
作者|Sakshi Butala
编译|VK
来源|Towards Data Science

在本文中,我将向你展示如何使用卷积神经网络(CNNs)构建字母识别系统,并使用anvil.works部署。在本文的最后,你将能够创建上面所示系统。
目录
-
卷积神经网络
-
CNN实施
-
Anvil集成
卷积神经网络
让我们从理解什么是卷积神经网络开始。卷积神经网络(CNN)是一种广泛应用于图像识别和分类的神经网络。
cnn是多层感知器的正则化版本。多层感知器通常是指全连接网络,即一层中的每个神经元都与下一层的所有神经元相连。
CNN由以下层组成:
卷积层:一个大小为3X3或5X5的“核”被传递到图像上,并计算原始像素值与内核中定义的权重的点积。然后,该矩阵通过一个激活函数“ReLu”,该函数将矩阵中的每个负值转换为零。
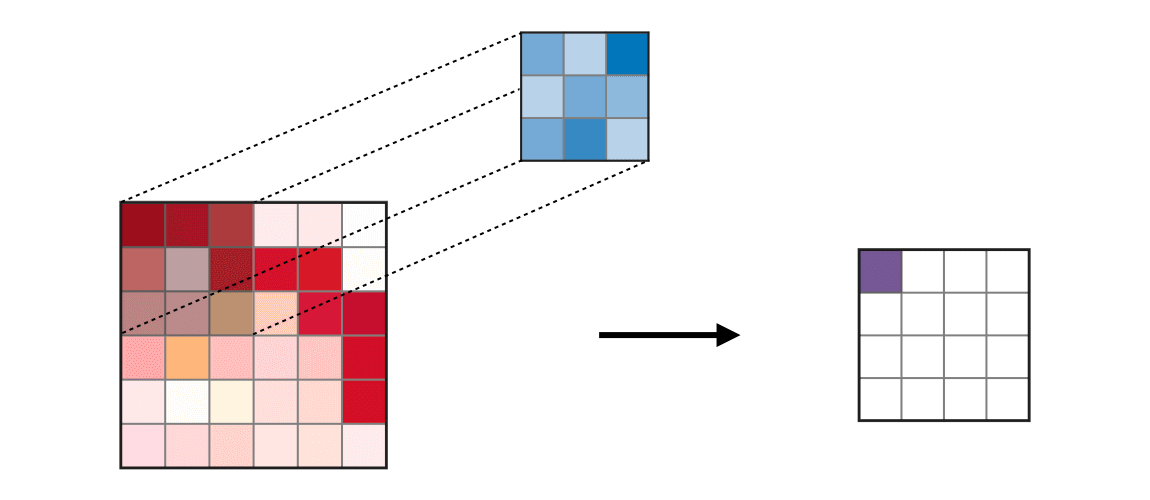
池化层:“池化矩阵”的大小有2X2或4X4,通过池化减小矩阵的大小,从而只突出图像的重要特征。
共有两种类型的池操作:
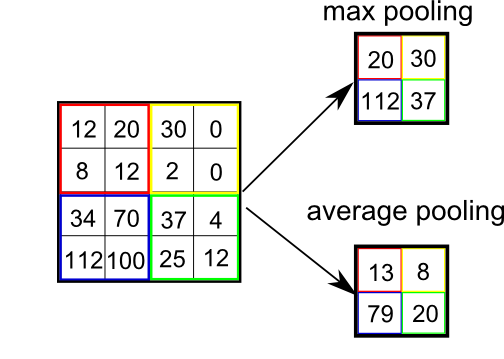
- 最大池是一种池类型,池化矩阵中存在的最大值被放入最终矩阵中。
- 平均池(Average Pooling)是一种池类型,其中计算池化矩阵中所有值的平均值并将其放入最终矩阵中。
注意:CNN架构中可以有多个卷积层和池层的组合,以提高其性能。
全连接层:最后的矩阵被展平成一维向量。然后将该向量输入神经网络。最后,输出层是附加到图像上的不同标签(例如字母a、b、c)的概率列表。最高概率的标签是分类器的输出。

CNN实现
让我们通过导入Jupyter Notebook中的库开始实现,如下所示:
import numpy as np
import matplotlib.pyplot as plt
from keras.preprocessing.image import ImageDataGenerator
from keras.preprocessing import image
import keras
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Activation
import os
import pickle然后,让我们从a到z导入包含图像的2个数据集,以训练和测试我们的模型。你可以从下面链接的GitHub存储库下载数据集。
链接:https://github.com/sakshibutala/CNN_AlphabetRecognition
train_datagen = ImageDataGenerator(rescale = 1./255,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True)
test_datagen = ImageDataGenerator(rescale = 1./255)
train_generator = train_datagen.flow_from_directory(
directory = 'Training',
target_size = (32,32),
batch_size = 32,
class_mode = 'categorical'
)
test_generator = test_datagen.flow_from_directory(
directory = 'Testing',
target_size = (32,32),
batch_size = 32,
class_mode = 'categorical'
)ImageDataGenerator生成一批张量图像数据,通过使用rescale进行缩放,将0-255范围内的RGB系数转换为0到1之间的目标值。
shear_range用于随机应用剪切变换。
zoom_range用于在图片内部随机缩放。
horizontal_flip用于水平随机翻转一半图像。
然后我们使用.flow_from_directory从目录中逐个导入图像,并对其应用ImageDataGenerator。
然后,我们将图像从原始大小转换为目标大小,并声明batch大小,它是指在一次迭代中使用的训练示例的数量。
然后我们将class_mode设置为category,这表示我们有多个类(a到z)可以预测。
接下来我们构建我们的CNN架构。
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape = (32,32,3), activation = 'relu'))
model.add(MaxPooling2D(pool_size = (2, 2)))
model.add(Conv2D(32, (3, 3), activation = 'relu'))
