
作者|Chien Vu
编译|Flin
来源|towardsdatascience

背景与挑战📋
在现代深度学习算法中,对未标记数据的手工标注是其主要局限性之一。为了训练一个好的模型,我们通常需要准备大量的标记数据。在少数类和数据的情况下,我们可以使用带有标签的公共数据集的预训练模型,并使用你的数据微调最后几层即可。
但是,当你的数据很大时(比如商店中的产品或人的脸,..),很容易遇到问题,并且仅通过几个可训练的层就很难学习模型。此外,未标记数据(例如,文档文本,Internet上的图像)的数量是不可数的。为任务标记所有标签几乎是不可能的,但是不使用它们绝对是一种浪费。
在这种情况下,使用新的数据集从头开始训练深度模型是一种选择,但是使用预先训练的深度模型时标记数据需要花费大量的时间和精力,这似乎不再有帮助。这就是自监督学习诞生的原因。这背后的想法很简单,主要有两个任务:
- 代理任务:深度模型将从没有注释的未标记数据中学习可归纳的表示,然后能够利用隐式信息自行生成监督信号。
- 下游任务:将针对监督学习任务(如分类和图像检索)对表示进行微调,标记数据的数量更少(标记数据的数量取决于模型的性能,具体取决于你的需求)
学习这些表示有很多不同的训练方法:
- 相对位置[1]:模型需要理解对象的空间上下文,以判断部件之间的相对位置;
- 拼图游戏[2]:模型需要将9个打乱的补丁放回原始位置;
- 着色[3]:模型已训练为对灰度输入图像进行着色;确切的任务是将该图像映射到量化的颜色值输出上的分布;
- 计数特征[4]:模型利用输入图像的特征计数关系,通过缩放和平铺来学习特征编码器;
- SimCLR[5]:该模型通过潜在空间中的对比损失来最大化同一样本不同增强视图之间的一致性,从而学习视觉输入的表示形式。
不过,我想介绍一种有趣的方法,它能够识别像人类一样的东西。人类学习的关键是通过比较相关实体和不同实体来获取新知识。因此,如果我们能够通过关系推理方法在自监督机器学习中应用相似的机制,这是一个非常重要的解决方案[6]。
关系推理范式基于一个关键的设计原则:使用关系网络作为未标记数据集的可学习函数,量化同一对象视图之间的关系(内部推理)和不同场景中不同对象之间的关系(交互推理)。通过在标准数据集(CIFAR-10、CIFAR-100、CIFAR-100-20、STL-10、tiny-ImageNet、SlimageNet)、学习进度和主干(两者)上的性能来评估通过关系推理在自监督机器学习中利用类似机制的可能性。
结果表明,关系推理方法在所有条件下都比最好的竞争对手平均高出14%的准确率,而最新的方法比此文(https://arxiv.org/abs/2006.05849) 的方法高出3%。
技术亮点📄

简单地说,关系推理只是一种方法论,它试图帮助学习者理解不同对象(思想)之间的关系,而不是单独地学习对象。这有助于学习者根据自己的差异轻松地辨别和记忆物体。
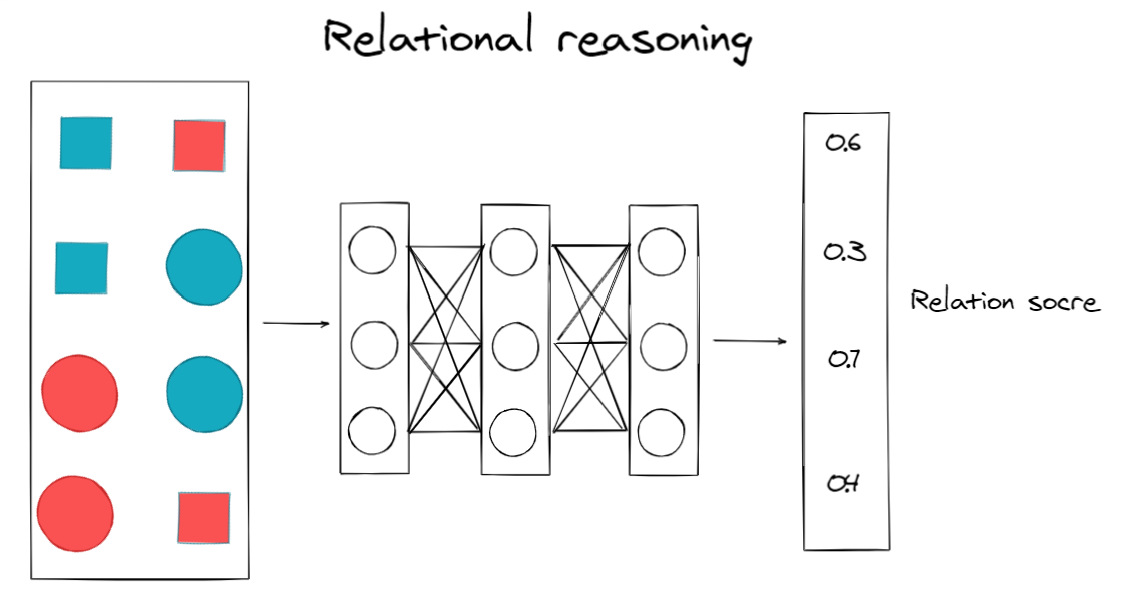
关系推理系统有两个主要组成部分:主干结构和关系头。在代理任务阶段使用关系头来支持底层神经网络主干学习未标记数据集中的有用表示,然后将其丢弃。在代理任务训练后,将主干结构用于后续任务,如分类或图像检索。
- 以前的工作:关注场景内的关系,意思是同一对象中的所有元素都属于同一场景(例如,篮子中的球);在标签数据集上进行训练,主要目标是关系。
- 新的方法:关注同一对象不同视图之间的关系(内部推理)和不同场景中不同对象之间的关系(交互推理);对未标记的数据使用关系推理,关系头是学习底层主干中有用表示的代理任务。
让我们来讨论一下关系推理系统某些部分的要点:
- 小批量增强
如前所述,本系统引入了内部推理和交互推理?为什么我们需要他们?当没有给出标签时,不可能创建一对相似和不同的对象。为了解决这个问题,采用了自举技术,形成了内部推理和交互推理,其中:
- 内部推理由对同一对象{A1; A2}(正对)(例如,同一篮球的不同视角)
- 交互推理包括耦合两个随机对象{A1; B1}(负对)(例如带随机球的篮球)
此外,还考虑使用随机增强函数(如几何变换、颜色失真)使场景间的推理更加复杂。这些增强功能的好处迫使学习者(骨干)注意更广泛的特征(例如颜色、尺寸、纹理等)之间的相关性。
例如,在{foot ball,basket ball}对中,颜色本身就可以很好地预测类。然而,随着颜色和形状大小的随机变化,学习者现在很难区分这两种颜色之间的差异。学习者必须考虑另一个特征,因此,它可以提供更好的表示。
- 度量学习
度量学习的目的是使用距离度量来接近相似输入(正输入)的表示,同时移开不同输入(负)的表示。然而,在关系推理中,度量学习有着根本的不同:

- 损失函数
学习目标是一个基于表示对的二元分类问题。因此,我们可以使用二进制交叉熵损失来最大化伯努利对数似然,其中关系分数y表示通过sigmoid激活函数诱导的表示成员的概率估计。
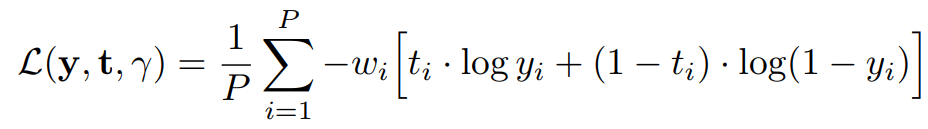
最后,本文[6]还提供了在标准数据集(CIFAR-10、CIFAR-100、CIFAR-100-20、STL-10、tiny-ImageNet、SlimageNet)、不同主干(浅层和深层)、相同的学习进度(epochs)上的关系推理结果。结果如下,欲了解更多信息,请查阅他的论文。
实验评估📊
在本文中,我想在公共图像数据集STL-10上重现关系推理系统。该数据集由10个类(飞机、鸟、汽车、猫、鹿、狗、马、猴、船、卡车)组成,颜色为96×96像素。
