

利用机器学习和深度学习来解决各种问题已经变得无处不在。这意味着确保模型在目标硬件上执行快速推断而不影响准确性是至关重要的。为机器学习模型提供服务时要考虑的下一项是计算成本。这是一个挑战,可以通过优化推理硬件的利用率来解决。第三个挑战涉及大规模部署生产模型。为此任务配置和设置服务器的过程可能需要数天甚至数周的时间。更重要的是,您需要MLOPS工程师持续监控系统的正常运行时间。这可能很快就会变成一件非常昂贵的事情。幸运的是,DECI平台可以一次解决所有这些问题。在本文中,您将了解如何使用该平台优化您的机器学习模型。我们在示例中使用了YOLOv5,但是该平台允许您优化任何型号。
YOLOv5
YOLOv5是目标检测领域最流行的深度学习模型之一。目标检测的任务包括识别图像中的目标并在其周围绘制边界框。目标检测有各种应用,如自动驾驶汽车、智能机器人和视频监控-仅举几例。
由于我们将在此演示中使用YOLOv5模型,因此让我们花一分钟时间进行简要描述。
YOLOv5是YOLO系列模型的最新成员。YOLO是You Only Look Once的缩写,是一种功能强大的实时目标检测算法,通过对图像进行训练来优化检测性能。根据该模型的GitHub页面,该模型比之前的YOLO版本更快。该页面还提供了预先培训的模型,您可以立即下载并开始使用。模型也可以从头开始训练。但是,具有最小图像大小的最小型号将花费您48小时的4个V100 GPU(更大的图像或更大的型号会更长)。这就是说,试验这种架构并不便宜。YOLOv5 GitHub page
了解了有关YOLOv5的基本信息后,让我们开始使用DECI平台优化模型。
如何在DECI上对模型进行优化
我们的第一步是获得我们想要优化的训练模型的相关检查点。在我们的案例中,我们使用的是YOLOv5,它在COCO数据集上接受过培训,采用的是ONNX格式,这是一种旨在实现机器学习互操作性的开放格式。DECI平台还支持其他模型格式,如Kera、TensorFlow或PyTorch。我们的目标是T4图形处理器,它性价比很高。T4是英伟达研发的深度学习加速器。COCO dataset
