
人工智能研究中一个一致的模式是需要大量的训练数据。这给视觉人工智能带来了一个问题,它需要数千张手动标记的图像来学习如何识别和命名不同的图像。但是,有一些方法可以提高数据效率。这里有一个关于三星SDS如何研究和开发一种不同的人工智能模式的故事,这种模式效率要高得多。
确定问题
计算机视觉和视觉分析在各种不同的行业中正变得越来越有价值。观察和识别图像和视频中的对象一直是一项人类推动的工作,需要人们长时间盯着屏幕和图像工作。这是人工智能引擎可以做的例行公事、重复性的工作。事实上,在资产的监视、供应链和诊断领域,可视化人工智能已经在许多情况下成功部署。
剩下的主要问题是数据效率。如果没有人类天生形成的所有心理图式,阅读视觉信息是很复杂的。机器仍然能够读取图像并识别其中的对象。或者,更确切地说,基于学习的数据标记出其中的对象的特征。为了实现这一点,他们需要以图像的形式学习数据,这些图像描述了人工智能意在识别或划定的主题。
这些图像也需要贴上标签。即使人类意识到有问题的斑点是一只“猫”,人工智能也不能简单地将意义或标识附加到抽象的斑点上。必须以某种方式突出显示或标记该猫的特征,并对其进行标识。这就产生了一个新的挑战:标记数据,就像首先分析图像一样,是重复、耗时和昂贵的。
学习方法
这一新的挑战是基于监督学习的。人工智能平台或神经网络需要由人类直接接口来训练它。在计算机视觉的情况下,它采用手动标记图像或视频的形式。对于其他类型的人工智能来说,它是巨大的Excel电子表格,浩瀚的数据海洋,其中大部分都是精心培育的,以确保人工智能处理信息,然后能够在未来处理新的非结构化数据。
当然,这种学习方法非常耗费数据和时间。它对数据的处理效率也很低。训练一个可视化AI平台需要大量的图像,所有这些都要由一名技术人员进行检查和监督。它很昂贵,一开始就超过了使用机器所节省的大部分成本和时间。
但是,如果使用的数据可以更高效,情况会怎样呢?
数据效率
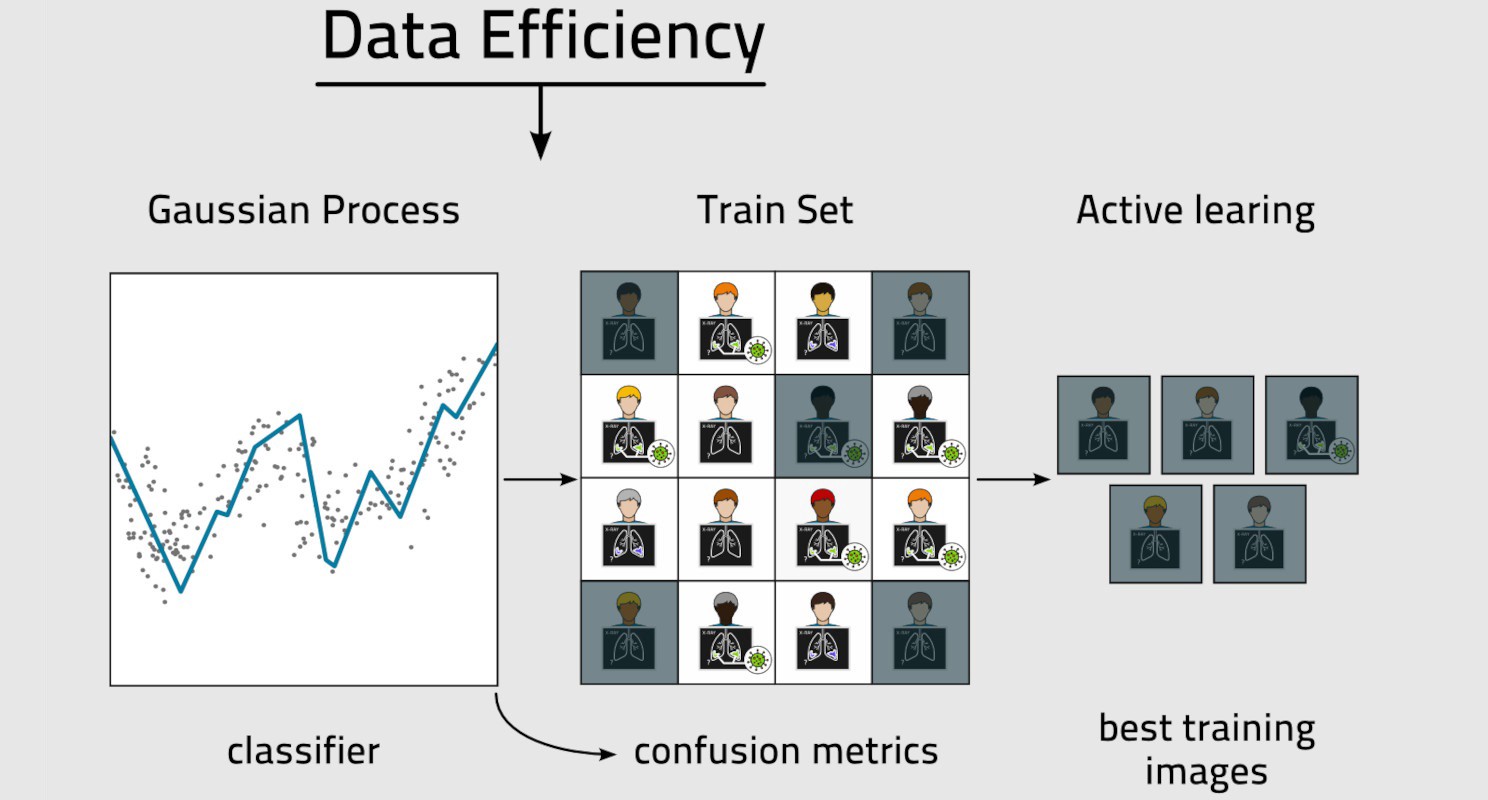
三星SDS通过试验主动学习和高斯过程(GP)分类器,已经确定了一种在视觉人工智能的情况下提高数据效率的方法。此方法侧重于可以从后续数据条目中获取的相关信息。
人工智能被赋予的每一张新图像只能提供极少量的新信息供学习。上面例子中的第一个猫的图像将教给AI大量的信息。猫有毛,它们有四条腿,两只眼睛,胡须等等。下一张图片可能有助于使这种描述多样化,包括不同品种或大小的猫。但随着图像的继续,视觉数据变得越来越迭代,人工智能了解到的关于猫的有用信息将越来越少。但由于大量图像的输入在很大程度上是随机的,而且对所应用的数据没有太大的选择性,所以这种递减的回报没有被考虑在内。毕竟,它们只是猫的形象。