首先,我们需要导入一些重要的库
import torch
import torchvision
import torchvision.transforms as transforms
from PIL import Image
import math
import time
from torch.utils.data import DataLoader
from time import sleep
from tqdm import tqdm
import numpy as np
from fastprogress.fastprogress import master_bar, progress_bar
from torchvision import models
import matplotlib.pyplot as plt
from torchvision.utils import make_grid
%config InlineBackend.figure_format = 'svg'STL-10数据集包含1300个标记图像(500个用于训练,800个用于测试)。然而,它也包括100000个未标记的图像,这些图像来自相似但更广泛的分布。例如,除了标签集中的动物外,它还包含其他类型的动物(熊、兔子等)和车辆(火车、公共汽车等)

然后根据作者的建议创建关系推理类
class RelationalReasoning(torch.nn.Module):
"""自监督关系推理。
方法的基本实现,它使用
“cat”聚合函数(最有效),
可与任何主干一起使用。
"""
def __init__(self, backbone, feature_size=64):
super(RelationalReasoning, self).__init__()
self.backbone = backbone.to(device)
self.relation_head = torch.nn.Sequential(
torch.nn.Linear(feature_size*2, 256),
torch.nn.BatchNorm1d(256),
torch.nn.LeakyReLU(),
torch.nn.Linear(256, 1)).to(device)
def aggregate(self, features, K):
relation_pairs_list = list()
targets_list = list()
size = int(features.shape[0] / K)
shifts_counter=1
for index_1 in range(0, size*K, size):
for index_2 in range(index_1+size, size*K, size):
# 默认情况下使用“cat”聚合函数
pos_pair = torch.cat([features[index_1:index_1+size],
features[index_2:index_2+size]], 1)
# 通过滚动小批无碰撞的洗牌(负)
neg_pair = torch.cat([
features[index_1:index_1+size],
torch.roll(features[index_2:index_2+size],
shifts=shifts_counter, dims=0)], 1)
relation_pairs_list.append(pos_pair)
relation_pairs_list.append(neg_pair)
targets_list.append(torch.ones(size, dtype=torch.float32))
targets_list.append(torch.zeros(size, dtype=torch.float32))
shifts_counter+=1
if(shifts_counter>=size):
shifts_counter=1 # avoid identity pairs
relation_pairs = torch.cat(relation_pairs_list, 0)
targets = torch.cat(targets_list, 0)
return relation_pairs.to(device), targets.to(device)
def train(self, tot_epochs, train_loader):
optimizer = torch.optim.Adam([
{'params': self.backbone.parameters()},
{'params': self.relation_head.parameters()}])
BCE = torch.nn.BCEWithLogitsLoss()
self.backbone.train()
self.relation_head.train()
mb = master_bar(range(1, tot_epochs+1))
for epoch in mb:
# 实际目标被丢弃(无监督)
train_loss = 0
accuracy_list = list()
for data_augmented, _ in progress_bar(train_loader, parent=mb):
K = len(data_augmented) # tot augmentations