另一个非常酷的功能是Deci的Model Hub。这是一个训练有素的模型库,随时可以进行优化。您只需将它们克隆到您的实验室(您的个人模型存储库)。Model Hub已经有各种各样的型号,而且还在与日俱增。YOLOv5很快也将在那里推出。所以,敬请关注。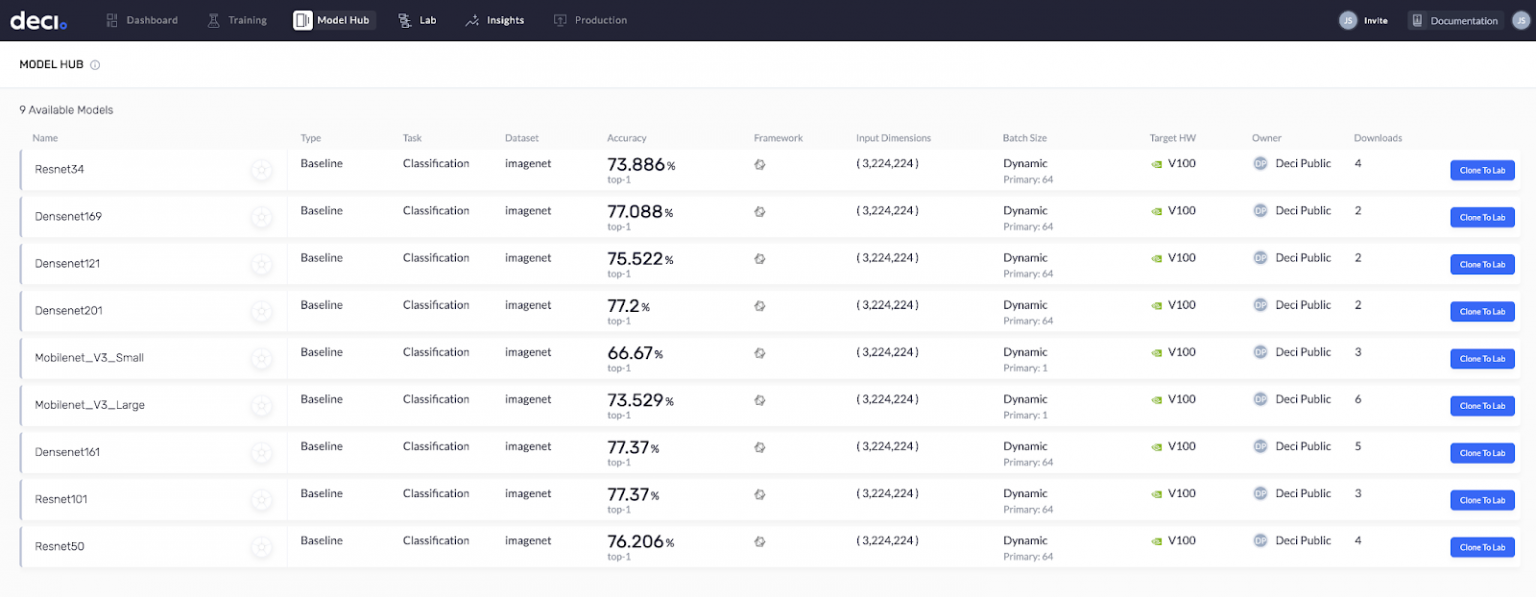
第1步:使用DECI创建帐户
下一步是在Deci.ai创建一个免费帐户。单击注册按钮开始。Deci.ai
DECI将向您发送一封电子邮件,说明如何验证您的帐户。一旦您验证了您的帐户,您将看到Deci的实验室屏幕。这里是所有魔术发生的地方。DECI还提供针对CPU和GPU预先优化的示例ResNet-50、ImageNet型号。你可以马上用它来感受一下站台。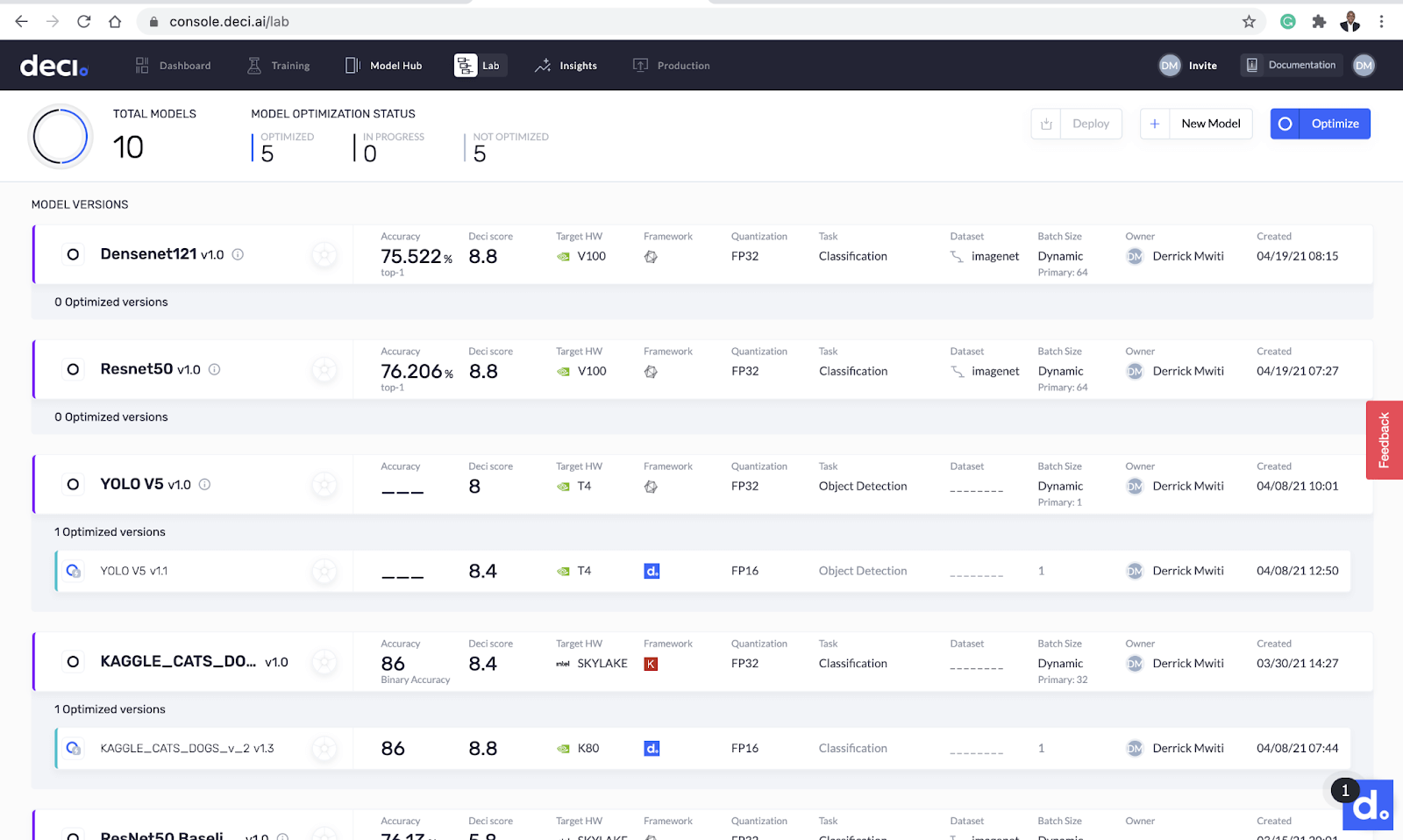
步骤2:上传模型
单击New Model(新建模型)按钮上载模型。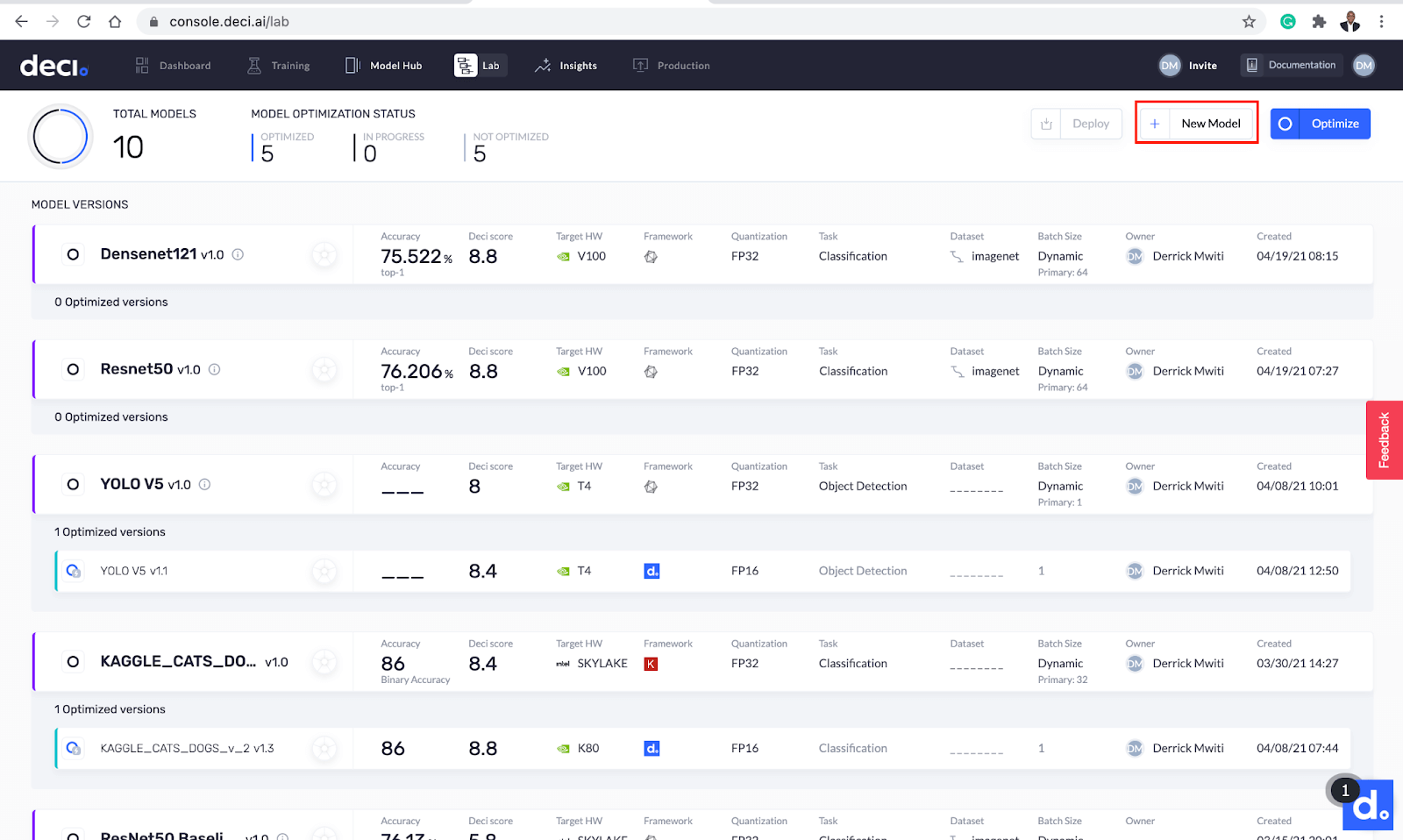
