性来构建的。
级联的结构反映了这样一个事实,即在任何单个图像内,绝大多数子窗口都是负的。因此,级联试图在尽可能早的阶段拒绝尽可能多的底片。虽然肯定的实例会触发级联中每个分类器的求值,但这是非常罕见的事件。
参考文献
生猪检测器(2005)
原文:用于人体检测的定向梯度直方图Histograms of Oriented Gradients for Human Detection
HOG可以认为是对当时尺度不变特征变换和形状上下文的重要改进。为了平衡特征不变性(包括平移、比例、光照等)和非线性(区分不同的对象类别),HOG描述符被设计为在均匀间距的密集网格上计算,并使用重叠的局部对比度归一化来提高精度。
虽然HOG可以用来检测各种对象类别,但它的主要动机是行人检测问题。为了检测不同大小的对象,HOG检测器多次重新缩放输入图像,同时保持检测窗口的大小不变。
方向梯度直方图(HOG)的计算过程
生猪可视化
基于变形零件的模型(DPM)(2008)
原文:基于区分训练部分模型的目标检测Object Detection with Discriminatively Trained Part Based Models
DPM作为VOC-07、-08和-09检测挑战的获胜者,是传统目标检测方法的巅峰。DPM遵循?EUROœCONVERVER?EURO�的检测哲学,其中训练可以简单地视为学习适当的对象分解方式,而推理可以被认为是对不同对象部分的检测的集成。在这种情况下,可以将训练简单地视为学习适当的对象分解方式,而推理可以被认为是对不同对象部分的检测的集成。例如,检测一辆œ汽车�的问题可以看作是检测它的车窗、车身和轮子。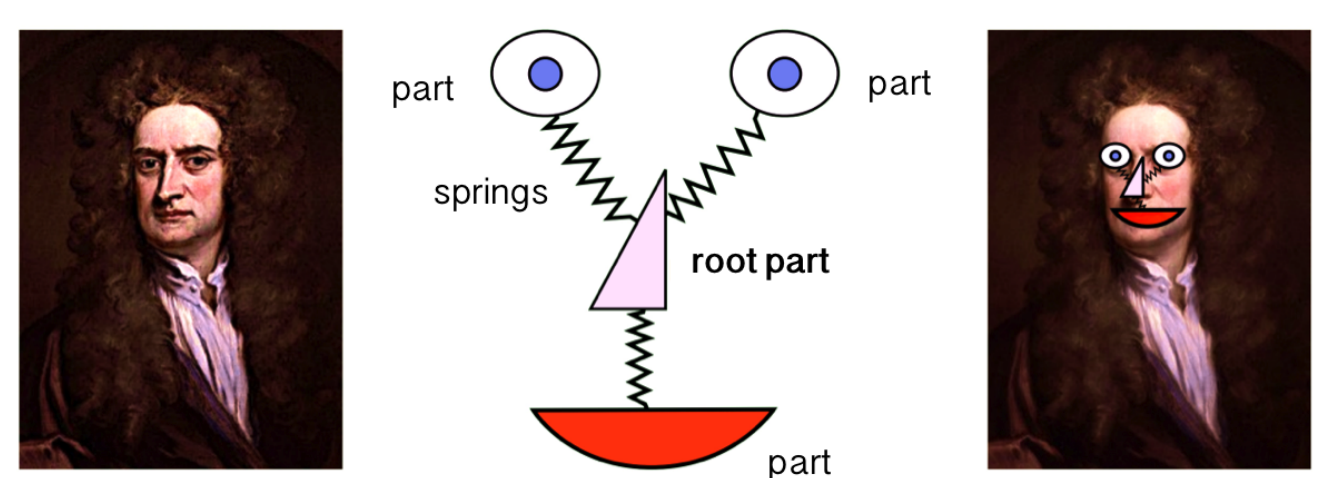
要素地图和过滤
特征地图是其条目是从图像中密集的位置网格计算的d维特征向量的数组。直观地说,每个特征向量描述一个局部图像块。在实践中,我们使用HOG功能的变体。
过滤是由d维权重向量阵列定义的矩形模板。过滤F在要素地图G中的位置(x,y)处的响应或得分是该过滤在(x,y)处左上角的要素地图的一个子窗口的?EUROUREœ点积?�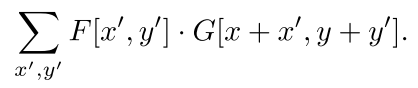
生猪特征金字塔
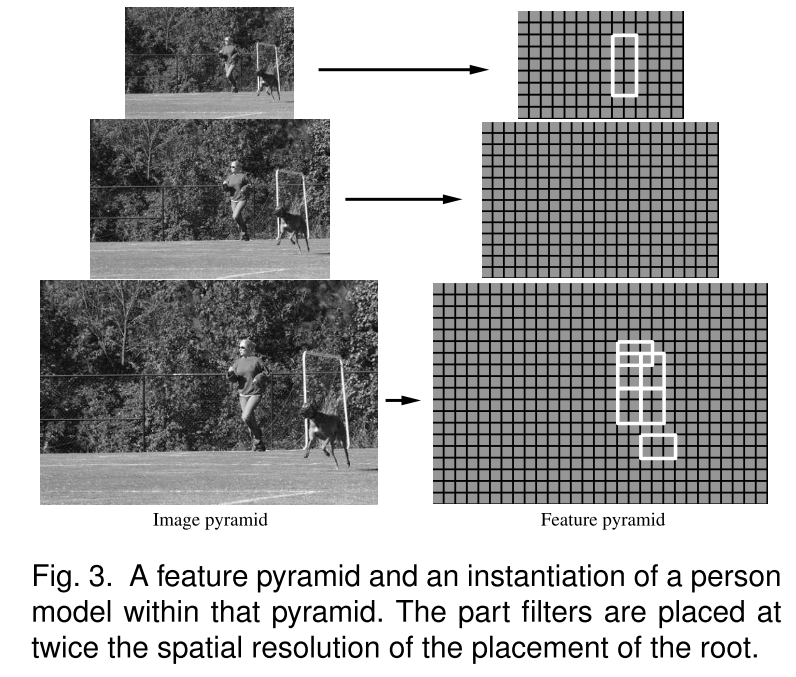
我们希望在图像中定义不同位置和不同比例的分数。这是使用要素棱锥体来完成的,该要素棱锥体在固定范围内为有限数量的比例指定要素地图。在实践中,我们通过反复平滑和次采样来计算标准图像金字塔,然后从图像金字塔的每一层计算特征地图来计算特征金字塔。
要素金字塔中的比例采样由参数宋»决定,该参数是我们需要在金字塔中向下移动以获得以另一个地图的两倍分辨率计算的要素地图所需的层数。在实践中,我们已经在训练中使用了错误»=5,在测试时使用了错误»=10。尺度空间的精细采样对于我们的模型获得高性能是很重要的。
设F是一个w-h过滤。设H是特征棱锥体,p=(x,y,l)指定金字塔第l层中的位置(x,y)。设次†(H,p,w,h)表示通过将H的w-h子窗口中的特征向量与左上角p处的行长顺序连接而获得的向量。F在p处的得分是Fâeuro™·next†(H,p,w,h),其中F?euro™是通过将F中的权重向量按行较多的顺序连接而获得的向量。由于子窗口维度由过滤F的维度隐式定义,因此下面我们编写Fâuro™?·next†(H,p)。
