
作者|LAKSHAY ARORA
编译|Flin
来源|analyticsvidhya
介绍
随着互联网的普及,我们现在正以前所未有的速度生成数据。因为执行任何类型的分析都需要我们从数据库中收集/查询必要的数据,所以选择正确的工具来查询数据变得至关重要。因此,我们无法想象使用SQL来处理如此大量的数据,因为每个查询的成本都很高。
这正是MongoDB的用武之地。MongoDB是一个非结构化数据库,以文档形式存储数据。此外,MongoDB能够非常高效地处理大量数据,并且是使用最广泛的NoSQL数据库,因为它提供了丰富的查询语言以及对数据的灵活而快速的访问。
在本文中,我们将看到有关如何使用PyMongo查询MongoDB数据库的多个示例。此外,我们将看到如何使用比较运算符和逻辑运算符,正则表达式以及聚合管道的基础知识。
本文是MongoDB初学者教程(https://www.analyticsvidhya.com/blog/2020/02/mongodb-in-python-tutorial-for-beginners-using-pymongo) 的延续,其中我们讨论了非结构化数据库,安装步骤和MongoDB基本操作的挑战。因此,如果你是MongoDB的初学者,我建议你先阅读该文章。
目录
- 什么是PyMongo?
- 安装步骤
- 将数据插入数据库
-
查询数据库
- 根据字段过滤
- 根据比较运算符进行过滤
- 基于逻辑运算符的过滤
- 常用表达
- 聚合管道
- 尾注
什么是PyMongo?
PyMongo是一个Python库,使我们能够与MongoDB连接。此外,这是MongoDB和Python一起使用的最推荐的方法。
另外,我们选择Python与MongoDB进行交互,因为它是数据科学中最常用且功能最强大的语言之一。PyMongo允许我们使用类似于字典的语法来检索数据。
如果你是Python的初学者,我建议你参加此免费课程:Python入门。
安装步骤
安装PyMongo非常简单明了。在这里,我假设你已经安装了Python 3和MongoDB。以下命令将帮助你安装PyMongo:
pip3 install pymongo将数据插入数据库
现在让我们进行设置,然后再使用PyMongo查询MongoDB数据库。首先,我们将数据插入数据库。以下步骤将为你提供帮助
- 导入库并连接到mongo客户端
在计算机上启动MongoDB服务器。我假设它正在localhost:27017运行文件。
让我们开始导入一些我们将要使用的库。默认情况下,MongoDB服务器在本地计算机上的端口27017上运行。然后,我们将使用pymongo库连接到MongoDB客户端。
然后获取数据库sample_db的数据库实例。万一它不存在,MongoDB将为你创建一个。
# 导入所需的库
import pymongo
import pprint
import json
import warnings
warnings.filterwarnings('ignore')
# 连接到mongoclient
client = pymongo.MongoClient('mongodb://localhost:27017')
# 获取数据库
database = client['sample_db']- 从JSON文件创建集合
我们将使用在多个城市运营的一家送餐公司的数据。此外,他们在这些城市设有各种配送中心,用于向其顾客发送餐单。你可以在此处下载数据和代码。
-
weekly_demand:
- id:每个文档的唯一ID
- week:周号
- center_id:配送中心的唯一ID
- meal_id:餐的唯一ID
- checkout_price:最终价格,包括折扣,税金和送货费
- base_price:餐的基本价格
- emailer_for_promotion:发送电子邮件以促进进餐
- homepage_featured:首页提供的餐点
- num_orders:(目标)订单数
-
meal_info:
- meal_id:餐的唯一ID
- category:餐食类型(饮料/小吃/汤……)
- cuisine:美食(印度/意大利/…)
然后,我们将在sample_db数据库中创建两个集合:
# 创建每周需求收集
database.create_collection("weekly_demand")
# 创建餐食信息
database.create_collection("meal_info")

- 将数据插入集合
现在,我们拥有的数据为JSON格式。然后,我们将获得集合的实例,读取数据文件,并使用insert_many函数插入数据。
# 获取collection weekly_demand
weekly_demand_collection = database.get_collection("weekly_demand")
# 打开weekly_demand json文件
with open("weekly_demand.json") as f:
file_data = json.load(f)
# 将数据插入集合
weekly_demand_collection.insert_many(file_data)
# 获取总数据点数
weekly_demand_collection.find().count()
# >> 456548
# 获取收藏餐
meal_info_collection = database.get_collection("meal_info")
# 打开meat_info json文件
with open("meal_info.json") as f:
file_data = json.load(f)
# 将数据插入集合
meal_info_collection.insert_many(file_data)
# 获取总数据点数
meal_info_collection.find().count()
# >> 51最后,在weekly_demand_collection中有456548个文档,在餐信息集合中有51个文档。现在,让我们看一下每个集合中的一个文档。
weekly_demand_collection
weekly_demand_collection.find_one()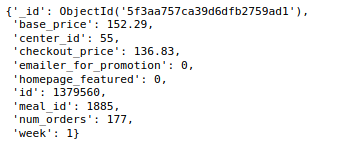
膳食信息集
meal_info_collection.find_one()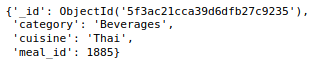
现在,我们的数据已准备就绪。让我们继续查询该数据库。
查询数据库
我们可以使用带有查找功能的PyMonfo查询MongoDB数据库,以获取满足给定条件的所有结果,还可以使用find_one函数,该函数将仅返回满足条件的一个结果。
以下是find和find_one的语法:
your_collection.find( {<< query >>} , { << fields>>} )你可以使用以下过滤技术查询数据库
- 根据字段过滤
例如,你有数百个字段,而你只想看到其中的几个。你可以通过将所有必填字段名称都设置为值1来实现此目的。例如,
weekly_demand_collection.find_one( {}, { "week": 1, "checkout_price" : 1})
另一方面,如果只想从整个文档中丢弃一些字段,则可以将字段名称设置为等于0。因此,将仅排除那些字段。请注意,你不能使用1和0的组合来获取字段。要么全部为一,要么全部为零。
weekly_demand_collection.find_one( {}, {"num_orders" : 0, "meal_id" : 0})
- 过滤条件
现在,在本节中,我们将在第一个大括号中提供一个条件,并在第二个中删除该字段。因此,它将返回center_id等于55且meal_id等于1885的第一个文档,并且还将丢弃字段_id和week。
weekly_demand_collection.find_one( {"center_id" : 55, "meal_id" : 1885}, {"_id" : 0, "week" : 0} )
- 根据比较运算符进行过滤
以下是MongoDB中的9个比较运算符。
| 名称 | 描述 |
| $eq | 它将匹配等于指定值的值。 |
| $gt | 它将匹配大于指定值的值。 |
| $gte | 它将匹配所有大于或等于指定值的值 |
