
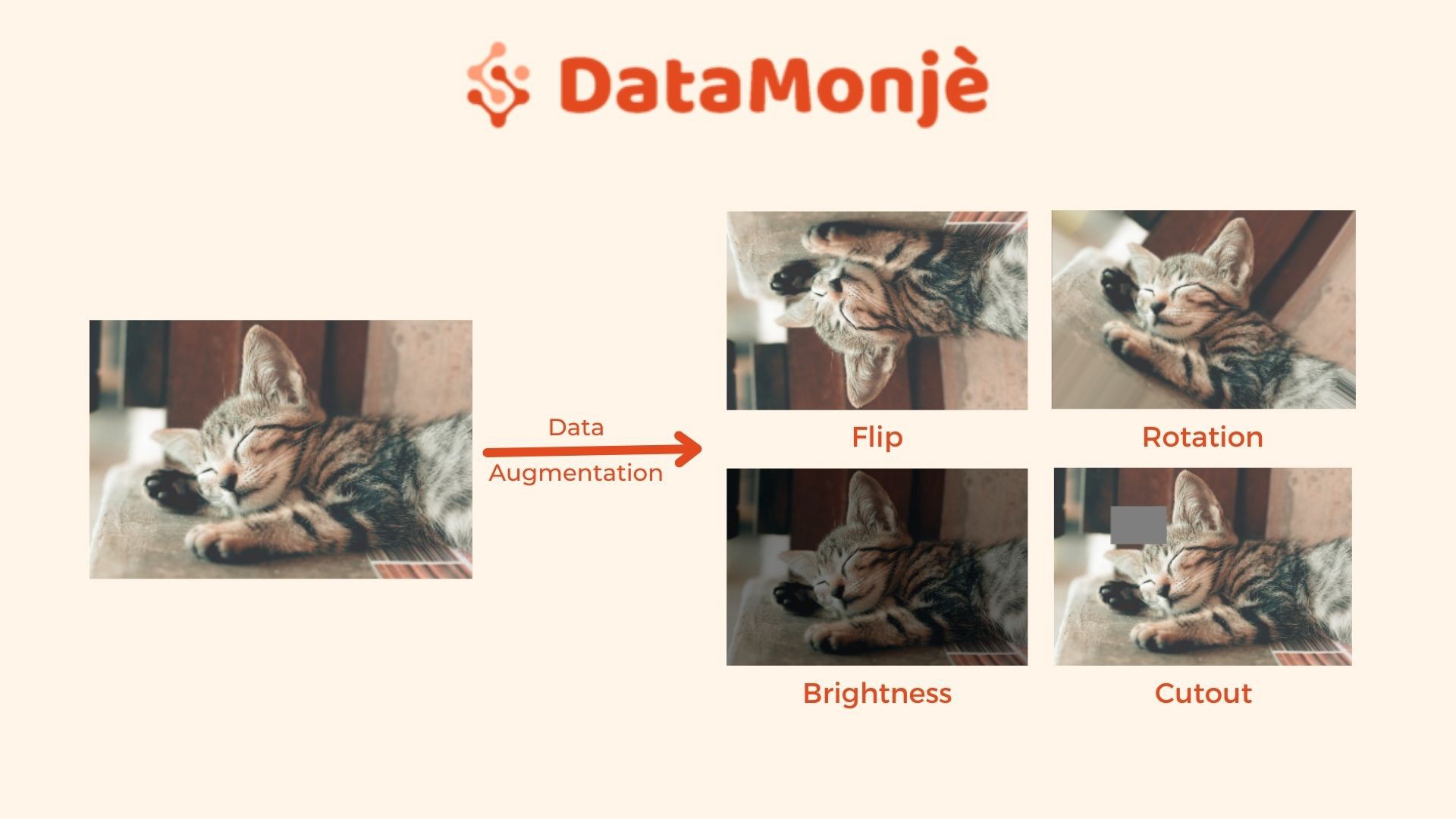
图像增强是一种工程解决方案,通过将标准图像处理方法应用于现有图像来创建新的图像集。
当训练数据集较小时,该解决方案对于神经网络或CNN最有用。虽然,图像增强也用于大数据集,作为一种正则化技术来建立广义或稳健的模型。
深度学习算法之所以强大,并不仅仅是因为它们能够模仿人脑。它们之所以强大,也是因为它们有能力凭借更多的数据蓬勃发展。事实上,它们需要大量数据才能提供可观的性能。
使用较小的数据集不太可能实现高性能。这里,当我们有小的图像数据来训练算法时,图像数据增强技术就派上用场了。
图像增强技术使用以下方法从现有图像集创建不同的图像变体:
- 图像翻转
- 旋转
- 缩放
- 高度和宽度移动
- 透视和倾斜
- 照明变换
如前所述,深度神经网络在处理大量数据时效果最好。数据量加快了性能,如下图所示。
这里,利用图像增强,我们可以通过组合上述多个变换来创建许多图像变体。
如果需要,您可以从每个图像创建20个、25个、30个或更多图像变体。因此,它满足了对相当数量数据的需求,因为您可以使用扩充技术将数据集扩展30倍或更多(在某种意义上)。
作为正则化技术的图像数据增强
除了数据集缩放,图像增强可以被认为是一种正则化方法。
需要经过训练的算法才能很好地处理不可见的真实数据。与训练集中的图像相比,在实时环境中获得的图像可能是疯狂的。
这些真实世界的图像具有不同的照明条件、帧位置、感兴趣对象的大小、透视等。
为了使算法学习更稳健,我们可以在训练时使用这些增强。
这样,最终的模型将能够得到更多的推广。即使数据集很大,我也更喜欢在大多数情况下使用扩充。
我们在这篇博客中谈论的图像放大技术是什么?
在这里,当我们讨论数据增强时,我们不会创建新的图像并将其保存到存储中,这也可以使用OpenCV库来实现。
类似OpenCV的库将有助于增加存储中的图像数量,但是使用内存中的图像增强技术可以获得类似的模型性能。
毫无疑问,物理图像增强(增强图像生成并存储在磁盘上)为图像处理和操作提供了更大的灵活性,但虚拟或内存中的图像增强仅足以训练模型。
内存图像增强从存储中获取图像,并在将图像送入神经网络之前实时修改图像,同时保持原始图像不变。
该代码基于Kera库的ImageDataGenerator类。在介绍了所有这些技术之后,我们还将介绍TensorFlow用于图像增强的预处理实验层和FAST AI的图像数据增强功能的代码。
阅读关于图像增强代码的深入博客(其中还包括自定义增强)Read an In-depth blog about image augmentation code (it also includes custom augmentations)
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/12/%e6%b7%b1%e5%ba%a6%e5%ad%a6%e4%b9%a0%e4%b8%ad%e7%9a%84%e5%9b%be%e5%83%8f%e5%a2%9e%e5%bc%ba%e7%ae%80%e4%bb%8b/