下一个弹出窗口为您提供上传模型并添加其详细信息的选项。您需要在此页面上提供几项内容:
- 型号名称
- 可选型号说明
- 任务类型
- 推断批量大小

让我们填一下这个信息。正如您从上面的屏幕截图中看到的,您需要知道模型所需的输入尺寸。弄清楚这一点的一个快速方法是将模型上传到Netron。单击输入节点将显示输入尺寸。该型号的输入尺寸为3x320x320。Netron
有了这些信息,回到Deci的实验室屏幕并填写它。DECI也可以让你输入模型的准确性,但不会进行验证。因为我们没有链接任何数据集,所以现在可以将其留空。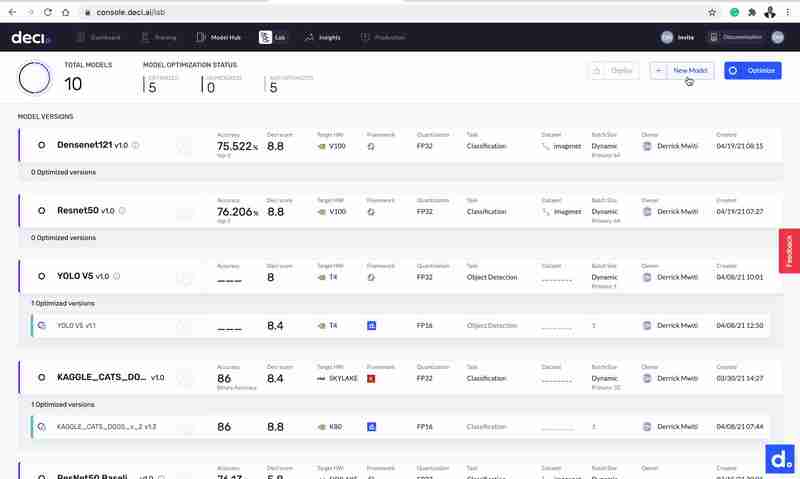
DECI现在将上传模型并自动执行一些基准测试。此过程大约需要2分钟才能完成。一旦该过程完成,您将在DECI实验室屏幕上看到结果。
步骤3:检查DECI模型洞察力