model.add(MaxPooling2D(pool_size = (2, 2)))
model.add(Flatten())
model.add(Dense(units = 128, activation = 'relu'))
model.add(Dense(units = 26, activation = 'softmax'))
model.compile(optimizer = 'adam', loss = 'categorical_crossentropy', metrics = ['accuracy'])
model.summary()我们首先创建一个Sequential模型,它允许我们使用.add函数逐层定义CNN架构。
我们首先在输入图像上添加一个带有32个3X3大小的滤波器(核)的卷积层,并将其通过“relu”激活函数。
然后我们使用大小为2X2的池执行MaxPooling操作。
然后再次重复这些层以提高模型的性能。
最后,我们将得到的矩阵展平并通过一个由128个节点组成的全连接层。然后将其连接到由26个节点组成的输出层,每个节点代表一个字母表。我们使用softmax激活将分数转换成一个正态化的概率分布,并选择概率最高的节点作为输出。
一旦我们的CNN架构被定义,我们就使用adam优化器编译模型。
最后,我们对模型进行训练。
model.fit_generator(train_generator,
steps_per_epoch = 16,
epochs = 3,
validation_data = test_generator,
validation_steps = 16)模型训练后的准确率为:93.42%
现在让我们来测试我们的模型。但是在我们这样做之前,我们需要定义一个函数,它给我们与结果相关联的字母表。
def get_result(result):
if result[0][0] == 1:
return('a')
elif result[0][1] == 1:
return ('b')
elif result[0][2] == 1:
return ('c')
elif result[0][3] == 1:
return ('d')
elif result[0][4] == 1:
return ('e')
elif result[0][5] == 1:
return ('f')
elif result[0][6] == 1:
return ('g')
elif result[0][7] == 1:
return ('h')
elif result[0][8] == 1:
return ('i')
elif result[0][9] == 1:
return ('j')
elif result[0][10] == 1:
return ('k')
elif result[0][11] == 1:
return ('l')
elif result[0][12] == 1:
return ('m')
elif result[0][13] == 1:
return ('n')
elif result[0][14] == 1:
return ('o')
elif result[0][15] == 1:
return ('p')
elif result[0][16] == 1:
return ('q')
elif result[0][17] == 1:
return ('r')
elif result[0][18] == 1:
return ('s')
elif result[0][19] == 1:
return ('t')
elif result[0][20] == 1:
return ('u')
elif result[0][21] == 1:
return ('v')
elif result[0][22] == 1:
return ('w')
elif result[0][23] == 1:
return ('x')
elif result[0][24] == 1:
return ('y')
elif result[0][25] == 1:
return ('z')最后,让我们测试一下我们的模型:
filename = r'Testing\e\25.png'
test_image = image.load_img(filename, target_size = (32,32))
plt.imshow(test_image)
test_image = image.img_to_array(test_image)
test_image = np.expand_dims(test_image, axis = 0)
result = model.predict(test_image)