首先,研究人员使用了一组图像(大约14000个样本)。这样做的目的是为人工智能准备好用于预分类的图像正文。然后,从库中随机选取大约140幅图像作为初始活动训练集,其中每幅图像都被正确标注。GP分类器使用这些图像针对14,000个池进行训练。该过程在处理不平衡的图像集方面做得更好,其中每类图像具有很少的表示。训练后的GP评估从训练集获得的新信息以及GP分类器的准确性。然后可以将结果与图像主体进行比较,在那里GP分类器可以显示关于图像主体的相对新颖性和念力。输入分类器的下一组图像将是那些被标记为最“令人困惑”的图像,从而向平台提供最高程度的新信息。然后可以重复这个过程,直到分类器的准确性有很高的确定性。
这一过程的结果是,无需手动标记数千张图像,只使用总数的10%来示教自动标签。通过选择最“混乱”的图像,或者更确切地说,选择信息最丰富的图像来标记和重新输入,加速了人工智能的训练。这最大限度地提高了数据效率,避免了以前的方法所需的大量时间、数据和令人头疼的问题。
下一站是哪里?
就视觉分析而言,该方法的应用是普遍的。培训时间可以大幅缩短,从而实现经济高效、快速入职的平台。这使视觉人工智能的最终用户受益,因为他们可以尽快获得起作用的算法。
学习算法和方法论对人工智能的影响也很有趣。通过进一步的实验,开发半监督学习是可能的,在半监督学习中,平台不仅学习图像中的模式,而且学习模式,以便能够在有限的监督输入之后解释图像。
这种数据效率还允许更复杂的可视人工智能。通过最大限度地提高数据效率,可以使用额外的数据集来教授越来越多的概念。为什么不仅仅是猫,为什么不是狗或羊呢?从时间和数据的角度来看,这为每个平台提供了更大的灵活性和更强的解释力,而培训时间与以前相同。
想看更多的书吗?
PatchNet:基于补丁嵌入的无监督对象发现PatchNet: Unsupervised Object Discovery based on Patch Embedding
非平衡数据的高效表示和主动学习框架及其在冠状病毒X射线分类中的应用Highly Efficient Representation and Active Learning Framework for Imbalanced Data and its Application to COVID-19 X-Ray Classification
字幕:本文由Ryan Cann撰写。Ryan Cann
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/11/%e6%95%b0%e6%8d%ae%e6%95%88%e7%8e%87%ef%bc%9a%e8%a7%a3%e5%86%b3%e8%a7%86%e8%a7%89%e5%88%86%e6%9e%90%e9%97%ae%e9%a2%98-2/