x = torch.cat(data_augmented, 0).to(device)
optimizer.zero_grad()
# 前向传播(主干)
features = self.backbone(x)
# 聚合函数
relation_pairs, targets = self.aggregate(features, K)
# 前向传播 (关系头)
score = self.relation_head(relation_pairs).squeeze()
# 交叉熵损失与向后传播
loss = BCE(score, targets)
loss.backward()
optimizer.step()
train_loss += loss.item()*K
predicted = torch.round(torch.sigmoid(score))
correct = predicted.eq(targets.view_as(predicted)).sum()
accuracy = (correct / float(len(targets))).cpu().numpy()
accuracy_list.append(accuracy)
epoch_loss = train_loss / len(train_loader.sampler)
epoch_accuracy = sum(accuracy_list)/len(accuracy_list)*100
mb.write(f"Epoch [{epoch}/{tot_epochs}] - Accuracy: {epoch_accuracy:.2f}% - Loss: {epoch_loss:.4f}")为了比较关系推理方法在浅层模型和深层模型上的性能,我们将创建一个浅层模型(Conv4),并使用深层模型的结构(Resnet34)。
backbone = Conv4() # 浅层模型
backbone = models.resnet34(pretrained = False) # 深层模型根据作者的建议,设置了一些超参数和增强策略。我们将在未标记的STL-10数据集上用关系头训练主干。
# 模拟的超参数
K = 16 # tot augmentations, 论文中 K=32
batch_size = 64 # 论文中使用64
tot_epochs = 10 # 论文中使用200
feature_size = 64 # Conv4 主干的单元数
feature_size = 1000 # Resnet34 主干的单元数backbone
# 扩充策略
normalize = transforms.Normalize(mean=[0.4406, 0.4273, 0.3858],
std=[0.2687, 0.2613, 0.2685])
color_jitter = transforms.ColorJitter(brightness=0.8, contrast=0.8,
saturation=0.8, hue=0.2)
rnd_color_jitter = transforms.RandomApply([color_jitter], p=0.8)
rnd_gray = transforms.RandomGrayscale(p=0.2)
rnd_rcrop = transforms.RandomResizedCrop(size=96, scale=(0.08, 1.0),
interpolation=2)
rnd_hflip = transforms.RandomHorizontalFlip(p=0.5)
train_transform = transforms.Compose([rnd_rcrop, rnd_hflip,
rnd_color_jitter, rnd_gray,
transforms.ToTensor(), normalize])
# 加载到数据加载器
torch.manual_seed(1)
torch.cuda.manual_seed(1)
train_set = MultiSTL10(K=K, root='data', split='unlabeled', transform=train_transform, download=True)
train_loader = DataLoader(train_set,batch_size=batch_size, shuffle=True,num_workers=2, pin_memory=True)
到目前为止,我们已经创造了训练我们模型所需的一切。现在我们将在10个时期和16个增强图像(K)中训练主干和关系头模型,使用1个GPU Tesla P100-PCIE-16GB在浅层模型(Conv4)上花费4个小时,在深层模型(Resnet34)上花费6个小时(你可以自由地更改时期数以及另一个超参数以获得更好的结果)
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
backbone.to(device)
model = RelationalReasoning(backbone, feature_size)
model.train(tot_epochs=tot_epochs, train_loader=train_loader)