DECI分数是显示在DECI实验室屏幕上的度量之一。这是一个介于0和10之间的数字,它告诉您目标硬件上模型在运行时的效率。它显示了您的模型在具有指定硬件和批处理大小的生产环境中的效率。
您还可以通过单击刚刚下载的模型旁边的Insights按钮来查看更多信息。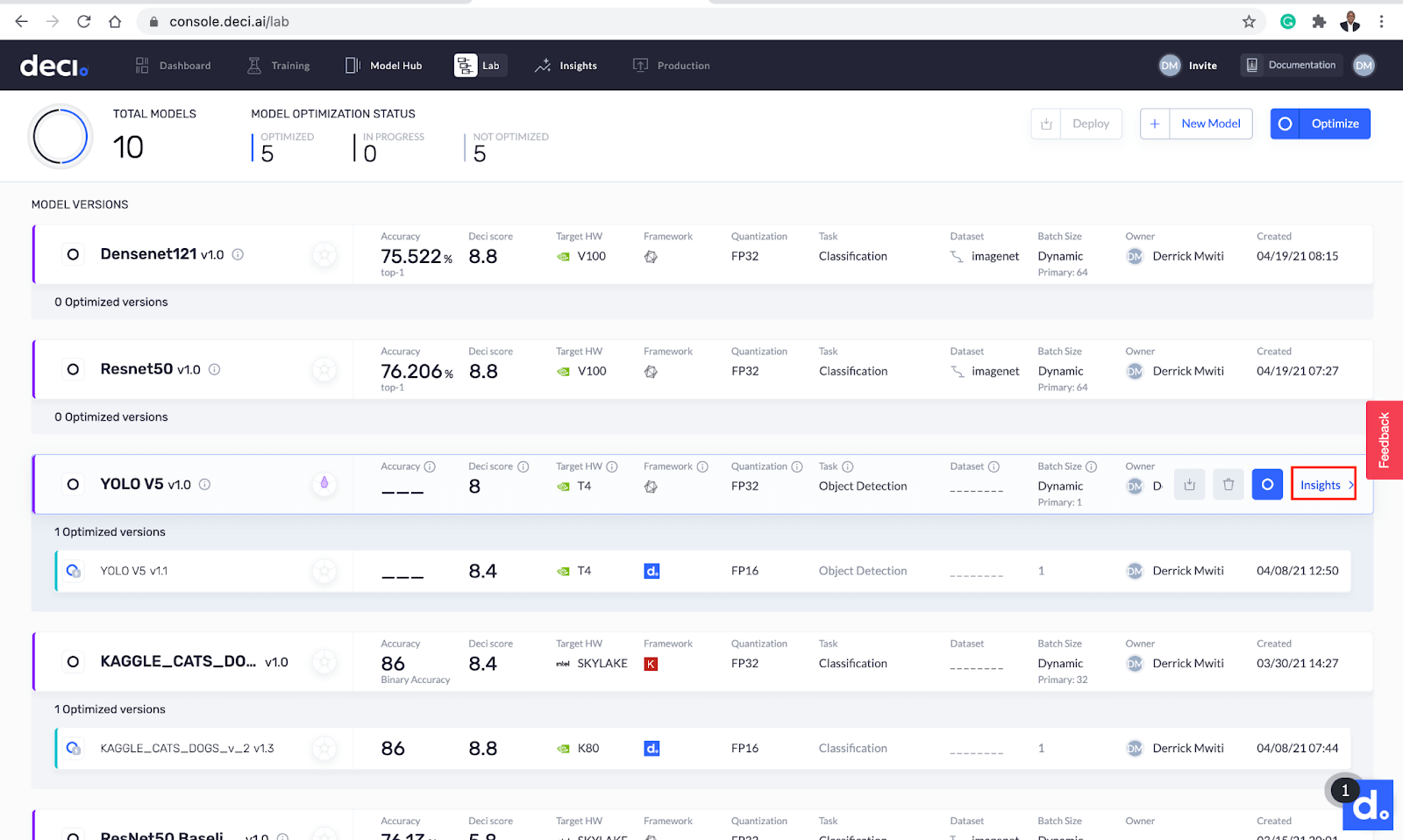
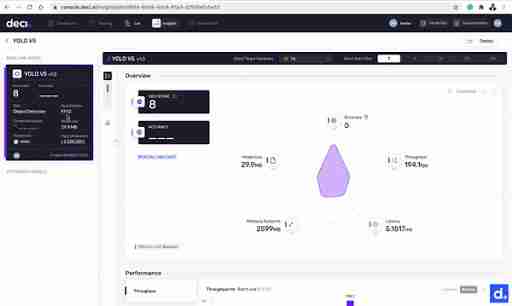
让我们仔细看看。您将在此页面上看到几个指标:
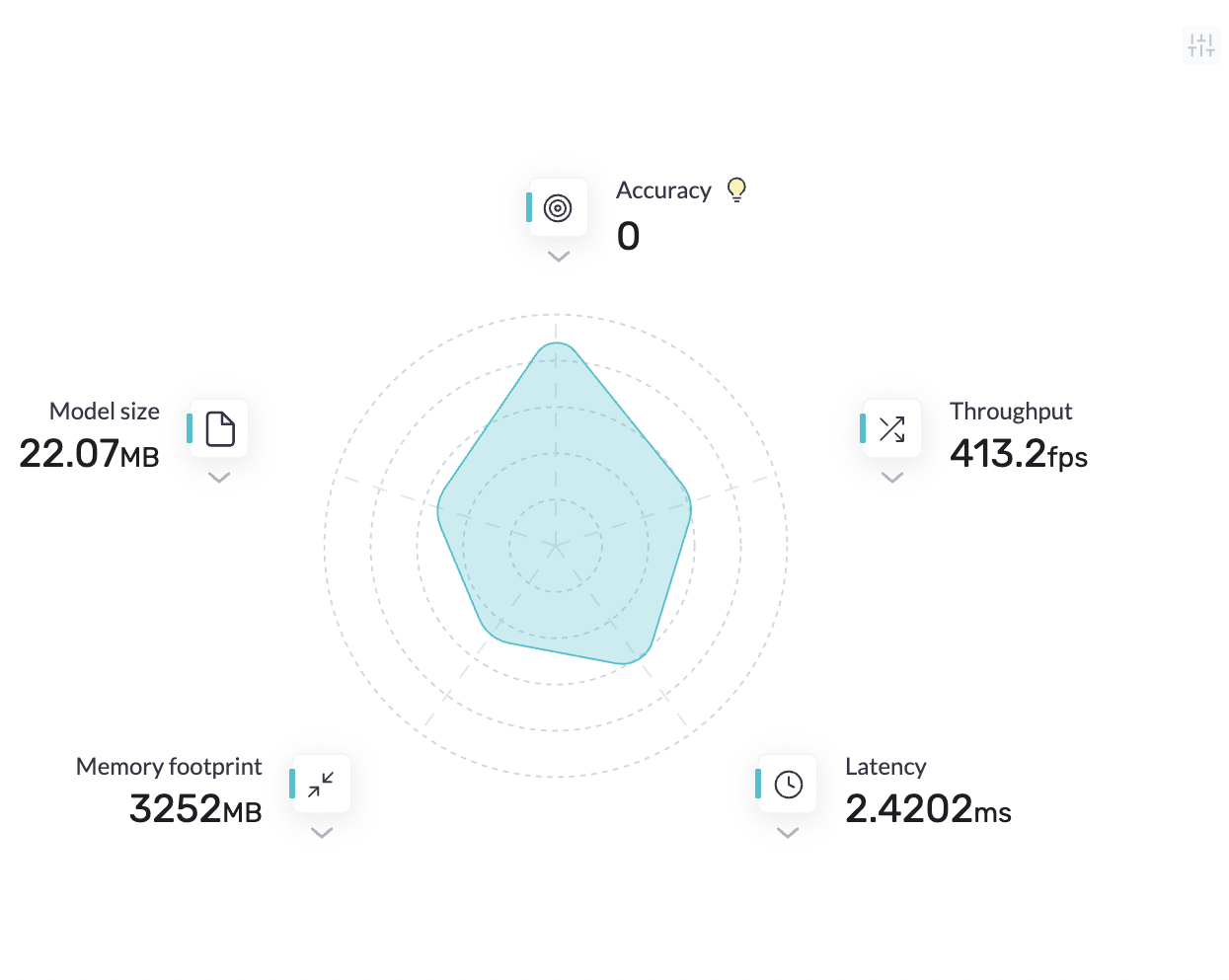
- 吞吐量:模型在特定时间范围内处理的请求数。
- 延迟:模型在生产服务器上执行推理时的延迟。
- 模型大小:模型在物理存储中占用的空间
- 内存占用:模型在推理过程中使用的内存。
步骤4:优化模型
下一步是利用该平台对模型进行优化。然后,我们将优化模型的结果与初始模型进行比较。您可以通过单击模型旁边的优化按钮来启动模型优化。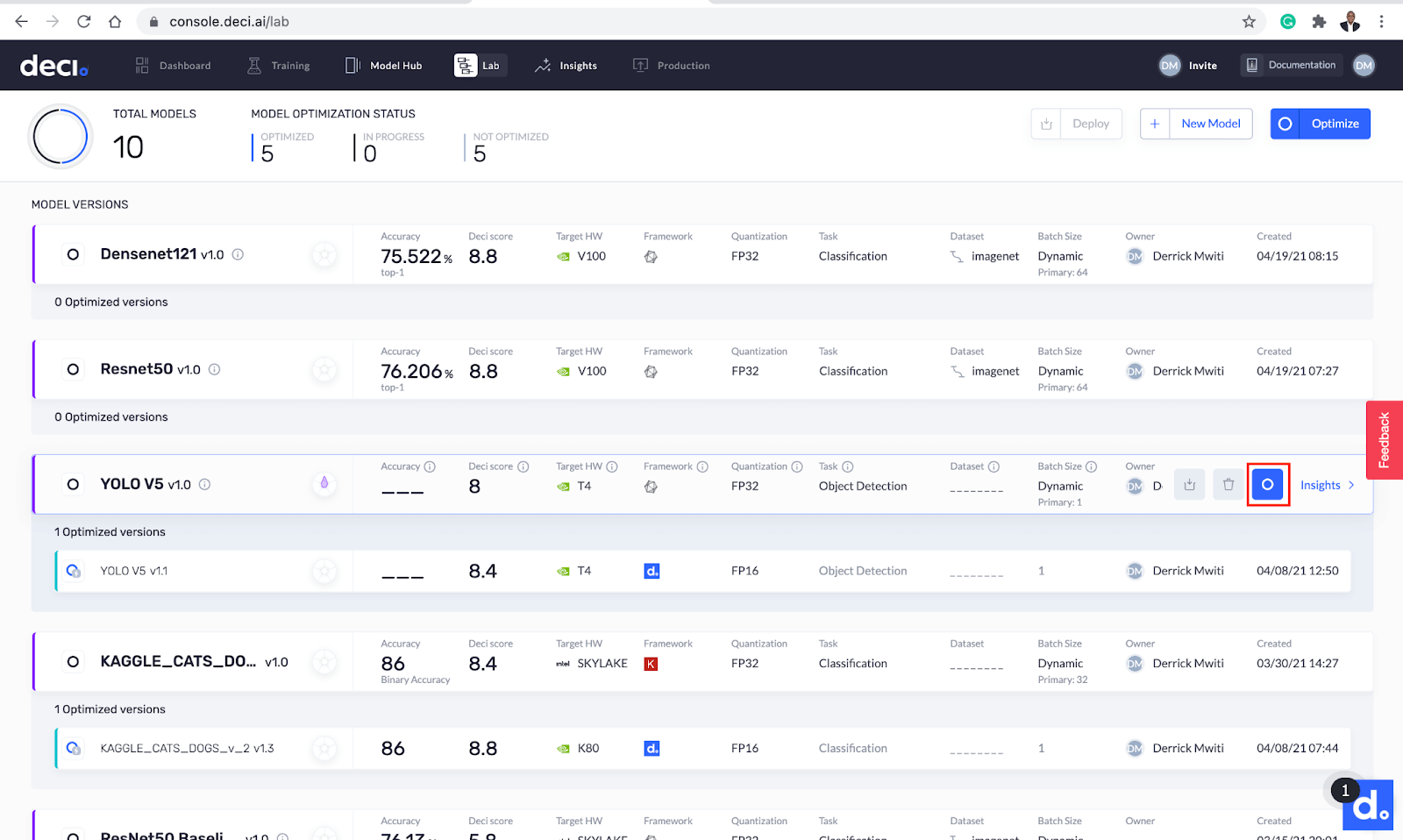
