
本文是全系列中第1 / 24篇:Pytorch 专栏
- 使用PyTorch建立你的第一个文本分类模型
- PyTorch专栏(十八): 词嵌入,编码形式的词汇语义
- PyTorch 系列教程之空间变换器网络
- PyTorch高级实战教程: 基于BI-LSTM CRF实现命名实体识别和中文分词
- PyTorch专栏(十七): 使用PyTorch进行深度学习
- PyTorch ImageNet 基于预训练六大常用图片分类模型的实战
- 从零开始学PyTorch:一文学会线性回归、逻辑回归及图像分类
- PyTorch专栏(十六):使用字符级RNN进行名字分类
- PyTorch专栏(八):微调基于torchvision 0.3的目标检测模型
- PyTorch 60 分钟入门教程:数据并行处理
- 手把手带你使用字符级RNN生成名字 | PyTorch
- PyTorch专栏(七):模型保存与加载那些事
- Pytorch入门演练
- 聊天机器人实战教程 | PyTorch专栏
- PyTorch专栏(六): 混合前端的seq2seq模型部署
- Python 实现基于深度强化学习算法实现的一个简单自动驾驶 AI 【PyTorch】
- PyTorch 中使用深度学习(CNN和LSTM)的自动图像描述
- PyTorch专栏(十三):使用ONNX将模型转移至Caffe2和移动端
- PyTorch数据可视化工具Visdom(下)
- PyTorch专栏(二十):高级:制定动态决策和BI-LSTM CRF
- PyTorch专栏(十二):一文综述图像对抗算法
- PyTorch中文版官方教程来啦(附下载)
- PyTorch专栏(十九):序列模型和长短句记忆(LSTM)模型 | 文末开奖
- 使用 PyTorch 进行 风格迁移(Neural-Transfer)
概述
- 学习如何使用PyTorch执行文本分类
- 理解解决文本分类时所涉及的要点
- 学习使用包填充(Pack Padding)特性
介绍
我总是使用最先进的架构来在一些比赛提交模型结果。得益于PyTorch、Keras和TensorFlow等深度学习框架,实现最先进的体系结构变得非常容易。这些框架提供了一种简单的方法来实现复杂的模型体系结构和算法,而只需要很少的概念知识和代码技能。简而言之,它们是数据科学社区的一座金矿!
在本文中,我们将使用PyTorch,它以其快速的计算能力而闻名。因此,在本文中,我们将介绍解决文本分类问题的关键点。然后我们将在PyTorch中实现第一个文本分类器!
目录
1. 为什么使用PyTorch进行文本分类?
– 处理词汇表外单词
– 处理可变长度序列
– 包装器和预训练模型
2. 理解问题
3. 实现文本分类
为什么使用PyTorch进行文本分类?
在深入研究技术概念之前,让我们先快速熟悉一下将要使用的框架——PyTorch。PyTorch的基本单位是张量,类似于python中的“numpy”数组。使用PyTorch有很多好处,但最重要的两个是:
– 动态网络——运行时架构的变化
– 跨gpu的分布式训练

我敢肯定你想知道——为什么我们要使用PyTorch来处理文本数据?让我们讨论一下PyTorch的一些令人难以置信的特性,这些特性使它不同于其他框架,特别是在处理文本数据时。
1. 处理词汇表外单词
文本分类模型根据固定的词汇量进行训练。但在推理过程中,我们可能会遇到一些词汇表中没有的词。这些词汇被称为词汇量外单词(Out of Vocabulary),大多数深度学习框架缺乏处理词汇量不足的能力。这是一个关键的问题,甚至可能导致信息的丢失。
为了处理词汇量不足的单词,PyTorch支持一个很好的功能,它用未知的token替换训练数据中的稀有单词。这反过来又帮助我们解决了词汇量不足的问题。
除了处理词汇之外,PyTorch还有一个可以处理可变长度序列的特性!