torch.save(model.backbone.state_dict(), 'model.tar')在训练了我们的主干模型之后,我们丢弃了关系头,只将主干用于下游任务。我们需要使用STL-10(500个图像)中的标记数据来微调我们的主干,并在测试集中测试最终的模型(800个图像)。训练和测试数据集将加载到Dataloader中,而无需进行扩充。
# set random seed
torch.manual_seed(1)
torch.cuda.manual_seed(1)
# no augmentations used for linear evaluation
transform_lineval = transforms.Compose([transforms.ToTensor(), normalize])
# Download STL10 labeled train and test dataset
train_set_lineval = torchvision.datasets.STL10('data', split='train', transform=transform_lineval)
test_set_lineval = torchvision.datasets.STL10('data', split='test', transform=transform_lineval)
# Load dataset in data loader
train_loader_lineval = DataLoader(train_set_lineval, batch_size=128, shuffle=True)
test_loader_lineval = DataLoader(test_set_lineval, batch_size=128, shuffle=False)我们将加载预训练的主干模型,并使用一个简单的线性模型将输出特性与数据集中的许多类连接起来。
# linear model
linear_layer = torch.nn.Linear(64, 10) # if backbone is Conv4
linear_layer = torch.nn.Linear(1000, 10) # if backbone is Resnet34
# defining a raw backbone model
backbone_lineval = Conv4() # Conv4
backbone_lineval = models.resnet34(pretrained = False) # Resnet34
# load model
checkpoint = torch.load('model.tar') # name of pretrain weight
backbone_lineval.load_state_dict(checkpoint)此时,只训练线性模型,冻结主干模型。首先,我们将看到微调Conv4的结果
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
optimizer = torch.optim.Adam(linear_layer.parameters())
CE = torch.nn.CrossEntropyLoss()
linear_layer.to(device)
linear_layer.train()
backbone_lineval.to(device)
backbone_lineval.eval()
print('Linear evaluation')
for epoch in range(20):
accuracy_list = list()
for i, (data, target) in enumerate(train_loader_lineval):
optimizer.zero_grad()
data = data.to(device)
target= target.to(device)
output = backbone_lineval(data).to(device).detach()
output = linear_layer(output)
loss = CE(output, target)
loss.backward()
optimizer.step()
# estimate the accuracy
prediction = output.argmax(-1)
correct = prediction.eq(target.view_as(prediction)).sum()
accuracy = (100.0 * correct / len(target))
accuracy_list.append(accuracy.item())
print('Epoch [{}] loss: {:.5f}; accuracy: {:.2f}%' \
.format(epoch+1, loss.item(), sum(accuracy_list)/len(accuracy_list)))Linear evaluation
Epoch [1] loss: 2.24857; accuracy: 14.77%
Epoch [2] loss: 2.23015; accuracy: 24.49%
Epoch [3] loss: 2.18529; accuracy: 32.46%
Epoch [4] loss: 2.24595; accuracy: 36.45%
Epoch [5] loss: 2.09482; accuracy: 42.46%
Epoch [6] loss: 2.11192; accuracy: 43.40%