下一个屏幕允许您配置模型的优化。您可以选择针对CPU、GPU或移动设备优化模型。让我们通过选择T4 GPU来做到这一点。您还可以选择要优化的批次大小。在本例中,我们使用批大小1。
在同一屏幕上,您将看到AutoNAC优化,这是一项提供更高级别优化的付费功能。针对移动性和较低量化级别的优化也是PRO特性。AutoNAC optimization
在我们进行此演示时,牢记我们的优化目标是很重要的。这些目标是获得一个低推理量和高吞吐量的模型。为此,我们通过16位量化对模型进行了优化。在量化过程中,数字的存储精度较低,因此占用的内存较少。这意味着可以用更便宜的操作取代昂贵的操作,从而减少模型的推理时间。
您现在应该会看到优化过程进度条。坐好等着德奇的巫师表演他们的魔术吧!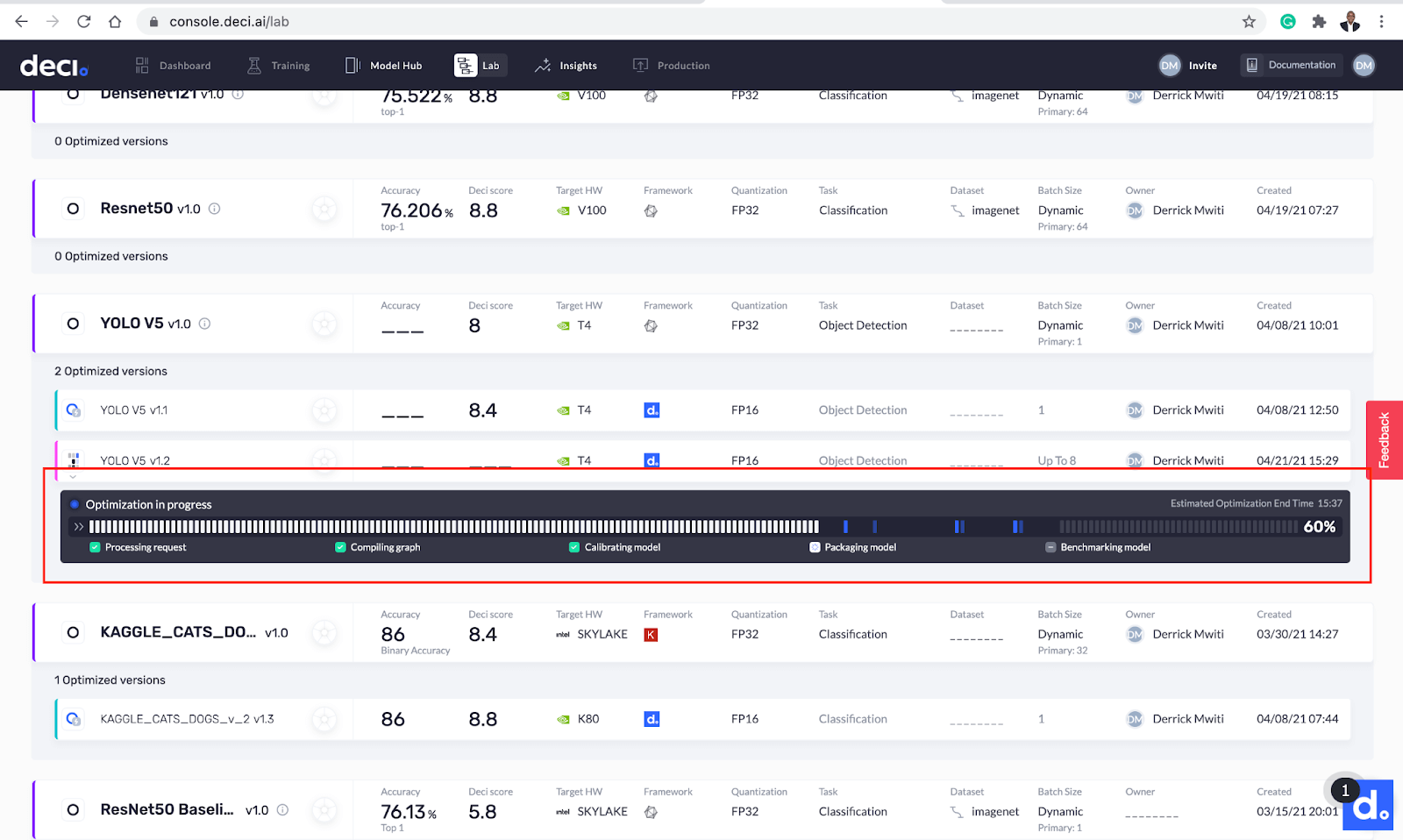
优化大约在11分钟内完成。之后,新的优化模型将显示在基础模型的下方。您很快就可以看到优化后的DECI分数增加了。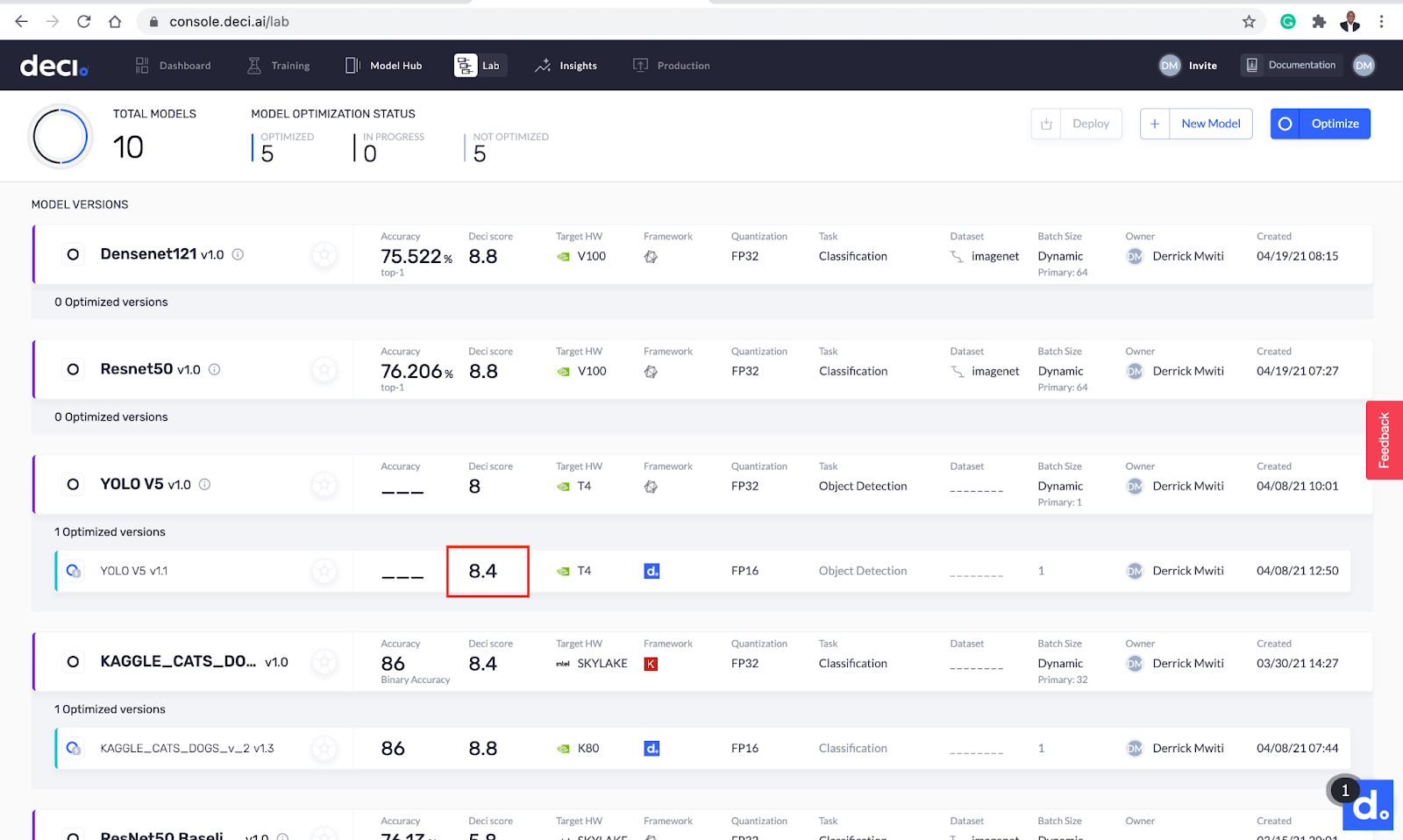