2. 处理可变长度序列
你听说过循环神经网络是如何处理可变长度序列的吗?有没有想过如何实现它?PyTorch提供了一个有用的特性“填充序列”(Packed Padding sequence),它实现了动态循环神经网络。
填充是在句首或句尾添加一个称为填充标记的额外标记的过程。由于每个句子中的单词数量不同,我们通过添加填充标记将可变长度的输入句子转换为具有相同长度的句子。
填充是必须的,因为大多数框架支持静态网络,即架构在整个模型训练过程中保持不变。虽然填充解决了可变长度序列的问题,但是这种思想还有另一个问题——体系结构现在像处理任何其他信息/数据一样处理这些填充标记。让我用一个简单的图表来解释一下
正如你在下图中所看到的,在生成输出时还使用了最后一个元素,即padding标记。这是由PyTorch中的填充序列来处理的。
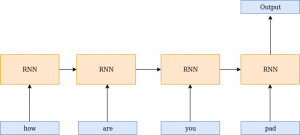
压缩填充会对填充标记忽略输入时间步。这些值不输入给循环神经网络,这帮助我们建立动态循环神经网络。
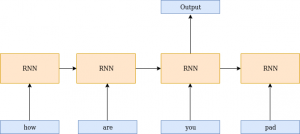
3.包装器和预训练模型
最新的模型架构状态正在为PyTorch框架发布。Hugging Face发布Transformers,其中提供超过32个自然语言理解生成的最新架构!
不仅如此,PyTorch还为文本到语音、对象检测等任务提供了预训练模型,这些任务可以在几行代码内执行。
不可思议,不是吗?这些是PyTorch的一些非常有用的特性。现在让我们使用PyTorch解决一个文本分类问题。
理解问题陈述
作为本文的一部分,我们将研究一个非常有趣的问题。
Quora希望在他们的平台上追踪不真诚的问题,以便让用户在分享知识的同时感到安全。在这种情况下,一个不真诚的问题被定义为一个旨在发表声明的问题,而不是寻找有用的答案。为了进一步分析这个问题,这里有一些特征可以表明一个特定的问题是不真诚的:
- 语气非中性
- 是贬低还是煽动性的
- 没有现实根据
- 使用性内容(乱伦、兽交、恋童癖)来达到令人震惊的效果,而不是寻求真正的答案
训练数据包括被询问的问题,以及一个表示是否被识别为不真诚的标记(target = 1)。标签包含一些噪音,即它们不能保证是完美的。我们的任务是识别某个问题是否“不真诚”。你可以从这里下载数据集。
https://drive.google.com/file/d/1fcip8PgsrX7m4AFgvUPLaac5pZ79mpwX/view?usp=drive_open
现在是使用PyTorch编写我们自己的文本分类模型的时候了。
实现文本分类
让我们首先导入构建模型所需的所有必要库。下面是我们将使用的包/库的简要概述
– Torch包用于定义张量和张量上的数学运算
– torchtext是PyTorch中的一个自然语言处理(NLP)库。这个库包含预处理文本的脚本和一些流行的NLP数据集的源。
#导入库
import torch
#处理数据
from torchtext import data
为了使结果可重复,我指定了种子值。由于深度学习模型在执行时由于其随机性可能会产生不同的结果,因此指定种子值是很重要的。
#产生同样的结果
SEED = 2019
#Torch
torch.manual_seed(SEED)
#Cuda 算法
torch.backends.cudnn.deterministic = True
预处理数据:
现在,让我们看看如何使用字段对象对文本进行预处理。字段对象有两种不同的类型——field和LabelField。让我们快速了解一下两者之间的区别
1. field:数据模块中的字段对象用于为数据集中的每一列指定预处理步骤。
2. LabelField: LabelField对象是Field对象的一个特例,它只用于分类任务。它的惟一用途是默认将unk_token和sequential设置为None。
在我们使用field之前,让我们看看field的不同参数和它们的用途。
field的参数:
1. Tokenize:指定标记句子的方法,即将句子分词。我正在使用spacy分词器,因为它使用了新的分词算法
2. Lower:将文本转换为小写
batch_first:输入和输出的第一个维度总是批处理大小
接下来,我们将创建一个元组列表,其中每个元组中的第一个值包含一个列名,第二个值是上面定义的字段对象。此外,我们将按照csv列的顺序排列每个元组,并指定为(None,None)以忽略csv文件中的列。
让我们只读需要的列-问题和标签
fields = [(None, None), ('text',TEXT),('label', LABEL)]
在下面的代码块中,我通过定义字段对象加载了自定义数据集。
#载入自定义数据集
training_data=data.TabularDataset(path = 'quora.csv',format = 'csv',fields = fields,skip_header = True)
print(vars(training_data.examples[0]))
现在,让我们将数据集分为训练和验证数据
import random
train_data, valid_data = training_data.split(split_ratio=0.3, random_state = random.seed(SEED))
准备输入和输出序列:
下一步是为文本构建词汇表,并将它们转换为整数序列。词汇表包含了整篇文章中出现的词汇。每个唯一的单词都有一个索引。下面列出了相同的参数
参数:
1. min_freq:忽略词汇表中频率小于指定频率的单词,并将其映射到未知标记。
2. 两个特殊的标记(称为unknown和padding)将被添加到词汇表中
– unknown标记用于处理词汇表中的单词
– padding标记用于生成相同长度的输入序列
让我们构建词汇表,并使用预训练好的嵌入来初始化单词。如果希望随机初始化嵌入,请忽略vectors参数。
#初始化glove embeddings
TEXT.build_vocab(train_data,min_freq=3,vectors = "glove.6B.100d")
LABEL.build_vocab(train_data)
print("Size of TEXT vocabulary:",len(TEXT.vocab))
print("Size of LABEL vocabulary:",len(LABEL.vocab))
print(TEXT.vocab.freqs.most_common(10))
print(TEXT.vocab.stoi)
现在我们准备批训练模型。BucketIterator以需要最小填充量的方式形成批。
#检查cuda是否可用