Epoch [7] loss: 2.05064; accuracy: 47.29%
Epoch [8] loss: 2.03494; accuracy: 47.38%
Epoch [9] loss: 1.91709; accuracy: 47.46%
Epoch [10] loss: 1.99181; accuracy: 48.03%
Epoch [11] loss: 1.91527; accuracy: 48.28%
Epoch [12] loss: 1.93190; accuracy: 49.55%
Epoch [13] loss: 2.00492; accuracy: 49.71%
Epoch [14] loss: 1.85328; accuracy: 49.94%
Epoch [15] loss: 1.88910; accuracy: 49.86%
Epoch [16] loss: 1.88084; accuracy: 50.76%
Epoch [17] loss: 1.63443; accuracy: 50.74%
Epoch [18] loss: 1.76303; accuracy: 50.62%
Epoch [19] loss: 1.70486; accuracy: 51.46%
Epoch [20] loss: 1.61629; accuracy: 51.84%
然后检查测试集
accuracy_list = list()
for i, (data, target) in enumerate(test_loader_lineval):
data = data.to(device)
target= target.to(device)
output = backbone_lineval(data).detach()
output = linear_layer(output)
# estimate the accuracy
prediction = output.argmax(-1)
correct = prediction.eq(target.view_as(prediction)).sum()
accuracy = (100.0 * correct / len(target))
accuracy_list.append(accuracy.item())
print('Test accuracy: {:.2f}%'.format(sum(accuracy_list)/len(accuracy_list)))Test accuracy: 49.98%
Conv4在测试集上获得了49.98%的准确率,这意味着主干模型可以在未标记的数据集中学习有用的特征,只需在很少的时间段内进行微调就可以达到很好的效果。现在让我们检查深度模型的性能。
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
optimizer = torch.optim.Adam(linear_layer.parameters())
CE = torch.nn.CrossEntropyLoss()
linear_layer.to(device)
linear_layer.train()
backbone_lineval.to(device)
backbone_lineval.eval()
print('Linear evaluation')
for epoch in range(20):
accuracy_list = list()
for i, (data, target) in enumerate(train_loader_lineval):
optimizer.zero_grad()
data = data.to(device)
target= target.to(device)
output = backbone_lineval(data).to(device).detach()
output = linear_layer(output)
loss = CE(output, target)
loss.backward()
optimizer.step()
# estimate the accuracy
prediction = output.argmax(-1)
correct = prediction.eq(target.view_as(prediction)).sum()
accuracy = (100.0 * correct / len(target))
accuracy_list.append(accuracy.item())
print('Epoch [{}] loss: {:.5f}; accuracy: {:.2f}%' \
.format(epoch+1, loss.item(), sum(accuracy_list)/len(accuracy_list)))Linear evaluation
Epoch [1] loss: 2.68060; accuracy: 47.79%
Epoch [2] loss: 1.56714; accuracy: 58.34%
Epoch [3] loss: 1.18530; accuracy: 56.50%
Epoch [4] loss: 0.94784; accuracy: 57.91%
Epoch [5] loss: 1.48861; accuracy: 57.56%
Epoch [6] loss: 0.91673; accuracy: 57.87%