| $in | 它将匹配数组中指定的任何值 |
| $lt | 它将匹配所有小于指定值的值 |
| $lte | 它将匹配所有小于或等于指定值的值 |
| $ne | 它将匹配所有不等于指定值的值 |
| $nin | 它将不匹配数组中指定的任何值 |
以下是使用这些比较运算符的一些示例
- 等于和不等于
我们将找到center_id等于55且homepage_featured不等于0的所有文档。由于我们将使用find函数,因此它将返回该命令的游标。此外,使用for循环遍历查询结果。
result_1 = weekly_demand_collection.find({
"center_id" : { "$eq" : 55},
"homepage_featured" : { "$ne" : 0}
})
for i in result_1:
print(i)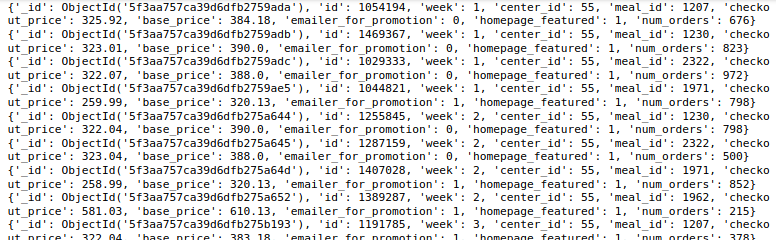
- 在列表中和不在列表中
例如,你需要将一个元素与多个元素匹配。在这种情况下,我们可以使用$ in 运算符,而不是多次使用 $eq运算符。我们将尝试找出center_id为24或11的所有文档。
result_2 = weekly_demand_collection.find({
"center_id" : { "$in" : [ 24, 11] }
})
for i in result_2:
print(i)
然后,我们找到所有在指定列表中不存在center_id的文档。以下查询将返回center_id不是24也不是11的所有文档。
result_3 = weekly_demand_collection.find({
"center_id" : { "$nin" : [ 24, 11] }
})
for i in result_3:
print(i)
- 小于和大于
现在,让我们查找center_id为55并且checkout_price大于100且小于200的所有文档。为此,请使用以下语法
result_4 = weekly_demand_collection.find({
"center_id" : 55,
"checkout_price" : { "$lt" : 200, "$gt" : 100}
})
for i in result_4:
print(i)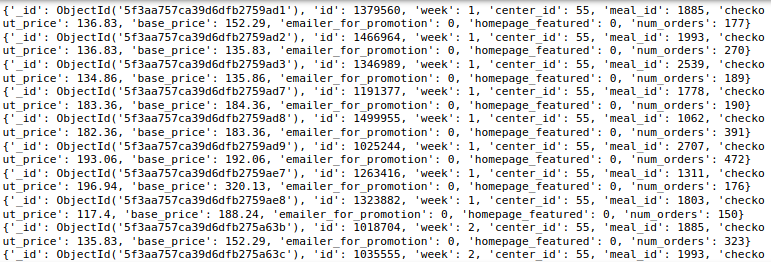
- 基于逻辑运算符的过滤器
| 名称 | 描述 |
| $and | 它将查询语句与逻辑连接起来,AND返回同时符合这两个条件的所有文档。 |
| $not | 它将反转查询的结果,并返回与查询表达式不匹配的文档。 |
| $nor | 它将使用逻辑将查询子句连接起来,NOR返回所有与子句不匹配的文档。 |
| $or | 它将使用逻辑将查询子句连接起来,OR返回匹配任一子句条件的所有文档。 |
以下示例说明了逻辑运算符的用法-
- AND运算符
下面的查询将返回center_id等于11,餐号不等于1778的文档。AND运算符的子查询将出现在列表中。
result_5 = weekly_demand_collection.find({
"$and" : [{
"center_id" : { "$eq" : 11}
},
{
"meal_id" : { "$ne" : 1778}
}]
})
for i in result_5:
print(i)
- 或运算符
以下查询将返回center_id等于11或餐ID为1207或2707的所有文档。此外,or运算符的子查询将位于列表内。
result_6 = weekly_demand_collection.find({
"$or" : [{
"center_id" : { "$eq" : 11}
},
{
"meal_id" : { "$in" : [1207, 2707]}
}]
})
for i in result_6:
print(i)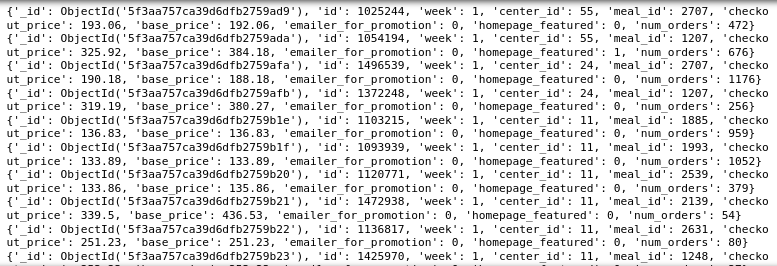
- 用正则表达式过滤
当你有文本字段并且要搜索具有特定模式的文档时,正则表达式非常有用。如果你想了解有关正则表达式的更多信息,我强烈建议你阅读本文:Python正则表达式初学者教程。