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#设置batch大小
BATCH_SIZE = 64
#载入迭代器
train_iterator, valid_iterator = data.BucketIterator.splits(
(train_data, valid_data),
batch_size = BATCH_SIZE,
sort_key = lambda x: len(x.text),
sort_within_batch=True,
device = device)
模型架构
现在是定义体系结构来解决二分类问题的时候了。torch中的神经网络模块是所有模型的基础模型。这意味着每个模型都必须是nn模块的子类。
我在这里定义了两个函数:init和forward。让我来解释一下这两个函数的用例
1. Init:每当创建类的实例时,都会自动调用Init函数。因此,它被称为构造函数。传递给类的参数由构造函数初始化。我们将定义将在模型中使用的所有层
2. Forward: Forward函数定义输入的前向传播。
最后,让我们详细了解用于构建体系结构的不同层及其参数
嵌入层:嵌入对于任何与NLP相关的任务都是非常重要的,因为它以向量格式表示一个单词。嵌入层创建一个查找表,其中每一行表示一个单词的嵌入。嵌入层将整数序列转换成向量表示。这里是嵌入层两个最重要的参数-
1. num_embeddings:字典中的单词数量
2. embedding_dim:单词的维度
LSTM: LSTM是RNN的一个变体,能够捕获长期依赖项。遵循你应该熟悉的LSTM的一些重要参数。以下是这一层的参数:
1. input_size:输入的维度
2. hidden_size:隐藏节点的数量
3. num_layers:要堆叠的层数
4. batch_first:如果为真,则输入和输出张量以(batch, seq, feature)的形式提供。
5. dropout:如果非零,则在除最后一层外的每一LSTM层的输出上引入一个dropout层,dropout概率等于dropout。默认值:0
6. bidirection:如果为真,则引入双向LSTM
线性层:线性层是指Dense层。这里的两个重要参数如下:
1. in_features:输入的特征数量
2. out_features:隐藏层的节点数量
包填充:如前所述,包填充用于定义动态循环神经网络。如果没有填充包,填充输入也由rnn处理,并返回填充元素的隐状态。这是一个非常棒的包装器,它不显示填充的输入。它只是忽略这些值并返回未填充元素的隐藏状态。
现在我们已经很好地理解了架构的所有块,让我们来看代码!
我将从定义架构的所有层开始:
import torch.nn as nn
class classifier(nn.Module):
#定义所有层
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers,
bidirectional, dropout):
super().__init__()
#embedding 层
self.embedding = nn.Embedding(vocab_size, embedding_dim)
#lstm 层
self.lstm = nn.LSTM(embedding_dim,
hidden_dim,
num_layers=n_layers,
bidirectional=bidirectional,
dropout=dropout,
batch_first=True)
#全连接层
self.fc = nn.Linear(hidden_dim * 2, output_dim)
#激活函数
self.act = nn.Sigmoid()
def forward(self, text, text_lengths):
#text = [batch size,sent_length]
embedded = self.embedding(text)
#embedded = [batch size, sent_len, emb dim]
packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, text_lengths,batch_first=True)
packed_output, (hidden, cell) = self.lstm(packed_embedded)
#hidden = [batch size, num layers * num directions,hid dim]
#cell = [batch size, num layers * num directions,hid dim]
#连接最后的正向和反向隐状态
hidden = torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim = 1)
#hidden = [batch size, hid dim * num directions]
dense_outputs=self.fc(hidden)
#激活
outputs=self.act(dense_outputs)
return outputs
下一步是定义超参数并实例化模型。下面是相同的代码块:
#定义超参数
size_of_vocab = len(TEXT.vocab)
embedding_dim = 100
num_hidden_nodes = 32
num_output_nodes = 1
num_layers = 2
bidirection = True
dropout = 0.2
#实例化模型
model = classifier(size_of_vocab, embedding_dim, num_hidden_nodes,num_output_nodes, num_layers,
bidirectional = True, dropout = dropout)
让我们看看模型摘要,并使用预先训练好的嵌入来初始化嵌入层
#模型体系
print(model)
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
#初始化预训练embedding
pretrained_embeddings = TEXT.vocab.vectors
model.embedding.weight.data.copy_(pretrained_embeddings)
print(pretrained_embeddings.shape)
这里我已经为模型定义了优化器,损失和度量:
import torch.optim as optim
#定义优化器和损失
optimizer = optim.Adam(model.parameters())
criterion = nn.BCELoss()