比较最终结果
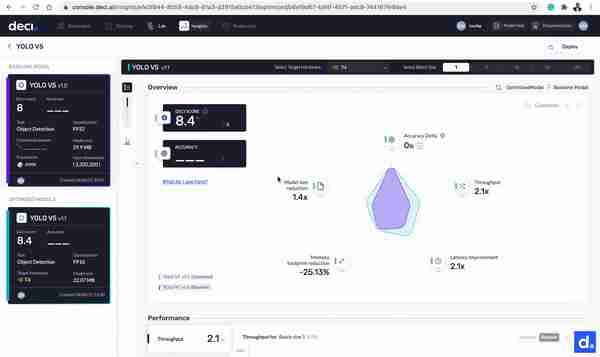
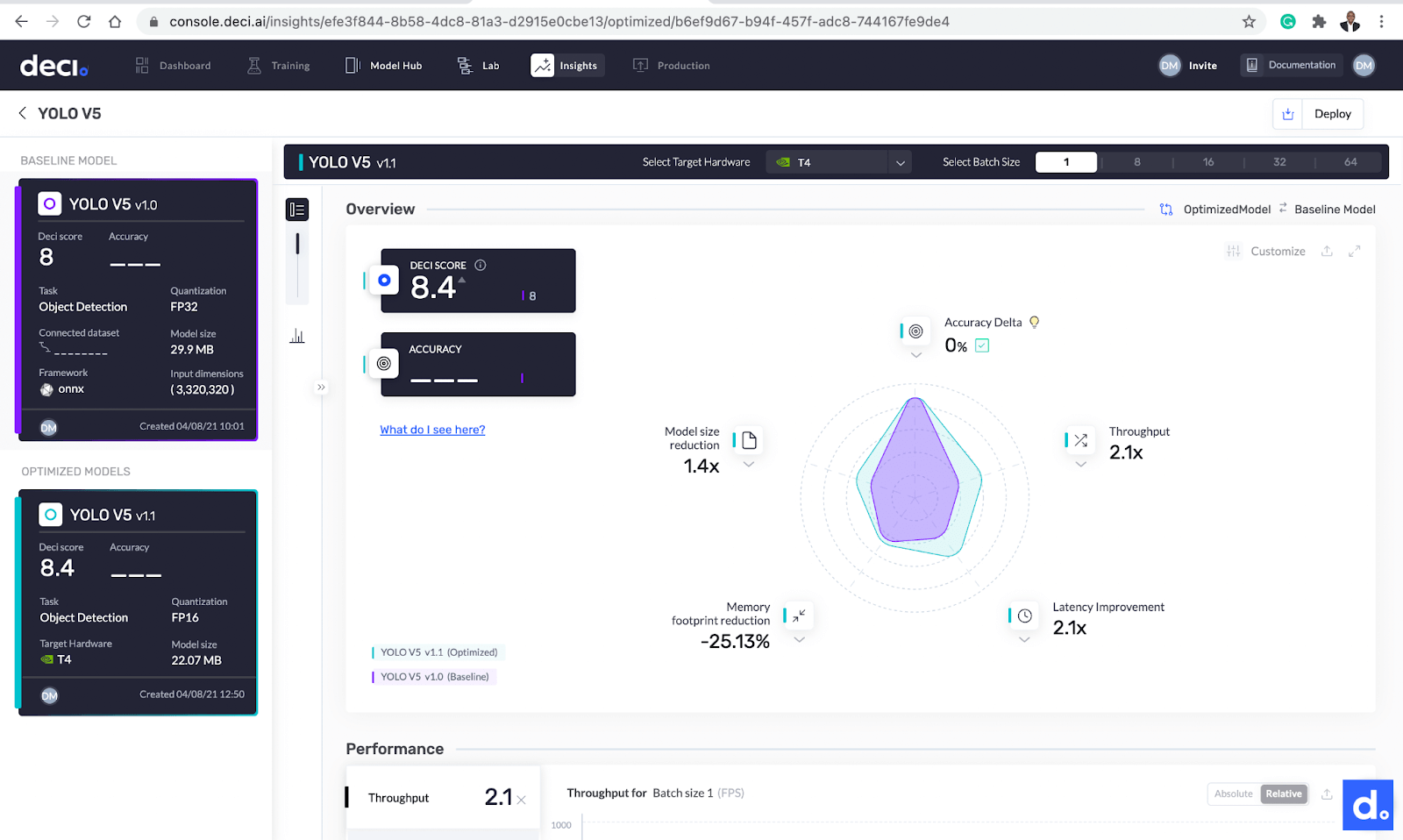
优化完成后,现在是比较基础模型和优化模型的时候了。单击任一型号旁边的洞察力按钮即可开始使用。让我们来看看其中的不同之处:
- 该型号的吞吐量从194.1 FPS提高到413.2 FPS。该模型现在的速度是现在的2.1倍。
- 该模型的大小从29.9MB减小到22.07MB。
- 该模型的延迟从5.1517毫秒提高到2.4202毫秒,提高了2.1倍。
结论
正如您刚才看到的,您可以在15分钟内将YOLOv5型号的性能提高一倍。您还可以看到,DECI平台使用起来超级简单和直观。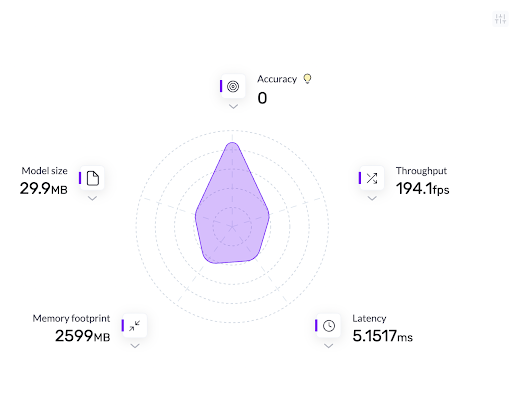
这是一张比较模型前后延迟的图表。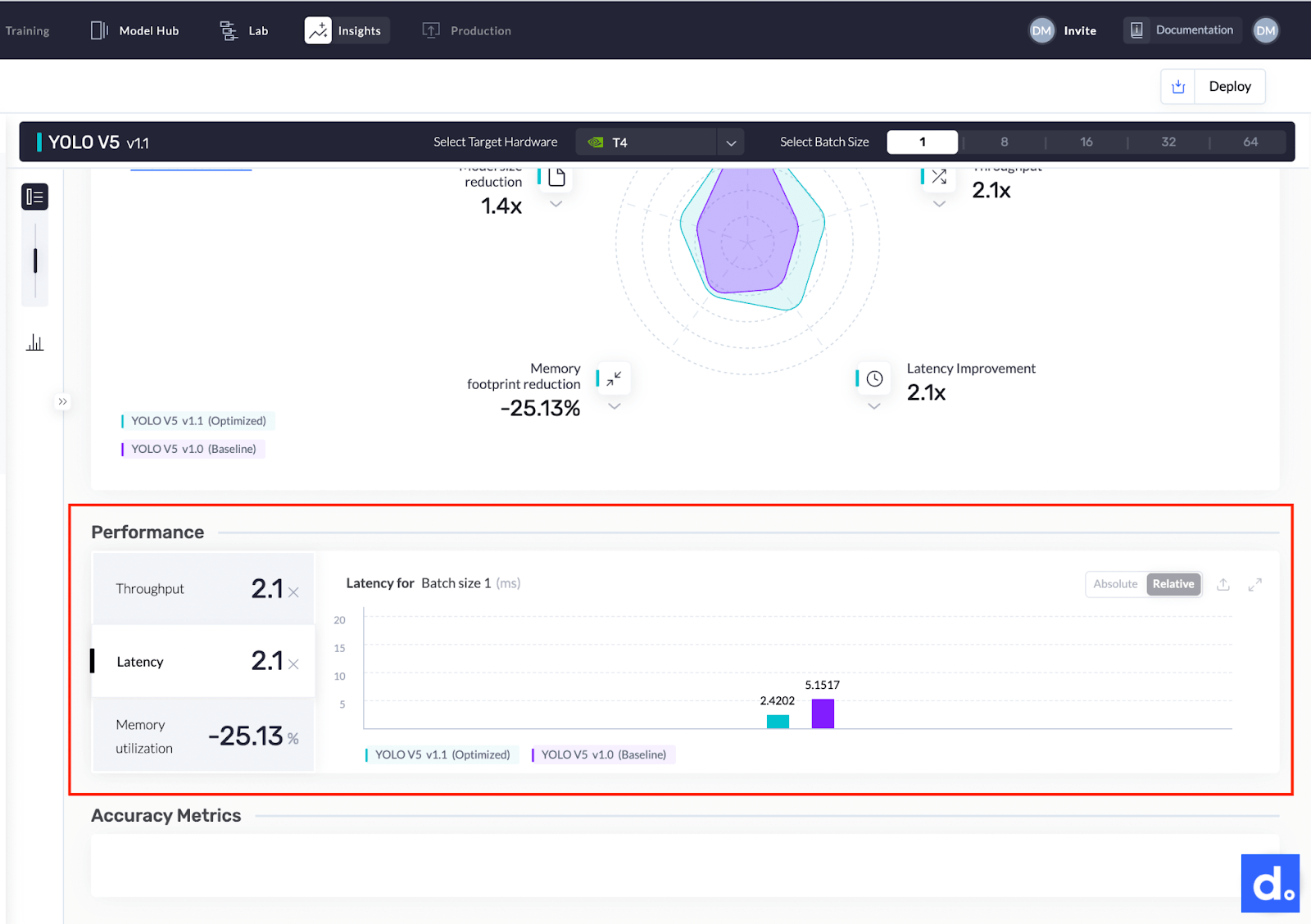
