
引言
- 最近針對StyleGAN2做Transfer Learning還是很熱門,主要是因為他的架構是從低分辨率到高分辨率進行訓練,簡單的微调就可以讓源域轉移到目标域,不需要整個重新訓練。
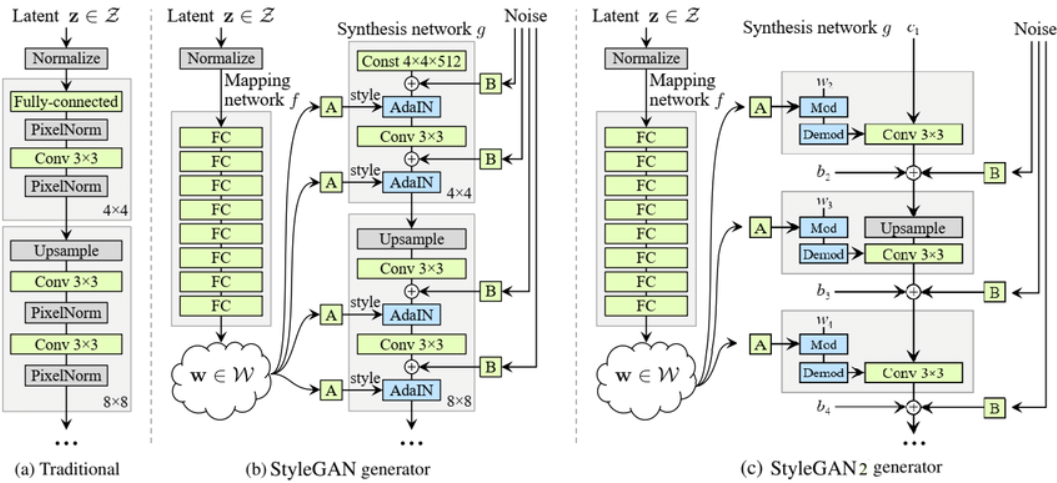
- 下圖為StyleGan的架構,有別於一般GaN直接從随机的z開始訓練GaN,而是先透過映射网络訓練分布,再透過PGGAN的概念訓練GaN,因此在其架構中,低分辨率的层會掌控圖像的整體輪廓,而高分辨率的部分則是掌控圖像的細節部分。
- 层交换(LS)表示從兩個不同域的分布丟給GaN模型,所以如果基於StyleGAN做LS的話哪個域放在低分辨率就會由那個域掌握輪廓,高分辨率同理。
方法
- 此篇提出兩個想法如下,FreezeSG固定住w(样式向量)和g(生成器)的初始块(4×4-8×8),结构损耗在不同解析度的输出地方加上源對目标的mse损耗。
- 下圖為Structure Lost的架構和公式,用在三個低分辨率图层。
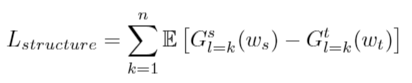
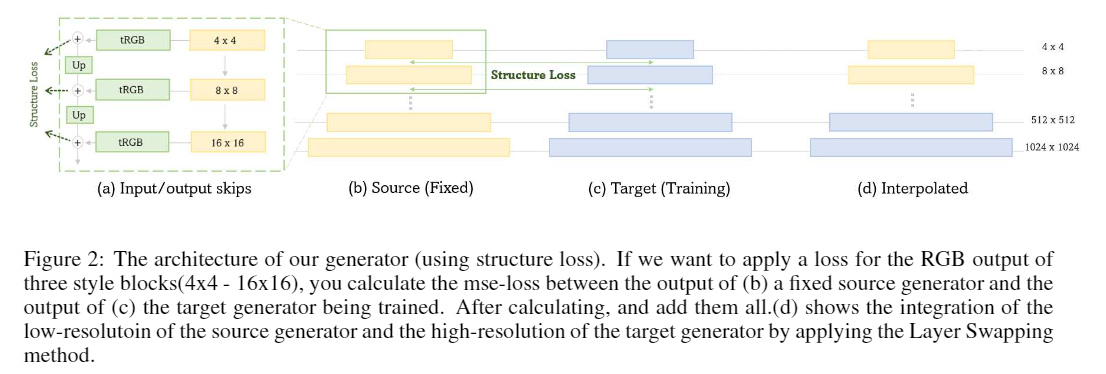
- 整體的损耗、L_adv就一般的GaN损耗、λ_Structure設為1。
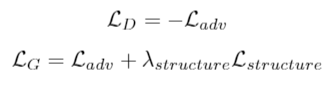
- 結果如下圖1、作者認為FreezeSG比單獨的FreezeG還好、LS的部分源生成器低分辨率层(4×4-64×64)和目标生成器高分辨率层(64×64-256×256)。

- 下巴的部分有明顯的差異.

实验
源域数据集:flickr-faces-hq(FFHQ)
目标领域数据集:Naver Webtoon、Metfaces、迪士尼


消融研究
- Structure Loss的Layers數量做烧蚀研究,明顯可以看到Layers的數量越多越像原圖。

- FreezeSG的部分也是同理。

参考文献
[arxiv][arxiv]
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/21/%e7%94%a8%e4%ba%8e%e5%8d%a1%e9%80%9a%e4%ba%ba%e8%84%b8%e7%94%9f%e6%88%90%e7%9a%84%e5%be%ae%e8%b0%83stylegan2%e7%ae%97%e6%b3%95/