可变形零件模型
我们的星形模型由大致覆盖整个对象的粗根过滤(它定义了一个检测窗口)和覆盖对象较小部分的较高分辨率的部分过滤器(金字塔中向下的层次)定义。
具有n个部分的对象的模型由(n+2)元组(F0,P1,.。。,Pn,b)其中F0是根过滤,Pi是第i部分的模型,b是实值偏移项。每个零件模型由3元组(Fi,Vi,di)定义,其中Fi是第i部分的过滤,Vi是指定相对于根位置的第i部分的欧元锚�位置的二维向量,并且di是指定二次函数的系数的四维向量,该二次函数定义相对于锚位置的部件的每个可能放置的变形成本。
对象假设指定模型中每个过滤在特征金字塔中的位置,z=(P0,.。。,pn),其中pi=(xi,yi,li)指定第i个过滤的级别和位置。我们要求每个部分的级别都是这样的:对于i>0,该级别的特征映射是以根级别的两倍分辨率li=10∑Respon»计算的。
假设的分数由每个过滤在其各自位置处的分数(数据项)减去取决于每个部分相对于根部的相对位置(空间先验)的变形成本,加上偏差,
如果di=(0,0,1,1),则第i部分的变形成本是其实际位置与其锚点位置相对于根部的平方距离。一般情况下,变形代价是位移的任意可分二次函数。当我们将多个模型组合成一个混合模型时,在得分中引入了偏差项,使得多个模型的得分具有可比性。
假设z的分数可以用模型参数的向量和向量的次要的ˆ(H,z)之间的点积ˆ(H,z)来表示,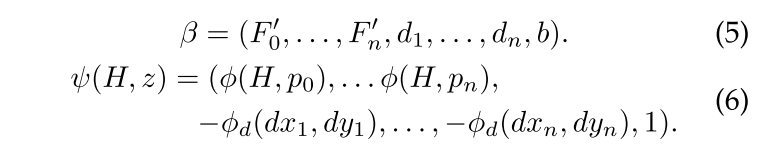
匹配
为了检测图像中的对象,我们根据部件的最佳可能位置计算每个根位置的总分数,
高得分的根位置定义了检测,而产生高得分的根位置的部分的位置定义了完整的对象假设。
混合模型
具有m个成分的混合模型由m元组定义,M=(M1,.。。,mm),其中Mc是第c个分量的模型。混合模型的对象假设指定了混合分量1?‰?c?‰?m,以及Mc,z=(c,P0,.)的每个过滤的位置。。。,PNC)。这里Nc是以Mc为单位的零件数。该假设的分数是假设z?euro™=(P0,.。。,PNC)用于第c个模型组件。
与在单组分模型的情况下一样,混合模型的假设分数可以由模型参数的向量ψ和向量次要的ˆ(H,z)之间的点积来表示。对于混合模型,向量²是每个组件的模型参数向量的串联。向量次ˆ(H,z)是稀疏的,在单个间隔中具有由次ˆ(H,z?™)定义的非零条目,
为了使用混合模型来检测对象,我们使用上面描述的匹配算法来找到为每个组件独立地产生高得分假设的根位置。
潜在支持向量机
由于训练数据集只有对象的标签,而没有对象的部分标签,为了使用部分标签的数据来训练模型,我们使用了MI-SVM的潜在变量公式,我们称之为潜在SVM(LSVM)。在潜在支持向量机中,通过以下形式的函数对每个示例x进行评分,
这里,λ是模型参数的向量,z是潜在值,而φ(x,z)是特征向量。在我们的其中一个星形模型的情况下,Σ是根过滤、零件过滤器和变形成本权重的串联,z是对象配置的规范,而ψ(x,z)是来自特征棱锥体和零件变形特征的子窗口的串联。