Epoch [7] loss: 0.90533; accuracy: 58.96%
Epoch [8] loss: 2.10333; accuracy: 57.40%
Epoch [9] loss: 1.58732; accuracy: 55.57%
Epoch [10] loss: 0.88780; accuracy: 57.79%
Epoch [11] loss: 0.93859; accuracy: 58.44%
Epoch [12] loss: 1.15898; accuracy: 57.32%
Epoch [13] loss: 1.25100; accuracy: 57.79%
Epoch [14] loss: 0.85337; accuracy: 59.06%
Epoch [15] loss: 1.62060; accuracy: 58.91%
Epoch [16] loss: 1.30841; accuracy: 58.95%
Epoch [17] loss: 0.27441; accuracy: 58.11%
Epoch [18] loss: 1.58133; accuracy: 58.73%
Epoch [19] loss: 0.76258; accuracy: 58.81%
Epoch [20] loss: 0.62280; accuracy: 58.50%
然后评估测试数据集
accuracy_list = list()
for i, (data, target) in enumerate(test_loader_lineval):
data = data.to(device)
target= target.to(device)
output = backbone_lineval(data).detach()
output = linear_layer(output)
# estimate the accuracy
prediction = output.argmax(-1)
correct = prediction.eq(target.view_as(prediction)).sum()
accuracy = (100.0 * correct / len(target))
accuracy_list.append(accuracy.item())
print('Test accuracy: {:.2f}%'.format(sum(accuracy_list)/len(accuracy_list)))Test accuracy: 55.38%
这是更好的,我们可以在测试集上获得55.38%的精度。本文的主要目的是重现和评估关系推理方法论,以指导模型识别无标签对象,因此,这些结果是非常有前途的。如果你觉得不满意,你可以通过改变超参数来自由地做实验,比如增加数量,时期,或者改变模型结构。
最后的想法📕
自监督关系推理在定量和定性两方面都是有效的,并且具有从浅到深的不同大小的主干。通过比较学习到的表示可以很容易地从一个领域转移到另一个领域,它们具有细粒度和紧凑性,这可能是由于精度和扩充次数之间的相关性。在关系推理中,根据作者的实验,扩充的数量对对象簇的质量有着主要的影响[4]。自监督学习在许多方面都有很强的潜力成为机器学习的未来。
参考文献
[1] Carl Doersch et. al, Unsupervised Visual Representation Learning by Context Prediction, 2015.
[2] Mehdi Noroozi et. al, Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles, 2017.
[3] Zhang et. al, Colorful Image Colorization, 2016.
[4] Mehdi Noroozi et. al, Representation Learning by Learning to Count, 2017.
[5] Ting Chen et. al, A Simple Framework for Contrastive Learning of Visual Representations, 2020.
[6] Massimiliano Patacchiola et. al, Self-Supervised Relational Reasoning for
Representation Learning, 2020.
[7] Adam Santoro et. al, Relational recurrent neural networks, 2018.
原文链接:https://towardsdatascience.com/train-without-labeling-data-using-self-supervised-learning-by-relational-reasoning-b0298ad818f9
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/10/19/%e5%9f%ba%e4%ba%8e%e5%85%b3%e7%b3%bb%e6%8e%a8%e7%90%86%e7%9a%84%e8%87%aa%e7%9b%91%e7%9d%a3%e5%ad%a6%e4%b9%a0%e6%97%a0%e6%a0%87%e8%ae%b0%e8%ae%ad%e7%bb%83/