#定义度量
def binary_accuracy(preds, y):
#四舍五入到最接近的整数
rounded_preds = torch.round(preds)
correct = (rounded_preds == y).float()
acc = correct.sum() / len(correct)
return acc
#如果cuda可用
model = model.to(device)
criterion = criterion.to(device)
构建模型分为两个阶段:
1. 训练阶段:model.train()将模型设置在训练阶段,并激活dropout层。
2. 推理阶段:model.eval()将模型设置在评估阶段,并停用dropout层。
下面是定义用于训练模型的函数的代码块
def train(model, iterator, optimizer, criterion):
#初始化
epoch_loss = 0
epoch_acc = 0
#设置为训练模式
model.train()
for batch in iterator:
#在每一个batch后设置0梯度
optimizer.zero_grad()
text, text_lengths = batch.text
#转换成一维张量
predictions = model(text, text_lengths).squeeze()
#计算损失
loss = criterion(predictions, batch.label)
#计算二分类精度
acc = binary_accuracy(predictions, batch.label)
#反向传播损耗并计算梯度
loss.backward()
#更新权重
optimizer.step()
#损失和精度
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
我们有一个函数来训练模型,但我们也需要一个函数来评估模型。让我们这样做
def evaluate(model, iterator, criterion):
#初始化
epoch_loss = 0
epoch_acc = 0
#停用dropout层
model.eval()
#取消autograd
with torch.no_grad():
for batch in iterator:
text, text_lengths = batch.text
#转换为一维张量
predictions = model(text, text_lengths).squeeze()
#计算损失和准确性
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
#跟踪损失和准确性
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
最后,我们将对模型进行若干个epoch的训练,并在每个epoch保存最佳模型。
N_EPOCHS = 5
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
#训练模型
train_loss, train_acc = train(model, train_iterator, optimizer, criterion)
#评估模型
valid_loss, valid_acc = evaluate(model, valid_iterator, criterion)
#保存最佳模型
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'saved_weights.pt')
print(f'tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%')
print(f't Val. Loss: {valid_loss:.3f} | Val. Acc: {valid_acc*100:.2f}%')
让我们加载最佳模型并定义接受用户定义的输入并进行预测的推理函数
#载入权重
path='/content/saved_weights.pt'
model.load_state_dict(torch.load(path));
model.eval();
#推理
import spacy
nlp = spacy.load('en')
def predict(model, sentence):
tokenized = [tok.text for tok in nlp.tokenizer(sentence)] #标记句子
indexed = [TEXT.vocab.stoi[t] for t in tokenized] #转换为整数序列
length = [len(indexed)]
tensor = torch.LongTensor(indexed).to(device) #转换为tensor
tensor = tensor.unsqueeze(1).T
length_tensor = torch.LongTensor(length) #转换为tensor
prediction = model(tensor, length_tensor) #预测
return prediction.item()
让我们用这个模型来预测几个问题:
#作出预测
predict(model, "Are there any sports that you don't like?")
#不真诚的问题
predict(model, "Why Indian girls go crazy about marrying Shri. Rahul Gandhi ji?")
结尾
我们已经看到了如何在PyTorch中构建自己的文本分类模型,并了解了包填充的重要性。
你可以尝试使用调试LSTM模型的超参数,并尝试进一步提高准确性。一些要调优的超参数可以是LSTM层的数量、每个LSTM单元中的隐藏单元的数量等等。
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/02/20/%e4%bd%bf%e7%94%a8pytorch%e5%bb%ba%e7%ab%8b%e4%bd%a0%e7%9a%84%e7%ac%ac%e4%b8%80%e4%b8%aa%e6%96%87%e6%9c%ac%e5%88%86%e7%b1%bb%e6%a8%a1%e5%9e%8b/

评论列表(4条)
text, text_lengths = batch.text 请问这里是如何获取得到lengths的,运行代码遇到了错误,谢谢
你好,有完整的报错截图吗,尽量详细一点。
你可以添加我的微信: tensorflownews
你好,也可以参考英文原文有 github 开源代码。