它可以与运算符 $regex 一起使用,并且我们可以为运算符提供值,使regex模式变为matc。我们将在该查询中使用餐信息集,然后找到在美食字段中以C开头的文档。
result_7 = meal_info_collection.find({
"cuisine" : { "$regex" : "^C" }
})
for i in result_7:
print(i)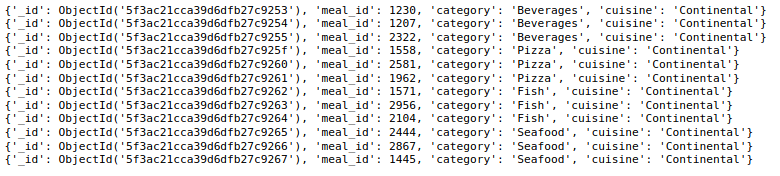
让我们再来看一个正则表达式的例子。我们将查找所有类别以“ S”开头且以“ ian ” 结尾的所有文档。
result_8 = meal_info_collection.find({
"$and" : [
{
"category" : {
"$regex" : "^S"
}},
{
"cuisine" : {
"$regex" : "ian$"
}}
]
})
for i in result_8:
print(i)
- 聚合管道
MongoDB的聚合管道提供了一个框架,可以对数据集执行一系列数据转换。以下是其语法:
your_collection.aggregate( [ { <stage1> }, { <stage2> },.. ] )第一个阶段将完整的文档集作为输入,然后每个随后的阶段都将上一个转换的结果集作为下一个阶段的输入并产生输出。
MongoDB汇总中大约有10种转换可用,在本文中我们将看到$ match和$ group。我们将在即将发表的MongoDB文章中详细讨论每个转换。
例如,在第一阶段,我们将匹配center_id等于11的文档,在下一阶段,它将对center_id等于11的文档数量进行计数。请注意,我们已经为$count运算符分配了一个值,该值等于第二阶段中的total_rows,这是我们希望在输出中显示的字段的名称。
result_9 = weekly_demand_collection.aggregate([
## stage 1
{
"$match" :
{"center_id" : {"$eq" : 11 } }
},
## stage 2
{
"$count" : "total_rows"
}
])
for i in result_9:
print(i)
现在,让我们再举一个例子,第一个阶段与之前相同,即center_id等于11,在第二个阶段中,我们要计算center_id 11的字段num_orders的平均值和center_id 11的唯一meal_ids。
result_10 = weekly_demand_collection.aggregate([
## stage 1
{
"$match" :
{"center_id" : {"$eq" : 11 } }
},
## stage 2
{
"$group" : { "_id" : 0 ,
"average_num_orders": { "$avg" : "$num_orders"},
"unique_meal_id" : {"$addToSet" : "$meal_id"}}
}
])
for i in result_10:
print(i)
尾注
如今, 数据量之大令人难以置信,因此有必要找到更好的替代方法来查询数据。总而言之,在本文中,我们学习了如何使用PyMongo查询MongoDB数据库。此外,我们了解了如何根据所需情况应用各种过滤器。
如果你想了解有关查询数据的更多信息,我建议你学习以下课程 —— 数据科学的结构化查询语言(SQL)
在接下来的文章中,我们将详细讨论聚合管道。
感谢阅读!
原文链接:https://www.analyticsvidhya.com/blog/2020/08/query-a-mongodb-database-using-pymongo/
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/10/19/%e4%bd%bf%e7%94%a8pymongo%e6%9f%a5%e8%af%a2c%e6%95%b0%e6%8d%ae%e5%ba%93%ef%bc%81/