下图显示了两个YOLO型号的吞吐量比较。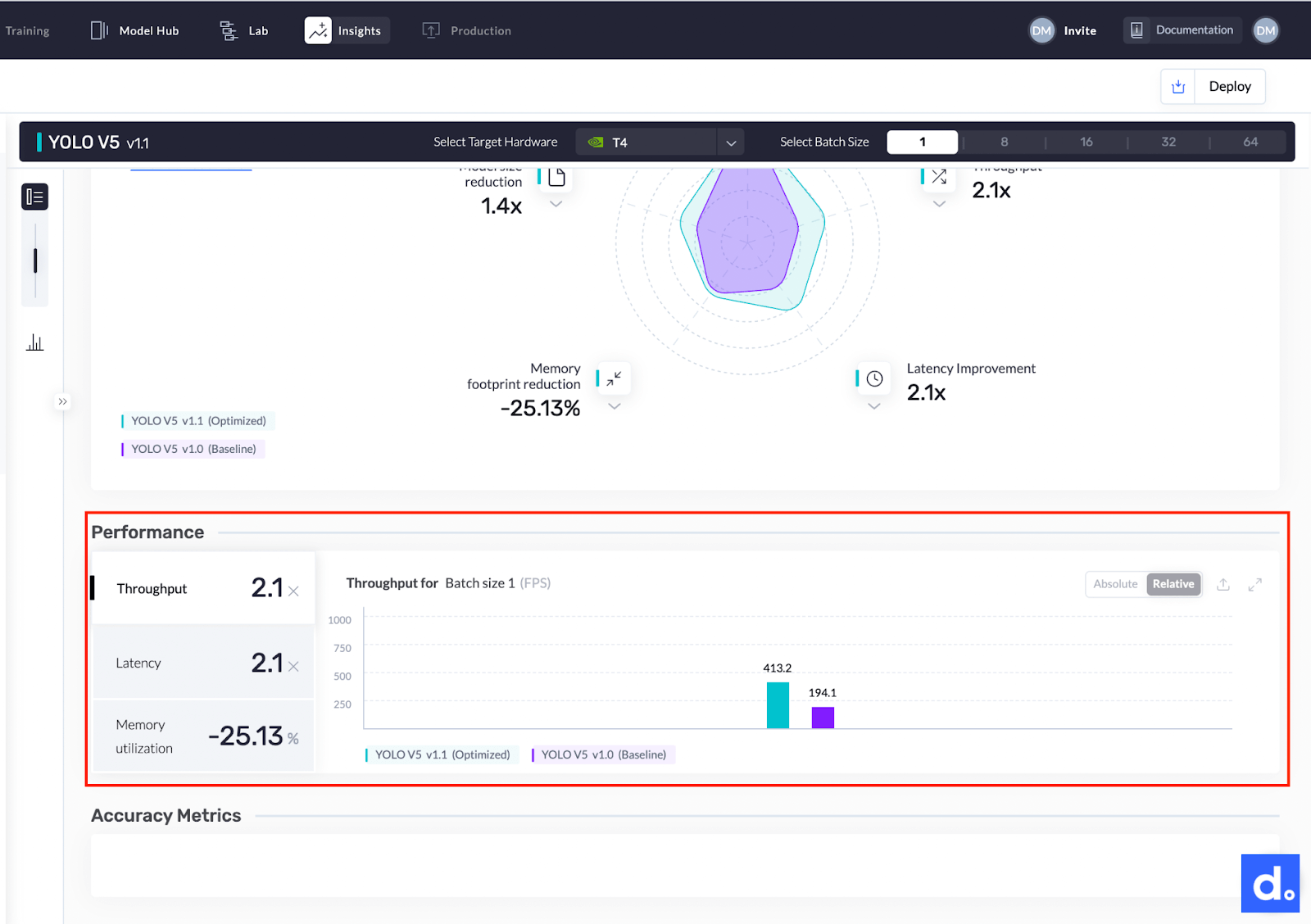
在结束之前,让我们讨论一下DECI提供的一些优势:
- 在不影响准确性的情况下优化模型的推理吞吐量和延迟
- 允许您从所有流行的框架中优化模型
- 支持针对任何深度学习任务的模型
- 支持在流行的CPU和GPU计算机上部署
点击此处注册DECI深度学习加速平台。here
这篇文章最早是在这里发表的。here
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/19/%e5%a6%82%e4%bd%95%e5%9c%a815%e5%88%86%e9%92%9f%e5%86%85%e5%b0%86yolov5%e5%9e%8b%e5%8f%b7%e7%9a%84%e5%90%9e%e5%90%90%e9%87%8f%e5%92%8c%e5%bb%b6%e8%bf%9f%e6%8f%90%e9%ab%982%e5%80%8d-2/