result = get_result(result)
print ('Predicted Alphabet is: {}'.format(result))该模型正确地预测了输入图像的字母,结果为“e”。
Anvil集成
Anvil是一个允许我们使用python构建全栈web应用程序的平台。它使我们更容易将机器学习模型从Jupyter Notebook转换成web应用程序。
让我们首先在anvil上创建一个帐户。完成后,用material design创建一个新的空白应用程序。
查看此链接,了解如何使用anvil的逐步教程:https://anvil.works/learn
右边的工具箱包含所有可以拖到网站上的组件。
所需组件:
-
2个标签(标题和子标题)
-
图像(显示输入图像)
-
FileLoader(上传输入图像)
-
突出显示按钮(用于预测结果)
-
标签(查看结果)
拖放这些组件并根据你的要求排列它们。
要添加标题和副标题,请在右侧的“属性”部分选择标签和,然后转到名为“文本”的选项,如下所示(以红色突出显示),然后键入标题/副标题。
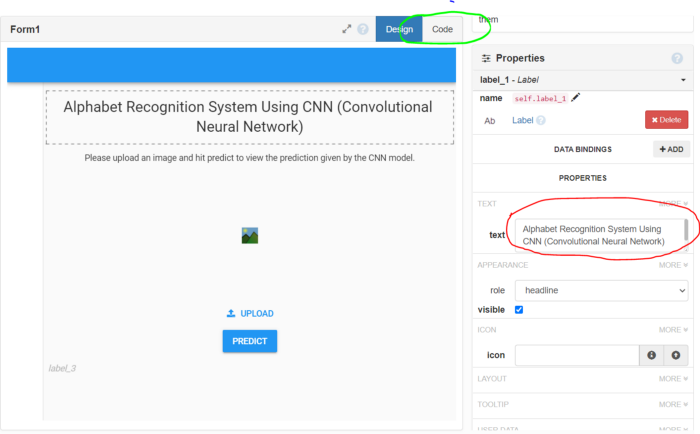
完成用户界面后,进入上面所示的代码部分(以绿色突出显示)并创建一个新函数,如下所示
def primary_color_1_click(self, **event_args):
file = self.file_loader_1.file
self.image_1.source = file
result = anvil.server.call('model_run',file)
self.label_3.text = result
pass当我们按下“PREDICT”按钮时,将执行此函数。它将获取从文件加载程序上传的输入图像并将其传递到Jupyter Notebook的“model_run”函数。此函数将返回预测字母。
现在要做的就是把我们的anvil网站连接到Jupyter Notebook。
这需要执行以下两个步骤:
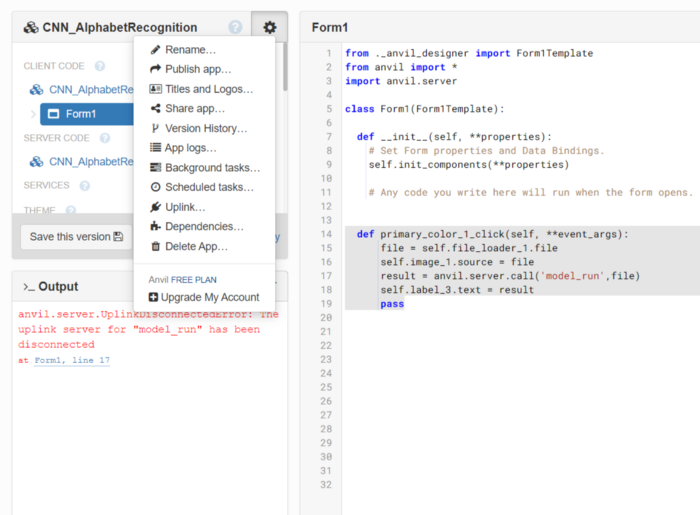
- 导入Anvil上行链路(uplink)密钥:单击设置按钮,然后单击上行链路,单击启用上行链路密钥并复制密钥。
在Jupyter Notebook内粘贴以下内容:
import anvil.server
import anvil.media
anvil.server.connect("paste your anvil uplink key here")-
创建一个“model_run”函数来预测上传到网站中的图像。
@anvil.server.callable def model_run(path): with anvil.media.TempFile(path) as filename: test_image = image.load_img(filename, target_size = (32,32)) test_image = image.img_to_array(test_image) test_image = np.expand_dims(test_image, axis = 0) result = model.predict(test_image) result = get_result(result) return ('Predicted Alphabet is: {}'.format(result))
现在你可以回到anvil,点击run按钮,字母识别系统就完全完成了。
你可以在我的GitHub存储库中找到源代码和数据集:https://github.com/sakshibutala/CNN_AlphabetRecognition。
引用
- Convolutional Neural Network Tutorial: From Basic to Advanced – MissingLink.ai
- CS 230 – Convolutional Neural Networks Cheatsheet
- Keras documentation: Image data preprocessing
原文链接:https://towardsdatascience.com/building-and-deploying-an-alphabet-recognition-system-7ab59654c676
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/10/19/%e6%9e%84%e5%bb%ba%e5%92%8c%e9%83%a8%e7%bd%b2%e5%ad%97%e6%af%8d%e8%af%86%e5%88%ab%e7%b3%bb%e7%bb%9f/