在目标检测的情况下,训练问题是高度不平衡的,因为存在比目标多得多的背景。这激发了搜索背景数据以找到相对较少数量的潜在假阳性或硬否定示例的过程。这里我们分析了用于支持向量机和最小二乘支持向量机训练的数据挖掘算法。我们证明了数据挖掘方法可以收敛到根据整个训练集定义的最优模型。
主成分分析与解析降维

我们的对象模型由对特征金字塔的子窗口进行评分的过滤器定义。我们研究了与HOG特征相似的特征集,发现了与原始特征性能相当的低维特征。通过对HOG特征进行主成分分析,可以在没有明显信息损失的情况下显着降低特征向量的维数。此外,通过检查主要特征向量,我们发现了导致低维特征的“EUROœANALIAL”EURO�版本的结构,这些低维特征很容易解释,并且可以有效地计算。
这篇文章没有涉及很多细节,请参考原文。
后期处理:边界框预测

在以前的工作中,直接将从根过滤位置派生的包围盒作为检测结果返回。不过,该模式实际上也本地化了除根过滤之外的各个部分过滤。此外,与根过滤器相比,零件过滤器具有更高的空间精度。因此,使用对象假设z的完整配置来预测对象的边界框是有意义的。
这是使用将特征向量g(Z)映射到边界框的左上角(x1,y1)和右下角(x2,y2)的函数来实现的。对于具有n个部分的模型,g(Z)是一个2n+3维向量,包含以图像像素为单位的过滤根的宽度(这提供了比例信息)和图像中每个过滤的左上角位置。这是通过线性最小二乘回归实现的。
后期处理:非最大抑制
使用上一次会话中描述的匹配过程,我们通常会得到对象的每个实例的多个重叠检测。我们使用贪婪的过程通过非最大值抑制来消除重复检测。
对于图像中的特定对象类别,我们具有一组检测D。每个检测由一个边界框和一个分数定义。我们按照分数对D中的检测进行排序,并贪婪地选择得分最高的检测,同时跳过具有至少50%被先前选择的检测的边界框覆盖的边界框的检测。
后处理:上下文信息
使用上下文信息对检测重新评分的简单过程。设(D1,.。。,dk)是使用图像I中的k个不同模型(针对不同对象类别)获得的一组检测。每个检测(B,s)-ˆˆDi由边界框B=(x1,y1,x2,y2)和分数s定义。我们根据k维向量c(I)=(下ƒ(S1),.。。,Underƒ(SK)),其中si是Di中得分最高的检测的分数,并且Secondƒ(X)=1/(1+EXP(?ˆ‘2x))是用于重新正规化分数的逻辑函数。为了对图像I中的检测(B,S)重新取值,我们构建具有检测的原始分数、左上角和右下角边界框坐标以及图像上下文的25维特征向量,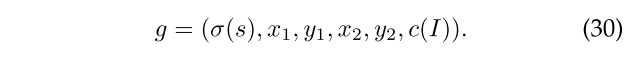
坐标x1,y1,x2,y2?ˆˆ[0,1]根据图像的宽度和高度进行归一化。我们使用特定于类别的分类器对该向量进行评分,以获得检测的新评分。分类器被训练成通过集成由G定义的上下文信息来区分正确的检测和错误的阳性。
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/05/%e2%80%8a-%e2%80%8a%e7%9b%ae%e6%a0%87%e6%a3%80%e6%b5%8b20%e5%b9%b4%e8%ae%ba%e6%96%87%e9%98%85%e8%af%bb%e7%bb%bc%e8%bf%b0%e4%b8%8a/
